即插即用式多项目自动化测试平台设计与实现——实现部分
实现部分内容如下:
核心调度:
核心调度CoreManage部分需要对环境中的架构进行管理和调度,其中:
数据部分包括:
- 任务实例
- 测试机实例
- 报告实例
逻辑部分包括:
- 基础任务队列
- 任务实例的管理
- 测试机的管理
- 报告的管理
- 邮件任务的轮询
核心调度提供Job队列的接口,它继承自task接口,task中定义了基本的队列线程执行逻辑。任务实例、虚拟机实例和报告实例都继承于Job队列接口,包含了Job的添加,执行,当前任务判断、队列状态判断以及日志等通用方法。注意这里的报告并非存放在DB中的测试结果,而是每个任务在测试机执行前备份的执行文件和执行结束后生成的对应file结果信息。
执行的方式为找到任务实例中对应的项目,提供相应的测试机列表,这时任务会按照参数将配置好的信息发送给对应的测试机实例,生成执行前的备份,并在测试机队列中进行排队,对应的邮件任务池会将任务添加进去。
测试机实例按照队列中的Job参数进行各自的启动,环境配置,并开始执行测试。测试结果保存在测试机本地,执行完毕后拷贝到指定共享报告目录,分析结果并将结果数据入库。
邮件池会轮询判断每个任务对应的报告,判断它的执行状态。并最终给出结果的报告邮件。邮件包含结果统计,测试数据信息以及测试对应的报告目录。
Web.py网站:
由于网站内容相对少一些,采用了web.py的框架,按照模板的方式进行开发。需要实现的页面类包括:submit任务提交,task查询,case明细查询,统计报告图链接,失败截图链接,默认用例查询链接。
其中:
统计报告是在GET服务运行时生成的本地图片,序列化后直接返回image/jpg类型Content-Type即可;
失败截图保存在数据库中,由于一次只需要打开一张截图,所以不涉及到大量图片给读取时给Server带来的内存问题;同样返回image/jpg类型Content-Type,由浏览器直接打开;
默认用例为Server端xml文件,直接读取序列化后以application/xml类型返回,浏览器会直接打开xml文件进行显示;
较难的部分如下:
提交页面部分:
1> 机器状态队列:可以直接通过测试实例读取相应的测试机运行状态和队列信息;
2> 由于只提供一个任务提交模板,公共参数和JS可以放在这个模板的form中;然而不同的项目需要有不同的参数和JS判断,需要动态的拼接这个提交页面;web.py由于安全性的考虑,不允许传入的字符串参数直接作为html标签,即插即用的结构无法实现。
实际上任何网站开发架构,无外乎通过编程的方式,生成和处理html静态页面,所以可以在web.py完成GET所有的render处理,返回到页面之前,截获这段html,并进行我们的插入操作:
1 Html=render.submit(param1,param2) 2 3 Result=html.values()[0].replace(target,source) 4 5 Return result
这样的方式可以实现不同的项目在web.py中使用相同的模板;
3> POST执行部分:
同样的问题,只有一个POST方法,要实现不同项目的post操作。按照设计将核心的操作交个不同项目本身——每个项目提供自己的dopost.py,POST部分会动态加载并且执行。交给每个dopost的参数包括从前天获取的所有form参数和一个任务管理的实例,dopost读取自己需要的参数,完成所有准备工作,然后将任务添加到实例中即可;
执行参数传入之前,需要将获取到的参数整理一下,所有Input参数给出初始值将其转变为字典,便于dopost获取任意的参数值(主要是解决文本上传的问题):
查询部分
1> 任务条件查询:完成时间排序和分页效果就可以了,没有特别的地方;
2> 用例名下查询:包括统计部分,测试结果汇总和统计图;
明细部分包括,所有结果预览,测试机对应错误页面定位和恢复;失败截图的显示:
统计图部分可以采用flash方式或者matplotlib的方式,每次GET中生成图片后一定要进行内存的处理,生成图片的时候注意隔离;
页面定位用锚的方式可以轻松实现,条件允许的话,需要考虑不同浏览器的兼容性;
3> 明细显示的层级:需要测试机->测试用例->用例步骤这样的层次进行显示,由于采取的是关系型数据库,不是Mongo这类可以提供层次关系的db,所以存储的最小粒度信息片是detailed的操作步骤,所以为了满足前台数据分层显示的要求,直接将所有关联数据从DB拿到内存,然后通过python方式进行过滤和分层处理,不建议获取最高层次的数据然后遍历获取查询下一层数据,这样多次链接DB查询效率极其低下。
数据过滤分层的时候极可能采取字典这样的散列集合,不要使用列表,更要避免嵌套循环——数据量本身就很大,页面的查询需要快速高效。
测试机管理
- 虚拟机
虚拟机统一采用WMWare提供的接口,封装一些基本的方法,包括虚拟机创建,快照的各种操作,虚拟机启动,快照恢复,文件拷贝,命令执行,后台运行(提高性能)等;
测试机的实例读取所有虚拟机信息,并将上述操作完全封装,开发接口给任务调用;
- 实体机
实体机通信的方式较多,这里采用最常用的socket方式,一种最简单的设计办法,就是将常用的命令封装成特定消息,消息类型放在消息头部,相互间能够辨别就可以了;需要注意的是,由于一些特殊测试的需要,会涉及到机器的重启和网卡驱动的卸载等系统和硬件上的操作,所以链接的方式采取反拼,定时主动发送心跳状态到Server;
项目管理
- 项目实例:从特定的存储目录中读取所有项目,生成项目实例在内存中进行维护,轮询判断是否有新项目添加;
- 执行任务:任务的执行通过找到相应的任务实例,生成相关的Job,然后操作测试机列表中对应的测试机,将Job添加到每个测试机队列中;
- 执行策略:执行策略的实现同样在项目管理中完成,策略可以封装成一个静态类,提供3种常用的执行分配策略,并给用户提供扩展;3种策略包含:
1> 所有用例在所有执行测试机上各自执行特定次数(1轮,2轮或更多),相互独立(脱机);
2> 所有用例平均分配到给定的测试机中执行(所有测试机是一个任务单元,脱机);
3> 动态分配,每次将固定个数的用例分配到空闲的测试机上,无空闲测试机则等待(节省测试资源,实现较为复杂,分发效率低,联机);
报告管理
- 报告生成:测试机执行完任务后,会从测试机中将报告文件拷贝到特定目录,这时候与执行前的Job文件一起打包,记录下路径——最好做成文件服务器,记录链接;
- 报告邮件制作:
与之前的内从相比,邮件反而没有固定的模板,因为邮件的大部分内容都在网站的查询页面上,所以直接发送消息获取对应的页面信息,保存到本地作为模板。然后将模板读到内存,获取它的统计信息,添加报告文件服务链接和其他信息,发送给任务的提交人。
- 日志管理
日志管理只为开发的调试使用,并不涉及到测试的信息。当然可以广义的将测试结果写入到文件和从文件导入到DB的过程定义为日志,日志的记录部分可以根据需要自己去封装和使用。
用例管理
基础测试架构为pyut,对应的case使用xml方式来实现——当然最终稳定后会整理成关键字驱动的方式。Xml中可以分为项目属性部分,case公共属性部分,case步骤;其中,项目属性是整体的任务属性,有默认值,一些如任务ID等等可以动态的写入;case公共属性包含case的公共参数,全局变量等,还有一些setup和teardown的操作配置,步骤则为真正执行的部分:每个case节点下对应着自己的操作步骤,任务管理实例会按照这些配置生成最终执行的pyut文件,并打包放入测试机执行。
DB设计
DB的设计我觉得是真个项目中最惨的部分,甚至是逆向去设计的。完全违背了自己曾经认为经典的几个范式。但是没有办法,这种后起的架构不可能严丝合缝,另外变数的东西太多——任务不确定,case不确定,虚拟机不确定,所以整个DB就是用来存储结果,并且供实际查询使用。尽管信息片独立,关键结构还算合理,但是绝对的信息冗余。
表:
任务表:保存所有执行过的任务信息;
机器表:保存执行过的测试机的信息和状态;
用例表:保存执行过的用例信息;
这三张表相互独立,对外只有guid;
执行明细表:记录每一步操作的对应信息,当然任务表,机器表和用例表的guid都作为其外键;
失败接图表:保存失败截图,guid为其主键;
视图:视图的设计要看页面显示的需求,基本上构建一个所有明细的视图,一个任务机器状态视图,就已经完全够用了。注意非聚集索引的使用以便提高查询效率。
查询语句:都是基本查询语句的组合,由于数据过滤逻辑在服务端由python处理,数据库端相对负责较少,由于没有专门的数据来记录case的结果和task的结果,所以需要case then等语句做一些统计的查询。
基本上实现的部分已经粗略的讨论完了,细节的处理并不是架构设计上需要考虑的问题,甚至代码也只是简单的给出几行。因为本身架构与语言关系并不是很强。
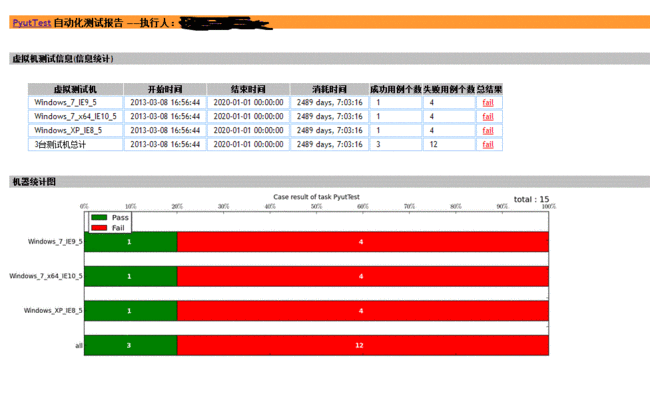
下面是这个架构目前的运行效果,所有数据都是测试数据,最大数据量为10000+条,执行了一晚上,查询页面需要10s左右。
邮件报告中Job信息:
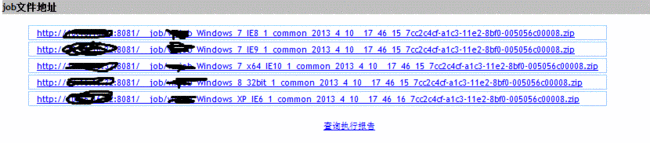
测试机用例明细:
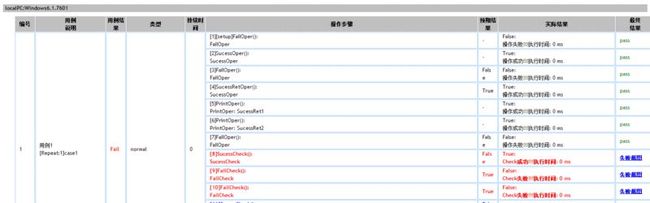
测试机错误用例定位和恢复:

导航部分:

任务提交页面(下面部分是插合式部分):
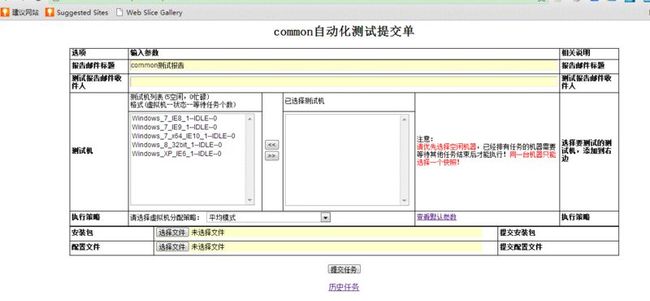
任务查询部分:
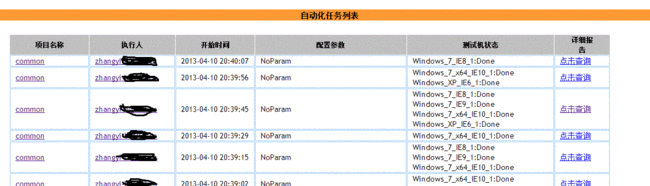
用例统计部分: