基于RAM实现乒乓buffer
乒乓设计的思想
乒乓操作一般用来处理从快速的数据流到慢速的数据流之间的转换,也经常被用来处理跨时钟域的问题,采用串转并的思想,是一种异样的流水线技术的思想。如下图所示:
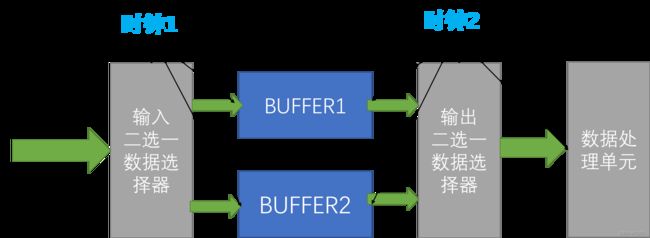
现在面临的问题是输入数据要从快的时钟域到慢的时钟域,如何对数据进行有效的传输并处理。这时便采用乒乓操作。现在假设时钟域1的时钟频率是50MHz,时钟2的频率是25MHz。假设在一个缓冲周期(其实就是BUFFER的存储容量)内要传输16位8比特的数据。在第一周缓冲周期内对BUFFER1写数据。在第二个缓冲周期内,对BUFFER2写数据,同时对BUFFER1采用时钟2的频率对BUFFER进行读数据,但是此时你会发现,在第二个时钟周期读完之后,此时对于BUFFER1的数据的读取只完成了一半(如果只是按照原有的数据宽度读取),换句话说在在第三个缓冲周期写BUFFER1时,发现此时BUFFER1的数据还没有读完。解决这个问题的方法就是我们说的串转并,就是我们每次不是读取8位的数据,而是每次读取16位的数据,这样我们就可以在第二个缓冲周期内把BUFFER1的数据读取完毕,以便在第三个缓冲周期写BUFFER1同时读取BUFFER2的数据,周而复始形成了流水线。
RAM IP
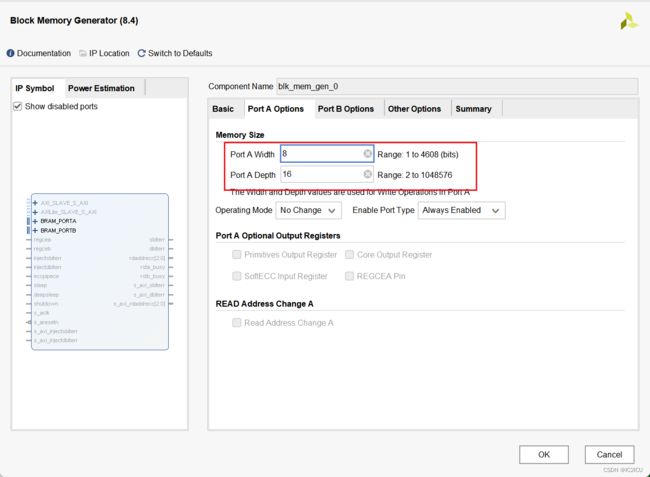
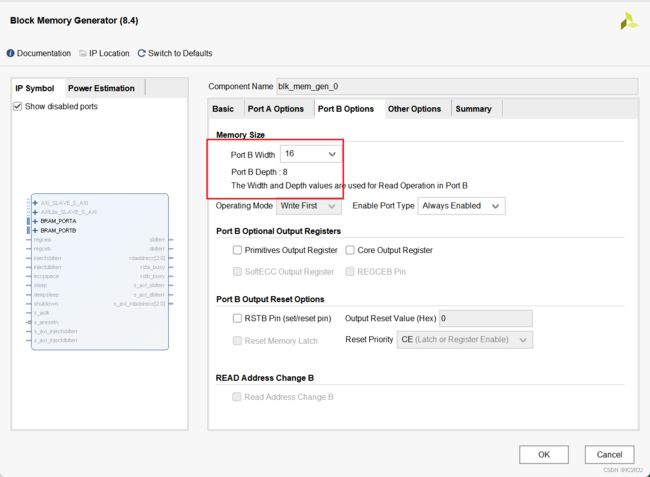
声明的RAM的IP是一个双端口的ram,输入数据宽度是8位宽,深度是16。输出数据的宽度是16位宽,深度是8.如下图所示:
锁相环IP
其作用是输入50MHz的时钟,输出25MHz的时钟。


乒乓BUFFER的设计思想
写BUFFER
采用了状态机作为控制逻辑,决定写BUFFER1还是BUFFER2.
| IDLE | 空闲状态 |
|---|---|
| WR_BUF1 | 写BUFFER1 |
| WR_BUF2 | 写BUFFER2 |
| END_WR | 结束写状态 |
状态之间跳转的如下代码所示:
always @(*) begin
case(state)
IDLE: next_state <= start ? WR_BFR1 : IDLE;
WR_BFR1:next_state <= wr_buf1_end ? WR_BFR2 : WR_BFR1;
WR_BFR2:next_state <= wr_buf2_end ? END_WR : WR_BFR2;
END_WR: next_state <= IDLE;
endcase
end
读BUFFER
采用了状态机作为控制逻辑,决定读BUFFER1还是BUFFER2.
| IDLE | 空闲状态 |
|---|---|
| RD_BUF1 | 读BUFFER1 |
| RD_BUF2 | 读BUFFER2 |
| END_RD | 结束读状态 |
| 跳转逻辑如下: |
always @(*) begin
case(read_state)
IDLE: rd_nxt_state <= wr_buf1_end ? RD_BFR1 : IDLE;
RD_BFR1:rd_nxt_state <= rd_buf1_end ? RD_BUBBLE : RD_BFR1;
RD_BUBBLE:rd_nxt_state <= RD_BFR2;
RD_BFR2:rd_nxt_state <= rd_buf2_end ? END_RD : RD_BFR2;
END_RD: rd_nxt_state <= IDLE;
endcase
end
实现的全部代码(注释详细)
//date:2022/9/7
//function:实现一个ram的pingpongbuffer
//输入数据流的时钟是50MHz
//输出数据流(处理数据流)的时钟是25MHz
//采用vivado的IP生成的ram
module pingpong_buffer(
input wire clk ,
input wire rst_n ,
input wire [7:0] data_in ,
input wire start ,
output wire [15:0] data_out ,
output wire locked
);
parameter IDLE = 3'd0 , //空闲状态
WR_BFR1 = 3'd1 , //写BUF1状态
WR_BFR2 = 3'd2 , //写BUF2状态
END_WR = 3'd3 , //写BUF结束状态
RD_BFR1 = 3'd4 , //读BUF1状态
RD_BFR2 = 3'd5 , //读BUF2状态
END_RD = 3'd6 , //结束读状态
RD_BUBBLE= 3'd7 ; //读气泡
wire clk_25mhz ;
//wire locked ;
wire asso_rst_n ;
wire wr_buf1_end ;
wire wr_buf2_end ;
wire rd_buf1_end ;
wire rd_buf2_end ;
wire [15:0] data_o_buf1 ;
wire [15:0] data_o_buf2 ;
reg wea ; //ram写使能信号
reg [2:0] state ;
reg [2:0] next_state ;
reg [3:0] wr_buf1_addr; //写ram1地址
reg [3:0] wr_buf2_addr; //写ram2地址
reg [3:0] read_state ;
reg [3:0] rd_nxt_state;
reg [2:0] rd_buf1_addr; //读ram1地址
reg [2:0] rd_buf2_addr; //读ram1地址
reg wr_end ; //写结束
reg rd_end ; //读结束
assign asso_rst_n = rst_n && locked; //生成一个新的复位信号
always @(posedge clk or negedge asso_rst_n) begin
if(!asso_rst_n) begin
state <= IDLE;
end
else begin
state <= next_state;
end
end
always @(posedge clk_25mhz or negedge asso_rst_n) begin
if(!asso_rst_n) begin
read_state <= IDLE;
end
else begin
read_state <= rd_nxt_state;
end
end
always @(posedge clk or negedge asso_rst_n) begin
if(~asso_rst_n) begin
wea <= 1'b0;
end
else if (next_state == WR_BFR1) begin
wea <= 1'b1;
end
else if (next_state == WR_BFR2) begin
wea <= 1'b0;
end
else begin
wea <= 1'b0;
end
end
always @(posedge clk or negedge asso_rst_n) begin
if(!asso_rst_n) begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
else begin
case(state)
IDLE: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
WR_BFR1: begin
wr_buf1_addr <= (wr_buf1_addr == 4'd15) ? 4'd0 : wr_buf1_addr + 1'b1;
wr_buf2_addr <= 4'd0;
end
WR_BFR2: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= (wr_buf2_addr == 4'd15) ? 4'd0 : wr_buf2_addr + 1'b1;
end
END_WR: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b1;
end
default: begin
wr_buf1_addr <= 4'd0;
wr_buf2_addr <= 4'd0;
wr_end <= 1'b0;
end
endcase
end
end
always @(*) begin
case(state)
IDLE: next_state <= start ? WR_BFR1 : IDLE;
WR_BFR1:next_state <= wr_buf1_end ? WR_BFR2 : WR_BFR1;
WR_BFR2:next_state <= wr_buf2_end ? END_WR : WR_BFR2;
END_WR: next_state <= IDLE;
endcase
end
assign wr_buf1_end = (wr_buf1_addr == 4'd15) ? 1'b1 : 1'b0;
assign wr_buf2_end = (wr_buf2_addr == 4'd15) ? 1'b1 : 1'b0;
assign rd_buf1_end = (rd_buf1_addr == 3'd7) ? 1'b1 : 1'b0;
assign rd_buf2_end = (rd_buf2_addr == 3'd7) ? 1'b1 : 1'b0;
always @(posedge clk_25mhz or negedge asso_rst_n) begin
if(!asso_rst_n) begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
else begin
case(read_state)
IDLE: begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
RD_BFR1: begin
rd_buf1_addr <= (rd_buf1_addr == 3'd7) ? 3'd0 : rd_buf1_addr + 1'b1;
rd_buf2_addr <= 3'd0;
end
RD_BFR2:begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= (rd_buf2_addr == 3'd7) ? 3'd0 : rd_buf2_addr + 1'b1;
end
END_RD:begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b1;
end
default: begin
rd_buf1_addr <= 3'd0;
rd_buf2_addr <= 3'd0;
rd_end <= 1'b0;
end
endcase
end
end
always @(*) begin
case(read_state)
IDLE: rd_nxt_state <= wr_buf1_end ? RD_BFR1 : IDLE;
RD_BFR1:rd_nxt_state <= rd_buf1_end ? RD_BUBBLE : RD_BFR1;
RD_BUBBLE:rd_nxt_state <= RD_BFR2;
RD_BFR2:rd_nxt_state <= rd_buf2_end ? END_RD : RD_BFR2;
END_RD: rd_nxt_state <= IDLE;
endcase
end
//调用时钟锁相环的ip
clk_pll_v1 u_clk_pll (
.clk_in1 (clk) ,
.reset (~rst_n) ,
.locked (locked) ,
.clk_out1 (clk_25mhz)
);
//调用ram的ip
blk_mem_gen_0 buffer1(
.clka (clk) ,
.clkb (clk_25mhz) ,
.wea (wea) ,
.addra (wr_buf1_addr) ,
.addrb (rd_buf1_addr) ,
.dina (data_in) ,
.doutb (data_o_buf1)
);
blk_mem_gen_0 buffer2(
.clka (clk) ,
.clkb (clk_25mhz) ,
.wea (~wea) ,
.addra (wr_buf2_addr) ,
.addrb (rd_buf2_addr) ,
.dina (data_in) ,
.doutb (data_o_buf2)
);
assign data_out = ((read_state == RD_BFR1 && rd_buf1_addr >= 1) || read_state == RD_BUBBLE ) ? data_o_buf1 : (read_state == RD_BFR2) ? data_o_buf2 : 16'd0;
endmodule
testbench如下:
`timescale 1ns/1ns
`define CLK_CYCLE 20
module pingpong_tb();
reg clk ;
reg rst_n ;
reg [7:0] data_in ;
reg start ;
wire [15:0] data_out ;
wire locked ;
pingpong_buffer u_pingpong_buffer(
. clk (clk),
. rst_n (rst_n),
. data_in (data_in),
. start (start),
. data_out (data_out),
. locked (locked)
);
initial begin
clk = 0;
rst_n = 0;
data_in = 8'd0;
start = 1'b0;
#30
rst_n = 1;
#40
@(posedge locked);
start = 1'b1;
#20
start = 1'b0;
repeat(50) begin
data_in = $random() % 256;
@(posedge clk);
end
end
always # (`CLK_CYCLE / 2) clk = ~clk;
endmodule
仿真波形(可见结果正确):

总结
知道了乒乓设计的思想,对于状态机的设计更加熟练了。继续加油!