2022年全国大学生数学建模竞赛C题思路与程序
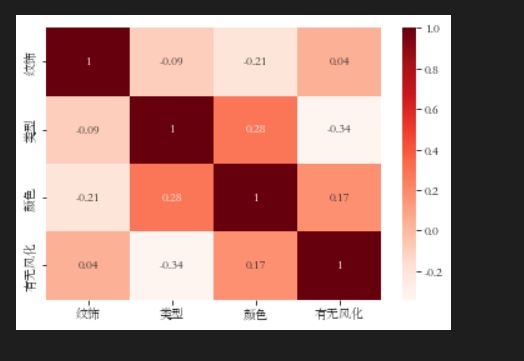
第一题考虑相关性,可行的方法很多,当然传统的感知机,决策树,随机森林都可以队表面风化与其玻璃类型、纹饰和颜色的关系进行分析,当然也可以从相关性上考虑,比如灰色关联,shapely等模型和一些基尼系数、两个相关系数等评估指标,或者采用最简单的MLP等神经网络隐式去拟合出判别函数,或者一些高级些的聚类分析等,后几问也类似,当然也可以用data mining的方法,比如提升树,lightboost、Xgboost等集成学习方法,当然由于数据太少了,不建议用DL或集成学习,往往最简单的model对付这种问题更不会那么容易overfitting,当然还是要看精准率召回率等等。
这里我已经搞好程序,从基本的感知机到逐步黑盒化的神经网络,完成了从数据清洗,数据分析与程序实现:


-
感知机是二类分类的线性模型,属于判别模型
-
感知机学习旨在求出将训练数据进行线性划分的分离超平面。是神经网络和支持向量机的基础
-
损失函数选择
- 损失函数的一个自然选择是误分类点的总数,但是,这样的损失函数不是参数 w , b w,b w,b的连续可导函数,不易优化
- 损失函数的另一个选择是误分类点到超平面 S S S的总距离,这正是感知机所采用的
-
感知机学习的经验风险函数(损失函数)
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_i\in M}y_i(w\cdot x_i+b) L(w,b)=−xi∈M∑yi(w⋅xi+b)
其中 M M M是误分类点的集合,给定训练数据集 T T T,损失函数 L ( w , b ) L(w,b) L(w,b)是 w w w和 b b b的连续可导函数
原始形式算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } , x i ∈ R n , y i ∈ { + 1 , − 1 } , i = 1 , 2 , 3 , … , N ; 学习率 0 < η ⩽ 1 T=\{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\},x_i\in R^n,y_i\in {\{+1,-1\}},i=1,2,3,\dots,N;学习率0<\eta\leqslant 1 T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈Rn,yi∈{+1,−1},i=1,2,3,…,N;学习率0<η⩽1
输出: w , b ; 感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) w,b;感知机模型f(x)=sign(w\cdot x+b) w,b;感知机模型f(x)=sign(w⋅x+b)
选取初值 w 0 , b 0 w_0,b_0 w0,b0
训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
如果 y i ( w ⋅ x i + b ) ⩽ 0 y_i(w\cdot x_i+b)\leqslant 0 yi(w⋅xi+b)⩽0
w ← w + η y i x i w\leftarrow w+\eta y_ix_i w←w+ηyixi
b ← b + η y i b\leftarrow b+\eta y_i b←b+ηyi转至(2),直至训练集中没有误分类点
- 这个是原始形式中的迭代公式,可以对 x x x补1,将 w w w和 b b b合并在一起,合在一起的这个叫做扩充权重向量
对偶形式算法
- 对偶形式的基本思想是将 w w w和 b b b表示为实例 x i x_i xi和标记 y i y_i yi的线性组合的形式,通过求解其系数而求得 w w w和 b b b。
输入: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } , x i ∈ R n , y i ∈ { + 1 , − 1 } , i = 1 , 2 , 3 , … , N ; 学习率 0 < η ⩽ 1 T=\{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\},x_i\in R^n,y_i\in {\{+1,-1\}},i=1,2,3,\dots,N;学习率0<\eta\leqslant 1 T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈Rn,yi∈{+1,−1},i=1,2,3,…,N;学习率0<η⩽1
输出:
α , b ; 感知机模型 f ( x ) = s i g n ( ∑ j = 1 N α j y j x j ⋅ x + b ) , α = ( α 1 , α 2 , ⋯ , α N ) T \alpha ,b; 感知机模型f(x)=sign\left(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b\right), \alpha=(\alpha_1,\alpha_2,\cdots,\alpha_N)^T α,b;感知机模型f(x)=sign(∑j=1Nαjyjxj⋅x+b),α=(α1,α2,⋯,αN)T
α ← 0 , b ← 0 \alpha \leftarrow 0,b\leftarrow 0 α←0,b←0
训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
如果 y i ( ∑ j = 1 N α j y j x j ⋅ x + b ) ⩽ 0 y_i\left(\sum_{j=1}^N\alpha_jy_jx_j\cdot x+b\right) \leqslant 0 yi(∑j=1Nαjyjxj⋅x+b)⩽0
α i ← α i + η \alpha_i\leftarrow \alpha_i+\eta αi←αi+η
b ← b + η y i b\leftarrow b+\eta y_i b←b+ηyi转至(2),直至训练集中没有误分类点
-
Gram matrix
对偶形式中,训练实例仅以内积的形式出现。
为了方便可预先将训练集中的实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵
G = [ x i ⋅ x j ] N × N G=[x_i\cdot x_j]_{N\times N} G=[xi⋅xj]N×N
具体实现与算法
请见https://mianbaoduo.com/o/bread/Y5eTmJ9w