MicroNet: Improving Image Recognition with Extremely Low FLOPs--Yunsheng Li
- 0、摘要
- 1、引入
- 2、相关工作
- 3、Micro-Factorized Convolution
-
- 3.1 Micro-Factorized Pointwise Convolution
- 3.2 Micro-Factorized Depthwise Convolution
- 4、Dynamic Shift-Max
-
- 4.1 通道打乱
- 4.2 两组权重怎么来?
- 4.3 融合
- 5、MicroNet
-
- 5.1 Micro-Blocks
- 5.2 结构
- 5.3 之前的相关工作(直接翻译的)
- 6、实验
-
- 6.1 ImageNet Classification
-
- 6.1.1 消融实验
- 6.1.2 与先前的网络比较
- 6.1.3 推理延迟
- 6.1.4 讨论
- 7、总结
本文重点解决在极低FLOPs条件下设计准确率更高的网络,通过Micro-Factorized Convolution在保证节点连接性条件下减低计算量,通过Dynamic Shift-Max激活函数加强通道间的联系,改善非线性,以弥补网络不能太深所带来的缺陷。
通过实验看出MicroNet比MobileNetV3等轻量化网络不经拥有更低的FLOPs,而且在精度上的提升非常巨大。
0、摘要
面临的问题:
本文旨在解决在极低计算量条件下性能下降的问题(比如在ImageNet分类使用5MFLOPs)。
依据:
我们发现sparse connectivity(稀疏连通)和dynamic activation function(动态激活函数)对提高精度是有效的,前者避免了网络宽度的显著减小,后者缓解了网络深度减小的不利影响。
解决办法:
所以我们提出了micro-factorized convolution(微因式分解卷积),它将卷积矩阵分解成低阶矩阵,将稀疏连通性融入卷积中。我们还提出了一种新的动态激活函数,称为Dynamic Shift Max,通过最大限度地利用输入特征映射与其圆形通道位移之间地多个动态融合来改善非线性(“via maxing out multiple dynamic fusions between an input feature map and its circular channel shift”)。
效果:
基于这两个新算子,我们得到了一类称为MicroNet的网络,该网络在低FLOP领域下取得了显著的性能提升,比如在12MFLOPs的约束下,MicroNet在ImageNet分类上达到了59.4%的Top1准确率,比MobileNetV3高出了9.6%,代码开源在:MicroNet
1、引入
最近在CNN方面的进展将ImageNet分类的计算成本从3.8G FLOPs降低了两个数量级到约40M FLOPs(比如MobileNet、ShuffleNet),同时性能下降也比较合理(轻量级在精度上肯定有下降,但是能够接受)。
但是当进一步降低计算成本是,性能就出现了显著下降,以MobileNetV3为例,当计算成本从44M下降到21M和12M MAdds时,Top1准确率分别从65.4%下降到58.0%和49.8%
在本文中,我们旨在从21M降低到4M MAdds这样的极端低FLOP条件下提高精度,这标志着计算成本降低到了新的数量级(原来是G到40M,现在从40M到4M)
考虑到2.7M Madds计算资源被stem layer层(1个输入3通道,输出8通道,stride=2的3x3卷积,且作用在112x112的网格上)消耗了,设计一个极低的预算计算成本(4M~21M FLOPs)的网络非常具有挑战性。剩余的计算资源太有限,无法设计有效分类所需要的卷积层和1000类分类器。
如图1,如MobileNet或ShuffleNet等普通的减少网络跨度或深度的策略,会导致严重的性能下降。

注意,我们的重点是设计新的操作符上,输入分辨率固定为224x224,预算为4M FLOPs。
本文从node connectivity(节点连通性)和与网络宽度和深度相关的non-linearity(非线性)两个角度来处理极低FLOPs。首先我们证明了降低节点连通性来扩大网络宽度对于给定计算预算是一个很好的权衡。其次我们依靠改进的层非线性来补偿减小的网络深度。这两个因素促使设计更高效的卷积和激活函数。
(总之就是,计算资源预算低,所以网络不能太宽和太深,但是通过高效的卷积可以在控制计算资源时扩宽宽度,通过激活函数弥补网路太浅的缺陷)
对于高效卷积,我们提出了一种为MF-Conv (Micro-Factorized convolution)将逐点卷积(pointwise conv)分解为两组卷积层,其中分组数量G是根据通道数C自适应计算得到:
G = C / R G=\sqrt{C/R} G=C/R
R R R代表通道压缩率,我们可以通过该超参数来控制想要压缩的倍数,而分组数根据C和R自适应计算出分组数。如3.1节分析的,对于给定的计算成本,该公式在通道数量和节点连接性之间实现了良好的折衷。
对于非线性方面,我们提出了一种新的激活函数DY-Shift-Max,它将通道与动态系数进行非线性融合。这个新的激活会迫使网络去学习使用适应于输入的系数,来混合输入特征图中不同的circular channel shifts,并在这些融合中选择最好的。结果表明该方法以极小的计算代价提高了组分解的表征能力。
基于这两种新算子(MF-Conv 和DY-Shift-Max)得到了MicroNet家族。图1中展示了在ImageNet上的性能,MicroNet远超SOTA水平,特别是在12M和22M FLOPs的MicroNet在top1准确率上分别比MobileNetV3高出了9.6%和4.5%。对于极端的6M FLOPs,MicroNet实现了51.4%的top1精度,比MobileNetV3(12M FLOPs版本)高出了1.6%。
尽管MicroNet是为理论上FLOPs而手动设计的,但它在边缘设备上的快速推理性能优于MobileNetV3(基于推理延迟)。此外,我们的MicroNet在对象检测和关键点检测方面优于MobileNetV3,但计算成本大大低于MobileNetV3。
2、相关工作
略
3、Micro-Factorized Convolution
MFConv的目的是优化平衡通道数和节点连接性。每层的连接性E定义为每个输出节点的路径数,一条路径连接输入和输出节点。比如下图输入通道12,输出通道6,每一根线就代表一条路径,这些线的代表节点连接性。

3.1 Micro-Factorized Pointwise Convolution
这部分就是将MFConv用于逐点卷积pointwise conv。因为在轻量化卷积神经网络中深度可分离卷积出场率很高,而深度可分离卷积中pointwise conv占的计算量很大(比如ShufllNet中就是使用分组卷积优化pointwise conv进一步降低计算量)
首先来看看Micro-Factorized Pointwise Convolution是如何实现了(个人感觉就是对称的分组卷积,中间是Channel Shuffle)
首先,作者提出使用组自适应卷积来分解一个pointwise卷积(实际上就是对pointwise卷积改为分组卷积,在ShuffleNet中就是如此,不过本文新增自适应组数功能)。为了简洁起见,假设输入通道=输出通道= C C C,忽略bias。
卷积核矩阵 W W W被分解为两个组自适应卷积,其中组数根据通道数 C C C和压缩率 R R R计算得到:
W = P Φ Q T , W=PΦQ^T, W=PΦQT,
其中 W W W是 C ∗ C C*C C∗C矩阵, Q Q Q是一个 C ∗ C / R C*C/R C∗C/R矩阵,它将通道数压缩 R R R倍, P P P是一个 C ∗ C / R C*C/R C∗C/R矩阵,它将通道数扩展回 C C C。 P P P和 Q Q Q是带有 G G G块的对角矩阵(因为分成了 G G G组),每个块都一个小组卷积。 Q Q Q是一个 C / R ∗ C / R C/R*C/R C/R∗C/R的排列矩阵,实现通道混洗功能,其混洗顺序和ShuffleNet中一样。分解层的计算复杂度 O = 2 C 2 R G O=\frac{2C^2}{RG} O=RG2C2。图2左边展示了分组的样例,图中 C C C=18, R = 2 R=2 R=2, G = 3 G=3 G=3

对于Micro-Factorized Pointwise Convolution的理解,下图是按照个人理解画的图,个人感觉就是ShuffleNet的优化,ShuffleNet也是针对1x1卷积的大计算量优化的,使用的是针对1x1卷积的分组卷积+Channel Shuffle,ShuffleNet论文可以看ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices–Xiangyu Zhang
从计算量来看,如果使用分组卷积(分三组),那么通路有 6 ∗ 6 ∗ 3 = 108 6*6*3=108 6∗6∗3=108,卷积核18个,但是分组卷积使用的卷积核为 1 ∗ 1 ∗ 6 1*1*6 1∗1∗6

下面图中红色是普通卷积的连接方式。

从参数量来对比(就是路径数,MFConv中卷的直连和Channel Shuffle不算):
- 普通卷积:共有 18 ∗ 18 = 324 18*18=324 18∗18=324个参数
- 分组卷积:共有 6 ∗ 6 ∗ 3 = 108 6*6*3=108 6∗6∗3=108个参数
- Micro-Factorized Pointwise Convolution:共有 6 ∗ 9 + 3 ∗ 18 = 108 6*9+3*18=108 6∗9+3∗18=108
似乎Micro-Factorized Pointwise Convolution和分组卷积差不了多少,但是Micro-Factorized Pointwise Convolution的优势在于使用同样的参数量增强了特征提取能力。从下文可以看出Micro-Factorized Pointwise Convolution实现了每个输出都和每个输入节点有“连接”,而分组卷积要实现这种功能,需要在Group Conv+Channel Shuffle的后面再来一次卷积,从而再次增加参数量。
(个人感觉在“连接”能力上Micro-Factorized Pointwise Convolution=Group Conv+Channel Shuffle+Conv,而参数量Micro-Factorized Pointwise Convolution=Group Conv+Channel Shuffle)
中间 Φ Φ Φ表示为隐藏通道,分组操作限制了 Φ Φ Φ的通道数,每个 Φ Φ Φ通道和 C G \frac{C}{G} GC个输入通道连接,每个输出通道和 C R G \frac{C}{RG} RGC个 Φ Φ Φ通道连接。每个输出节点的“输入-输出”连接性 E = C 2 R G 2 E=\frac{C^2}{RG^2} E=RG2C2,计算示意图如下图。

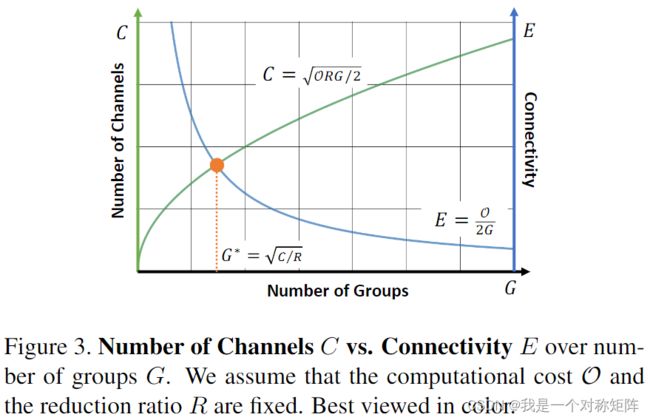
当计算成本预算 O = 2 C 2 R G O=\frac{2C^2}{RG} O=RG2C2和压缩因子R固定时,通道数C和连接性E会随着G变化:
C = O R G 2 , E = O 2 G C=\sqrt{\frac{ORG}{2}},E=\frac{O}{2G} C=2ORG,E=2GO
如图3所示,当分组数G和通道数C增加时,连接性E会降低,当两个曲线相交时(C=E)(交点代表平衡,最好的折衷):
G = C R ,( 3 ) G=\sqrt{\frac{C}{R}},(3) G=RC,(3)
以上便是自适应分组的理论依据,推导出自适应公式为上面这个
3.2 Micro-Factorized Depthwise Convolution
这部分是将MFConv应用于depthwiseConv。
图2中间部分展示micro-factorization是如何被应用到kxk的depthwise卷积上的。这个卷积核被因式分解为kx1和1xk卷积核上,每个通道 k ∗ k k*k k∗k核矩阵 W W W,向量 P P P为 k ∗ 1 k*1 k∗1,向量 Q T Q^T QT为 1 ∗ k 1*k 1∗k, Φ Φ Φ是一个标量=1,被分解后计算复杂度从 O ( k 2 C ) O(k^2C) O(k2C)降低到 O ( k C ) O(kC) O(kC)。
结合Micro-Factorized Pointwise Convolution和Micro-Factorized Depthwise Convolution: 这两种MFConv可以用两种不同方法结合:1)常规组合;2)精简组合。
常规组合就是简单将两种卷积组合起来。
精简组合如图2右图,使用Micro-Factorized Depthwise Convolution,通过为每个通道应用多个空间滤波器扩展通道数。然后应用一个自适应组卷积(group-adaptive convolution)来融合和压缩通道数。与常规组合相比,它通过节省通道融合(Pointwise )计算,花费了更多的资源在学习空间滤波器上(Depthwise),实验证明,这对实现较低FLOPs的网络层是更有效的。

(首先每个节点就是一个通道图,其大小为 W ∗ H W*H W∗H,上面个人认为在蓝色部分,为每个通道应用两个卷积核,每个卷积核被分解为向量,就有两个行向量和两个列向量,从而最后通道扩大4倍。在灰色部分就是Micro-Factorized Pointwise Convolution的前部分,就是分组卷积,数组自适应而已)
4、Dynamic Shift-Max
到目前为止,我们已经讨论了有效的静态网络的设计,它不根据输入改变其权重(?)。我们现在介绍动态移位极大(DY-ShiftMax),这是一种加强通过micro-factorization创建的group之间的联系的动态非线性。这对于聚焦组内连接性的Micro-Factorized pointwise convolution起到了补充(加强)作用。
设 x = x i ( i = 1 , . . . , C ) x={x_i}(i=1,...,C) x=xi(i=1,...,C)表示一个输入vector(或tensor),然后通道 C C C会倍分成 G G G组,每个 G G G有 C G \frac{C}{G} GC个通道。
x x x的第 j j j组的circular shift(shifting j C G 通道 j\frac{C}{G}通道 jGC通道)表示为向量 x ^ i j = x ( i + j C G ) m o d C \hat {x}^j_i=x_{(i+j\frac{C}{G})mod C} x^ij=x(i+jGC)modC。
Dynamic Shift-Max将输出K个混合的最大值,多组( J J J)位移如下组合(each of which combines multiple (J) group shifts as:)
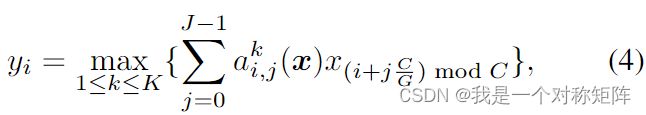
- a i , j k ( x ) a^k_{i,j}(x) ai,jk(x)是动态权重,动态是因为依赖于输入 x x x,由均值池化,两个全连接层和一个sigmoid层组成,就像是Squeeze-and-Excitation(SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size)。
- i i i:第i通道
- j j j:第j组
(一堆理论分析),当J=2和K=2时,分类性能和复杂度得到了很好的折衷
以下是根据论文和代码进行的分析
先给出代码(下方代码和解释都以输入输出通道=9,且分组=3为例):
import torch
import torch.nn as nn
class h_sigmoid(nn.Module):
def __init__(self, inplace=True, h_max=1):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
self.h_max = h_max / 6
def forward(self, x):
return self.relu(x + 3) * self.h_max
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class DYShiftMax(nn.Module):
"""
1):对于通道间的交流实际上就是不同通道的融合,可以看self.index的产生就是将通道按一定顺序打乱
比如初始x_out的通道顺序=[0,1,2,3,4,5,6,7,8]
按顺序打乱的通道顺序x_2=[4,5,3,7,8,6,1,2,0],可以画图看对于的顺序,有一定的规律
然后将x_out和x_2按权重(a,b)融合,实际上就是(a*通道0+b*通道4)完成第一输出通道的融合,以此类推
2):上面提到了权重,本文中使用了两组权重(a1,b1)和(a2,b2),就会得到两个融合特征图,使用max选择最大的那个融合特征图
那么权重的来源是输入x经过pooling和fc扩大后,再分割生成2两组权重。
一句话来讲就是x经过操作后生成两组权重,再将打乱后的特征图按两组权重融合,然后择取最大的作为输出。
"""
def __init__(self, inp, oup, reduction=4, act_max=1.0, act_relu=True, init_a=[0.0, 0.0], init_b=[0.0, 0.0],
relu_before_pool=False, g=None, expansion=False):
"""
:param inp: 输入通道数
:param oup: 输出通道数(和输入通道数相同)
:param reduction:
:param act_max:
:param act_relu:
:param init_a:
:param init_b:
:param relu_before_pool:
:param g: 分组数
:param expansion:
"""
# 以下参数注释都是 layer = DYShiftMax(inp=9, oup=9, act_max=2.0, act_relu=True, init_a=[1.0, 0.5], reduction=8,
# init_b=[0.0, 0.5],g=(0, 3), expansion=False) 的值
self.info = {"inp": inp, # 9
"oup": oup, # 9
"reduction": reduction, # 8
"act_max": act_max, # 2
"act_relu": act_relu, # True
"init_a": init_a, # [1.0, 0.5]
"init_b": init_b, # [0.0, 0.5]
"relu_before_pool": relu_before_pool, # False
"g": g, # [0, 3]
"expansion": expansion} # False
super(DYShiftMax, self).__init__()
self.oup = oup
self.act_max = act_max * 2
self.act_relu = act_relu
self.avg_pool = nn.Sequential(
nn.ReLU(inplace=True) if relu_before_pool == True else nn.Sequential(),
nn.AdaptiveAvgPool2d(1)
)
self.exp = 4 if act_relu else 2
self.init_a = init_a
self.init_b = init_b
# determine squeeze
squeeze = _make_divisible(inp // reduction, 4)
if squeeze < 4:
squeeze = 4
self.squeeze = squeeze # 8
self.fc = nn.Sequential(
nn.Linear(inp, squeeze), # inp=48
nn.ReLU(inplace=True),
nn.Linear(squeeze, oup * self.exp), # oup=48 exp=4
h_sigmoid()
)
if g is None:
g = 1
self.g = g[1]
if self.g != 1 and expansion:
self.g = inp // self.g
# self.g=12 self.gc=4
self.gc = inp // self.g
index = torch.Tensor(range(inp)).view(1, inp, 1, 1) # tensor([0,1,2,3,4,5,6,7,8])
index = index.view(1, self.g, self.gc, 1, 1) # shape=[1,3,3,1,1]
indexgs = torch.split(index, [1, self.g - 1], dim=1) # 在dim=1上划分为1:2,即得到shape为[1,1,3,1,1]和[1,2,3,1,1]的两个tensor
indexgs = torch.cat((indexgs[1], indexgs[0]), dim=1) # shape=[1,3,3,1,1]
indexs = torch.split(indexgs, [1, self.gc - 1], dim=2) # 在dim=1上划分为1:2,即得到shape为[1,3,1,1,1]和[1,3,2,1,1]的两个tensor
indexs = torch.cat((indexs[1], indexs[0]), dim=2)
self.index = indexs.view(inp).type(
torch.LongTensor) # shape=(9,) tensor([4,5,3,7,8,6,1,2,0]) LongTensor:int64
self.expansion = expansion
def forward(self, x): # x.shape=[1,9,56,56]
x_in = x
x_out = x
b, c, _, _ = x_in.size()
y = self.avg_pool(x_in).view(b, c) # y.shape=[1,9]
y = self.fc(y).view(b, self.oup * self.exp, 1, 1)
y = (y - 0.5) * self.act_max # act_max=4
n2, c2, h2, w2 = x_out.size()
x2 = x_out[:, self.index, :, :] # 根据通道打乱后重新排列得到x2
if self.exp == 4:
# (a1,b1)和(a2,b2)是由x运算后得到了两组权重
a1, b1, a2, b2 = torch.split(y, self.oup, dim=1) # 将y分割得到两组权重,shape都=[1,9,1,1]
a1 = a1 + self.init_a[0]
a2 = a2 + self.init_a[1]
b1 = b1 + self.init_b[0]
b2 = b2 + self.init_b[1]
z1 = x_out * a1 + x2 * b1
z2 = x_out * a2 + x2 * b2
out = torch.max(z1, z2)
elif self.exp == 2:
a1, b1 = torch.split(y, self.oup, dim=1)
a1 = a1 + self.init_a[0]
b1 = b1 + self.init_b[0]
out = x_out * a1 + x2 * b1
return out
layer = DYShiftMax(inp=9, oup=9, act_max=2.0, act_relu=True, init_a=[1.0, 0.5], reduction=8, init_b=[0.0, 0.5],
g=(0, 3), expansion=False)
x = torch.rand([1, 9, 56, 56], dtype=torch.float32) # x.shape=[10,48,56,56]
output = layer(x)
print(output.shape)
代码看起来比较复杂,一些细节我也还没弄懂,但是抓住核心两个点:
1)通道打乱:就是将原通道顺序打乱,形成新的打乱张量
2)权重生成:通过输入张量x生成融合阶段所需要的权重
2)融合:原始输入和打乱的张量进行加权和融合,再通过max获取最大的作为输出
通道打乱如下图所示,这样就形成了 x _ o u t x\_out x_out和 x 2 x2 x2,融合本质就是加权和,表示为:
f u s e = a ∗ x _ o u t + b ∗ x 2 fuse=a*x\_out+b*x2 fuse=a∗x_out+b∗x2
在官方代码中,作者使用了两组权重,也就是会有两个融合,也就是代码中的:
z 1 = x _ o u t ∗ a 1 + x 2 ∗ b 1 z1 = x\_out * a1 + x2 * b1 z1=x_out∗a1+x2∗b1
z 2 = x _ o u t ∗ a 2 + x 2 ∗ b 2 z2 = x\_out * a2 + x2 * b2 z2=x_out∗a2+x2∗b2
然后从 z 1 和 z 2 z1和z2 z1和z2中选取融合特征最大的作为输出。

4.1 通道打乱
从上图可以看出当通道数为9,组数为3时的通道打乱的结果,但是是如何打乱的呢?
代码中是从index 到self.index变量这段代码就是在打乱通道顺序,也可以从下图可以看出,实际上就是将index张量切割-拼接-再切割-再拼接的过程,只不过前两步在dim=1上进行,后两步在dim=2上进行。

4.2 两组权重怎么来?
权重也就是代码中的y,可以看到y的流程:输入张量 x _ i n x\_in x_in经过avgpooling、fc等算子后得到新的y,此时y.shape=[1,36,1,1],然后再通过a1, b1, a2, b2 = torch.split(y, self.oup, dim=1)将y划分为4个参数,也就是两组权重(a1,b1)和(a2,b2),这四个参数的shape=[1,9,1,1]。
至此两组权重就产生了,实际上因为是根据输入张量生成的,输入不同权重也就不同,所以这也是该激活函数中动态的来源
4.3 融合
到这里就很简单了,通道打乱前后的张量有了,权重也有了,剩下的就是加权和:
# 通过两组权重生成两个融合特征
z1 = x_out * a1 + x2 * b1
z2 = x_out * a2 + x2 * b2
# 选择融合特征最大的作为输出
out = torch.max(z1, z2)
综合以上可以看到,Dynamic Shift-Max就是将通道打乱前后的特征图进行加权和,将本不属于同一组的特征进行了融合,从而加强了组间的连接。
而Dynamic Shift-Max的非线性表现在两方面:
1)输出K(这里也就是2组权重)个融合特征中的最大值(像ReLU就是max(0,x),就具有非线性,只不过这里是max(fuse1,fuse2)而已)。
2)动态地根据输入张量来生成权重值,进行加权融合。
这两种操作增加了网络的表示能力,弥补了减少的层数所固有的损失。
5、MicroNet
基于以上我们设计的Micro-Factorized convolution和dynamic Shift-Max,构建了MocrioNet家族。
5.1 Micro-Blocks
MicroNet包含了三种Micro-Blocks,如图4所示,以不同的方法结合Micro-Factorized pointwise和depthwise convolutions。所有的Micro-Blocks都使用dynamic Shift-Max激活函数。

Micro-Factorized pointwise Conv和前文的形式一样,可以理解
而MF pointwise Conv半个(梯形)就是分组卷积
Micro-Factorized pointwise Conv可以通过几组1xk和kx1扩展通道数
Micro-Block-A:
Micro-Block-A如图4a,使用了Micro-Factorized pointwise 和depthwise convolutions构成的精简组合,在图2右可以看到。它使用MF depthwise conv扩展通道数,然后使用group-adaptive卷积压缩通道数。它最适合高分辨率(比如112x112或56x56)下的低网络层(应该是靠近输入端分辨率高,就适合使用这个块)
Micro-Block-B:
如图4b,用于连接Micro-Block-A和Micro-Block-C。不同于Micro-Block-A,它使用full Micro-Factorized pointwise convolution(包含两个group-adaptive conv)。因此,它同时压缩和扩展通道数。所有的MicroNet模型都有一个Micro-Block-B
Micro-Block-C:
如图4c是一个常规的Micro-Factorized depthwise and pointwise convolutions组合。它最适合更高的网络层(靠近输出端),因为与精简组合相比,它为channel fusion(pointwise)分配了更多的计算力。当输入和输出右相同维度时,使用skip connection。
每一个micro-block右三个超参数:核尺寸k,输出通道c,Micro-Factorized pointwise convolution的bottleneck的通道压缩因子R。注意分组数是由两个group-adaptive convolutions确定(见公式3)
5.2 结构
所有的模型为了优化FLOPs都是手动去设计的,没有使用NAS去搜索。因为在当前,FLOPs在所有硬件上相当于推理延迟。
我们提出了4个模型M0、M1、M2、M3,它们的计算成本分别为4M、6M、12M、21M MAdds。表1列出了他们完整结构

结合前面介绍的Micro-Blocks:Micro-A扩展通道再压缩,所以在输入端更适用,并且可能计算量(毕竟叫精简组合)更小,在输入端的分辨率高,所以使用精简组合能降低计算量。而Micro-C更注重通道融合,在后期通道更多,所以在输出端更适用。
(所以来讲,输入端分辨率高,为其设计计算量小的模型,而输出端通道多,为其设计加强通道连接的模块)
所有的模型都按以下方式来设计:
stem layer – Micro-Block-A – Micro-Block-B – Micro-Block-C。
网络的超参数基于这样的规则:R在模型中固定(M0中R=4,M1~3中R=6),通道C从low到high上升,深度从M0~M1也增加。对于最深的M3模型,我们在仅使用一个dynamic Shift-Max(在block后面的depthwise conv)。stem层包括一个3x1卷积和一个1x3组卷积,后面跟着一个ReLU激活函数。第二个卷积扩展了通道数。
5.3 之前的相关工作(直接翻译的)
(Micronet与最近的深度学习文献有各种联系,它与流行的MobileNet和ShuffleNet模型有关。它与MobileNet共享反向瓶颈结构,并与ShuffleNet共享分组卷积的使用。相反,微网在卷积和激活函数上都与这些模型不同,首先,它将逐点卷积分解为组自适应卷积,其组数G=√C/R是信道自适应的,并保证最小路径冗余。其次,它分解了深度卷积。第三,它依赖于一种新的激活函数Dynamic Shift-Max,以一种非线性和依赖于输入的方式来加强群的连通性。Dynamic ShiftMax本身推广了最近提出的动态REU(即,动态REU是J=1的特例,每个通道单独被激活)。)
6、实验
我们验证MicroNet在三个任务上:1)图像分类;2)目标检测;3)关键点检测。在下面的实验中,我们使用MobileNetV3指的是MobileNetV3-Small。
(个人兴趣问题,以下只总结图像分类的实验)
6.1 ImageNet Classification
我们首先评估四个MicroNet(M0-M3)对ImageNet分类的任务。ImageNet有1000个类别,其中1281,167个图像用于train,50,000个图像用于validation。
所有的模型都使用SGD(0.9momentum)优化器。图像分辨率为224x224。数据增强使用standard random cropping and flipping。我们使用mini-batch size=512,学习率=0.02(因为作者实验使用了多卡,而多卡数量和学习率存在倍数关系)。每个模型训练600epochs(使用cosine learning rate decay)。在M0、M1和M2中weight decay=3e-5,dropout rate=0.05。在M3中weight decay=4e-5,dropout rate=0.1。
6.1.1 消融实验
使用MicroNet-M2进行了几次消融实验。所有的模型训练300epoch,默认超参数DY-Shift-Max设置J=2,K=2.
From MobileNet to MicroNet:
表2展示了从MobileNet到MicroNet的路径

两者都有inverted bottleneck逆瓶颈层结构。修改MobileNetV2使其和MicroNet有相似的复杂性(MAdds)
分组数G:
Micro-Factorized pointwise convolution 包括了两个group adaptive卷积,而分组数根据 C R \sqrt{\frac{C}{R}} RC确定。表3a比较了相似结构和FLOPs(10.5MAdds)的网络,在固定分组和自适应组数的结果,可以看出自适应分组卷积得到了更高的精度,表明其在输入/输出连接和通道数量之间进行最佳权衡的重要性。

表3b比较了不同系数λ的影响: G = λ C R G=λ\sqrt{\frac{C}{R}} G=λRC,更大的λ代表更多的通道但是更少的input/output连接性,可以看出最佳平衡是当λ在0.5到1之间。当λ从该最佳点(=1)增加(更多通道但连接更少)或降低(通道更少但连接更多)时,Top-1准确率会下降。(这里需要结合图3,从图三标题可以看到说的是固定计算成本O和R,那么随着分组数增加,通道数C就会增加,但是连接性E会降低)
Lite combination:
表3c比较了在不同层使用lite combination精简组合。发现精简组合在lower layers(靠近输入)层更加有效。与普通组合相比,它节省了通道融合(pointwise)的计算,以允许更多的空间过滤器(depthwise)。
激活函数:
Dynamic Shift-Max与之前的三个激活函数进行了比较:ReLU、SE+ReLU和动态ReLU。表4显示,Dynamic Shift-Max的性能明显优于这三种算法(至少2.5%)。
DY-Shift-Max的位置:
A 1 、 A 2 、 A 3 A_1、A_2、A_3 A1、A2、A3分别代表图4中按顺序的蓝色激活函数模块位置(当然第一个只有 A 1 和 A 2 A_1和A_2 A1和A2两个位置)

DY-Shift-Max中的超参数:

6.1.2 与先前的网络比较
表7将MicroNet与最先进的模型进行了比较,后者的复杂性低于24M Flop。由于前人工作缺乏10M FLOPs预算内的结果,我们将流行的MobileNetV3分别使用宽度乘数0.2和0.15,扩展到6M和4M FLOPs作为基线。他们与MicroNet使用相同的训练配置。
带#表示MAdds一样,但参数量不一定相同。不带#表示参数量相同但是MAdds不一定相同。

6.1.3 推理延迟
我们在Intel® Xeon® CPU E5-2620 v4 (2.10GHz)设备上计算延迟,我们在单线程模型下测试了batchsize=1.测试了5000张224x224图像的平均推理延迟。
可以看出在有相同时延上MicroNet比MobileNetV3精度更高,特别是4ms时延上,MicroNet比MobileNetV3高出了10%。

6.1.4 讨论
如图5所示,在相同的FLOPs下,MicroNet的性能明显优于MobileNetV3,但在相同的延迟下,差距会缩小。这是由于两个原因:1)与通过搜索优化延迟的MobileNetV3不同,MicroNet是基于理论上的FLOPs手动设计的。2)分组卷积和dynamic Shift-Max算法的实现不是最优的(我们使用了PyTorch来实现)。我们观察到,组卷积的延迟并不是随着组数的增加而成比例地减小,并且dynamic Shift-Max显著慢于相同浮点数的卷积。
我们相信,通过使用硬件感知体系结构搜索来寻找延迟友好的MicroFactorized convolution and dynamic Shift-Max组合,可以进一步提高MicroNet的运行时性能。MicroNet还可以利用分组卷积和Dynamic Shift-Max中的优化改进来加快推理速度。我们将在未来的工作中对这些进行研究。
7、总结
在本文中,我们提出了MicroNet来处理极低的计算开销,它建立在两个提出的算子:Micro-Factorized convolution and Dynamic Shift-Max。前者通过点卷积和深度卷积的低阶近似,在通道数和输入/输出连通性之间取得平衡。后者fuses consecutive channel groups dynamically,增强节点连通性和非线性,以补偿深度较浅带来的不利影响。一个MicroNets族在极低的FLOPs下实现了三个任务(图像分类、目标检测和人体姿态估计)的坚实改进。我们希望这项工作能为多视觉任务中高效的CNN提供良好的baseline。