斯隆奖获得者李博:从博弈论出发,和「偶像」并肩的感觉很好 | 青源专栏

导读:在「STOP」路牌上贴图进行扰动,机器便无法在较远处正确识别路牌。这是李博团队展出在英国科技博物馆的工作,这一类工作关乎现实物理世界中的攻击,在自动驾驶、医疗,甚至日常网站上的恶意交易等领域均有应用。
为了启发下一代青年学者研究思路,激发科研灵感,智源社区推出青源学者访谈栏目。伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学系助理教授、麻省理工学院技术评论 MIT TR-35 、IJCAI计算机与思想奖、斯隆研究奖获得者,青源会会员李博介绍了她一路走来从同济大学,到赴美读博,再到UIUC任教的经历。深度学习方兴未艾之时,她在著名计算机科学家Yevgeniy Vorobeychik教授的指导下,从博弈论入手,开始研究机器学习安全。「到2013年,深度学习大火,之前积累的工作被越来越多的人认可,当时感觉非常高兴,这也是我个人的一个转折点。」
李博,伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学系助理教授。她曾荣获许多学术奖项,包括麻省理工学院技术评论 MIT TR-35 、Alfred P. Sloan 斯隆研究奖、NSF CAREER 奖,IJCAI Computers and Thought Award, Dean's Award for Excellence in Research, C.W. Gear Outstanding Junior Faculty Award,英特尔新星奖、赛门铁克研究实验室奖学金,并获得来自Amazon、Facebook、谷歌、英特尔和 IBM 等科技公司的学术研究奖。她的论文曾获多个顶级机器学习和安全会议的最佳论文奖;研究成果还被永久收藏于英国科技博物馆。她的研究侧重于可信机器学习、计算机安全、机器学习、隐私和博弈论的理论研究和实践分析。她曾设计多个鲁棒性机器学习算法及和隐私保护数据发布系统。她的工作曾被《自然》、《连线》、《财富》和《纽约时报》等主要媒体报道。
借深度学习之东风,走上博弈论的道路
Q:科研的理想是何时树立的?
A:小时候我自己喜欢读书,家长也有这方面的期望,我名字里的“博”字,就代表着父母希望我能比较博学。小时候,我课余时间除了练习钢琴和体操,剩下的时间一般就是看书,学习一些关于计算机、物理、数学的东西,觉得还蛮有意思。其实并没有某一个点让我觉得要当科学家,但是确实一直都还比较喜欢去了解不懂的东西好,学习新的东西,就这样慢慢一步一步走到了现在。
Q:物理和数学的基础对你的科研方向有怎样的影响?
A:高中时期物理老师很喜欢买不同的书作为考试奖励,我高中的时候一般都是年级第一,所以就有机会去选《时间简史》一类的书回来看,这对我帮助很大。我当时最喜欢的学科就是物理和数学,最不喜欢的应该是历史,因为有很多东西需要背。物理、数学,包括政治我都很喜欢,因为逻辑性比较强,需要去思考,哪怕不去背,也可以通过推理得到答案。我认为这些对我之后的研究和工作都有一定的帮助。当前工作的一个比较重要的点,就是如何把人的推理能力与机器学习数据驱动的模型相结合,使得它不容易被攻击。
Q:你是如何走上博弈论研究之路的?
A:我本科阶段开始做研究,写论文、读文献,去尝试理解什么是研究的原则,这些经历对我很有帮助。本科时期对AI安全产生了天然的兴趣,接触了很多计算机入侵、计算机安全这样的问题,也做了很多密码学的工作。读博的时候想做一些机器学习相关的工作,我的导师是Yevgeniy Vorobeychik教授,专注做博弈论。他鼓励我说,你可以做这两者的结合,即机器学习安全(machine learning+security),并从博弈论的角度去分析。另外博后时期,伯克利的宋晓东(Dawn Song)老师对我的影响也很大,她是中国的计算机安全教母,在安全界很有名。
起初,深度学习还没有发展起来,缺少深度学习的配合,机器学习安全这个方向还没有火起来。我从2011年开始做这个课题,到2013年,深度学习大火,之前积累的工作被越来越多的人认可,当时感觉非常高兴,这也是我个人的一个转折点。
AI安全的乐趣——对抗真实物理世界的攻击
Q:为什么选择AI安全这一领域?
A:我目前的研究兴趣,从理论上讲,主要是博弈论和AI的安全与隐私。此外,从实际应用的角度,这当中的方法论有不同的应用。比如我们有与自动驾驶公司的合作,研究自动驾驶的安全性;然后有跟医疗的合作,对医疗影像的分析研究;也有跟eBay,亚马逊这些公司合作,研究关于他们自己的数据,比如分析有没有恶意交易等等。
之所以对安全有兴趣,主要一是有关兴趣,我觉得安全很有意思;二是觉得它很重要,因为不管在AI还是其他领域,安全都是需要注意和保护的。
AI安全有很大乐趣。因为需要你去分析比如那些攻击者会用什么样的策略,从game theory的角度来说,他们会用什么策略,然后defender需要采取什么样的策略,他们博弈的时候最优的策略分别是什么,做这些其实很有意思,需要去思考他们之间的关系,优化他们的行为。
Q:你的代表作有哪些?
A:我博士最后一年,博后的时候开始做自动驾驶领域物理世界的攻击,这个工作从2018年到现在被引用了两千多次,现在正在英国科技博物馆展出。它是第一个证明物理世界的真实系统也会被AI攻击,这是一个代表作。
另一个我觉得比较有趣的代表作certified robustness of FL: https://arxiv.org/abs/2106.08283;reasoning for robust ML: https://arxiv.org/pdf/2003.00120.pdf,把机器人模型和推理结合起来,使得机器学习模型可以得到更高的certified robustness,不止是试验上的安全性,而是对于模型鲁棒性的一种保障。这种鲁棒性系统在自动驾驶,以及诸如eBay、Amazon网站上解决恶意交易等方面均有应用。
还有一个是关于隐私的,对于高维数据的有隐私保障的数据生成具有隐私保护的数据生成模型: https://arxiv.org/pdf/2103.11109.pdf,我们的工作目前在这个领域也是效果最好的。以及一些别的工作,比如在联邦学习上我们做了一系列关于鲁棒性,隐私性,公平性的工作,这个系列也可以算是一个代表作。(参见主页https://aisecure.github.io/)
斯隆奖和IJCAI计算机与思想奖,与「偶像」站在一起
Q:履历中你曾荣获MIT TR-35、斯隆奖等等各类奖项,这些奖项对你的意义是?
A:这些奖本身的区别还是很大的,MIT颁发的35 under 35,注重的是35岁以下的创新人才,同时颁发给学界和工业界。得了这个奖之后会有一些meeting,你会跟其他的学界或者工业界的获奖者一起讨论问题,发现很多新的有趣的问题。2020年我得了这个奖当时很高兴。
2021年我拿到NFF Career,这是美国内部颁发给年轻教授的重要奖项。它是一个为期五年的重要研究奖项。去年我还拿到了斯隆奖,斯隆奖是所有这些奖项里面,我个人感觉最高的一个奖。大家一直说斯隆奖是诺奖风向标,很多得了斯隆奖的人之后的成就都很大,所以我拿这个奖的时候,有一种能跟这些只是看过他们书的人站在一起的感觉。
今年拿到了IJCAI Computers and Thought Award。之前拿到这个奖的一些人,也都是学术界的偶像。“有跟偶像站在一起的感觉”。历年的获奖名单里有比如 Tom Mitchell, Stuart Russel(for senior people),Peter Stone,Andrew Ng等等。

IJCAI Computers and Thought Award获奖现场
每个奖都是对我一部分的肯定,因为每个奖大概都是针对不同阶段的work。这些奖项是对自己工作的肯定,以及更加坚定了这个方向是对的,可以更坚定地做下去。
Q:对之后的研究有什么长期的规划和目标吗?
A:现在所有的机器学习模型都没有很好的把人的逻辑推理经验结合进去,我现在长期的规划,其实就是想把这个结合起来,提升模型的鲁棒性。在这方面我已经做了一些工作,之后也会沿着这个方向继续做。以及应用方面的一些工作,比如自动驾驶,联邦学习这些在真实生活中有应用的东西,如何让他们的鲁棒性、隐私性、公平性从理论的角度有一个保障。
总结来讲,在一些能够实际应用的场景下,能给这些机器学习的应用场景提供可信的保障,这些可信的保障,包括鲁棒性、隐私、公平性的保障。
Q:教学方面,针对学生科研方向的选择,你有什么建议吗?
A:首先我建议要花时间研究不同的人的工作,确定自己喜欢哪一个。确定之后要留足够的时间去读相关文献深入思考研究,因为研究过程肯定会遇到瓶颈,过了这个瓶颈可能就是量变到质变的过程。很多同学在瓶颈的时候就觉得可能对这个方向不是很适合,还是换一个吧。但如果每一个方向都在瓶颈的时候停下来的话,那就不会有质变的过程了。

李博和学生
Q:到了瓶颈之后,如何判断自己是真的不适合,还是可以再努力一下?
A:我觉得最好的就是去跟导师交流,说出问题。中国学生可能不太善于表达,我的大部分外国学生有什么顾虑就会告诉我,我也知道他们的问题,就可以帮他们去判断,毕竟我比较有经验。中国学生有时候不太好意思直接说会有点吃亏,要积极地跟导师表达,一起分析你的问题,可能会得到更多的帮助和指导,我觉得这是比较重要的。
技术解读:基于逻辑推理的可信机器学习
李博在第 20 期青源 Talk 分享了题为「基于逻辑推理的可信机器学习」的报告。介绍了可信机器学习的重大研究价值和前沿进展,以其团队近年来的两点工作为基础,重点讨论了向深度学习模型中引入一阶逻辑和知识的巨大作用。

如今,机器学习技术在现实世界中被广泛应用于自动驾驶、医疗健康、智慧城市、恶意软件分类、欺诈检测、生物识别等领域。在为人类生活提供便利的同时,该技术的兴起也带来了许多新的安全问题。

2016 年,叙利亚的黑客攻击了美联社的推特账户,控制了「Trading Bot」,在短时间内抛售了大量的股票。类似的情况在现实世界中屡见不鲜,例如:机场和一些重要的支付系统采用生物识别、人脸识别系统,这会带来系统安全、数据隐私、数据资产被盗用、身份认证等方面的隐患。此外,与人工智能相关的道德、公平性等方面的问题也有待进一步讨论。

李博老师认为,导致机器学习安全问题的根本原因是:数据分布偏移导致的可信度差异。
从鲁棒性的角度来说,攻击方可以在训练时对数据分布进行操作(例如,数据投毒攻击、后门攻击),也可以在测试时进行对抗样本攻击;防御方则希望缩小或估计出最差情况下的分布偏移导致的可信度差异,确保模型具有一定程度的鲁棒性。
从隐私的角度来说,对于训练好的机器学习模型,或基于此类模型构建的系统,攻击者会通过一些查询动作探查数据分布中的隐私信息,进行会员推理、模型反演等攻击,本质上也是缩小了可信度差异;防御方则旨在使这一差异无法被轻易缩小,也是针对分布偏移展开工作。
从泛化的角度来说,机器学习最终需要针对测试数据分布和训练数据分布之间的差异解决自然的数据偏移问题,在特定条件下优化自然分布的偏移,从而确保模型的泛化性。相较之下,鲁棒性考虑的是最差的情况,而泛化考虑的是自然的情况,后者更加具有普遍意义也更困难。
值得注意的是,以上三个方面之间的联系和交叉是非常重要的,仍然具有广阔的研究空间。例如,李博老师团队的相关工作指出,在联邦学习领域中,如果可以实现用户级/实例级的 (ϵ,δ) 差分隐私,也可以将联邦学习系统对于训练时攻击的鲁棒性视为 (ϵ,δ) 函数。此外,李博老师证明了鲁棒性视角下对抗迁移能力与泛化性视角下的模型迁移能力互为标志。根据这些视角之间的联系,我们可以避免一些重复的研究,将一些视角下的研究进展拓展到其它视角下。
机器学习的鲁棒性

以现实世界中的路标识别为例,此类系统很可能被攻击。通过对抗性攻击,人眼仍能够识别的「停止」路标可能会被识别为「限速 45 码」的路标,导致自动驾驶汽车无法停下;类似的,人眼识别为「右转」的路标可能会被识别为「停止」。在上图中,每一行对应于不同的成像条件(例如,光照、角度、距离),上述攻击在各种条件下都能成功。

在上图所示的目标检测任务中,研究者在「停止」路标早上贴上了一些对抗性的「贴图」从而对网络进行扰动。实验结果表明,电脑、键盘等其他的物体仍然能被正确识别。尽管人类站在远处也能识别「停止」路标,而机器只有距离「停止」路标非常近时才能识别出它,无法满足自动驾驶等场景下的需求。

除了「白盒」环境下的攻击,这种攻击还具有「黑盒」迁移能力。将上述场景下训练的 Faster-RCNN 模型替换为 Yolo 模型,新的模型仍然不能正确识别「停止」路标。我们将这种黑盒攻击方法称为「对抗迁移」,即在模型不可知的情况下采用替代模型进行攻击,进而迁移攻击效果。
李博老师团队在「对抗迁移」领域发表的一系列理论研究工作证明了对抗迁移能力的上/下界,讨论了影响对抗迁移能力的关键因素。他们发现,模型的平滑性和邻近性(梯度距离)对对抗迁移能力有很大的影响,且需要对二者同时进行控制。
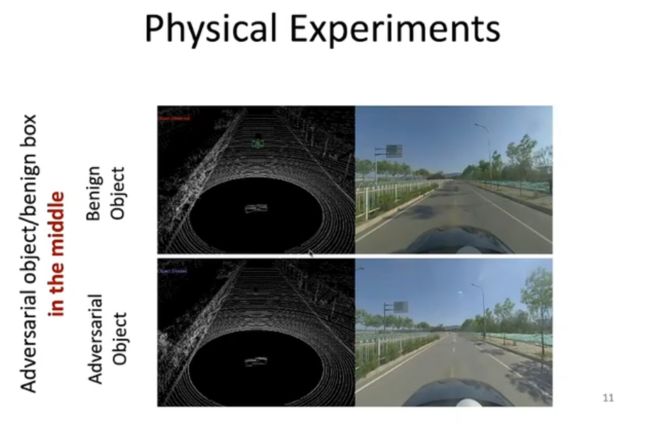
从自动驾驶的角度来说,除了摄像头被攻击导致无法正确识别路标,3D 场景下的物体检测系统也存在被攻击的风险。如上图所示,通过对路中间的良性物体进行优化,可以使 Lidar 无法检测到该物体。在变量控制实验中,如果我们将该物体替换为大小相当的盒子,则检测系统会发现它。
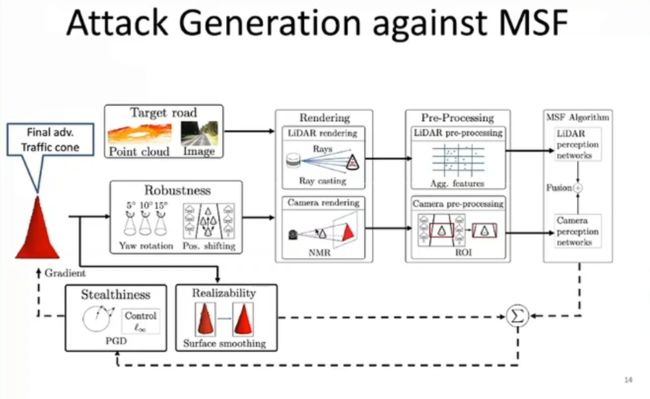
一些学者曾提出通过传感器集成来提升整体自动驾驶系统的鲁棒性。然而,如上图所示,攻击者可以同时针对不同的传感器进行优化,例如:针对摄像头优化纹理,针对 Lidar 优化形状。李博老师团队在百度的 Apollo 5.0 和 LGSVL 自动驾驶仿真平台上测试了对传感器融合系统的攻击,感兴趣的读者可以通过下列链接动手测试更多的多传感器融合攻击案例:https://aisecure.github.io/BLOG/MRF/Home.html

实际上,各种各样的机器学习模型都会受到攻击,防御者面临着巨大挑战。近年来,学者们提出了各种攻击检测/防范方法。然而,大多数此类工作都是从实验的角度出发,缺乏防御最新攻击手段的时效性,导致攻击与防御时刻处于「你追我赶」的循环中,无法停止这种循环。

为此,自 2018 年起,一些学者专注于「机器学习的鲁棒性保障」(cirtified Robustness for ML)研究,从理论上为面临特定攻击下的模型准确率提供了上/下界。例如,如果攻击扰动的 L2/L-∞ 在某个范围内时,可以确保模型准确率在 90% 以上。如此一来,无论攻击形式如何变化,只要攻击扰动满足一定的约束,就可以保证模型的性能。
如上图所示,李博老师团队整理了大多数「机器学习的鲁棒性保障」领域的工作,并在下列网页上构建了排行榜,给出了相关方法的开源代码:https://sokcertifiedrobustness.github.io。他们将「鲁棒性验证方法」分为「完全」和「不完全」两类。「完全」的鲁棒性验证方法可以完全确认模型的鲁棒性,「不完全」的验证方法则无法判断究竟是「保障」方法较弱还是模型本身并不鲁棒。相较之下,「完全」的鲁棒性验证方法更强大,但是计算开销也更大。
目前,此类方法对于攻击条件的限制仍较为苛刻,大多数相关的研究工作仍然在攻击扰动很小的情况下保障模型的鲁棒性,只有「基于概率的验证」分支可以扩展到 ImageNet 数据集上。尽管如此,此类方法只能保障模型具有 27% 左右的准确率,仍然有很大的研究空间。

为了进一步提升可保障的模型性能下限,李博老师认为纯粹数据驱动的方法已经遇到了瓶颈,需要向「鲁棒性保障」领域引入新的思路和额外的信息,例如:域知识、逻辑推理。在 NeurIPS 2021 上,研究者们组织了名为「The NetHack Challege」的挑战赛,获得冠军的参赛者在强化学习系统中引入了域知识。
通过逻辑推理实现鲁棒性
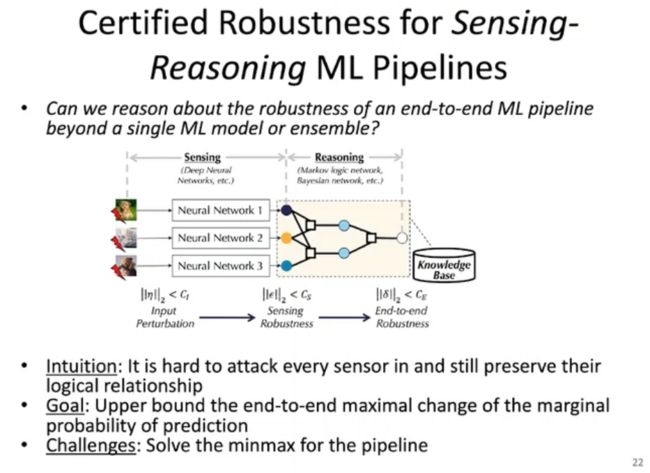
在上图中,李博老师团队提出了一种基于「感知-推理」机制的具有鲁棒性保障的机器学习框架。其中,感知模块为神经网络、支持向量机(SVM)等统计模型,推理模块为马尔科夫逻辑网络(MLN)、贝叶斯网络等概率图模型。感知模块的输出会被输入给推理模块。概率图模型中的连边可以代表某些具体的知识规则。我们不仅要确保基于统计的感知模型在面对满足一定约束的扰动时具有鲁棒性,也需要保证推理模块的鲁棒性,从而得到端到端的鲁棒性保障。
 这一新颖的框架面临着一系列机遇和挑战。从挑战的角度说,概率图模型的计算复杂度往往是 #P-完全的;从机遇的角度说,许多图模型在指数族上定义了一个概率分布,帮助我们求解神经网络难以解决的 min-max 优化问题(例如,最大化攻击扰动、最小化损失函数,求解模型参数)。由于神经网络是非凸、费单调的,这种min-max 问题往往难以求解,而引入推理模块有助于从数学上保障模型的鲁棒性。
这一新颖的框架面临着一系列机遇和挑战。从挑战的角度说,概率图模型的计算复杂度往往是 #P-完全的;从机遇的角度说,许多图模型在指数族上定义了一个概率分布,帮助我们求解神经网络难以解决的 min-max 优化问题(例如,最大化攻击扰动、最小化损失函数,求解模型参数)。由于神经网络是非凸、费单调的,这种min-max 问题往往难以求解,而引入推理模块有助于从数学上保障模型的鲁棒性。
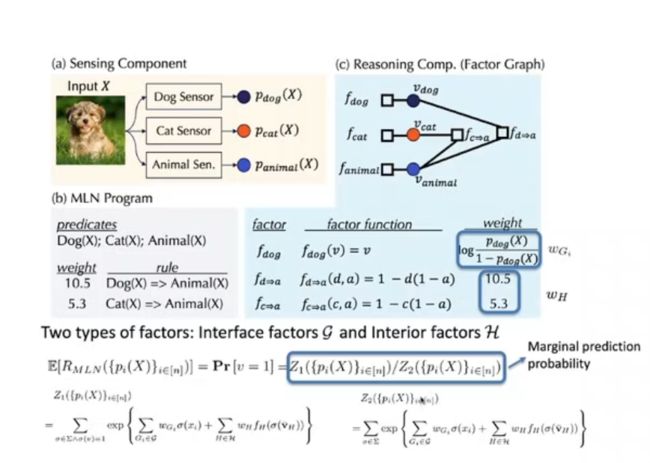
以上图为例,对于一张狗的图片,我们分别通过三个感知模块得到预测结果,第一个感知模块识别图像是否为狗、第二个感知模块识别图像是否为猫、第三个感知模块识别图像是否为动物。在推理模块中,由于猫和狗都属于动物,存在演绎推理的一阶逻辑关系。此时,如果识别猫的感知器被攻击,得到了错误的识别结果,则推理模块会判断出该识别结果违反了知识规则,在端到端推理时会反过来修正感知器得到正确的输出。最终,所有的输出都应该满足知识规则。
在上述框架中,我们要训练各种因子的权重,目标是估计出 MLN 的边缘预测概率的上/下界,从而确保「输入的改变导致的输出改变在一定的区间内」。因子包括接口因子 G 和内部因子 H(规则)。需要估计的边缘预测概率为![]() 。其中,为图模型所有成功的正确预测,为所有可能的情况。
。其中,为图模型所有成功的正确预测,为所有可能的情况。

这一构想非常具有挑战性,我们可以将鲁棒性定义为上图中「定义 3」的形式。在防御和攻击的两种数据分布下,如果我们从攻击中采样一个实例,我们希望预测的概率之差小于 δ。为此,我们可以将著名的技术问题化规为鲁棒性问题。举例而言,MLN 的复杂度是 #P-完全的。

在确定了困难度之后,由于推理过程很复杂,我们给出了如上图所示的理想推理情况(oracle Inference),其中 C 为扰动的上界,λ 为扰动的系数。李博老师指出,当 λ 大于 0 或小于 -1 时, 分别是单调递增或单调递减的,可以在和 处分别取到极大值和极小值。当时,是凸函数,极大值可以在某个端点取到,极小值可以在中的某个端点或梯度为 0 的点取到,从而得到器上/下界。除了 MLN 之外,如果我们用单层神经网络或贝叶斯网络替代上文中的 MLN,也会得到类似的结论。
应用实例
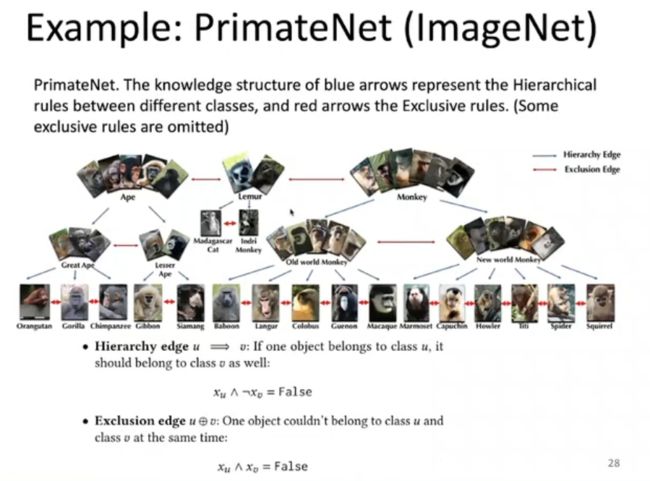
李博老师团队在 PrimateNet 数据集进一步测试了上述框架。PrimateNet 是 ImageNet 的子集,具有很强的可扩展性。该数据集包含灵长类动物之间的层次关系和互斥关系,可以表示为一阶逻辑的形式。李博老师将这种一阶逻辑嵌入到 MLN 中,构建了上述段到段的模型框架。
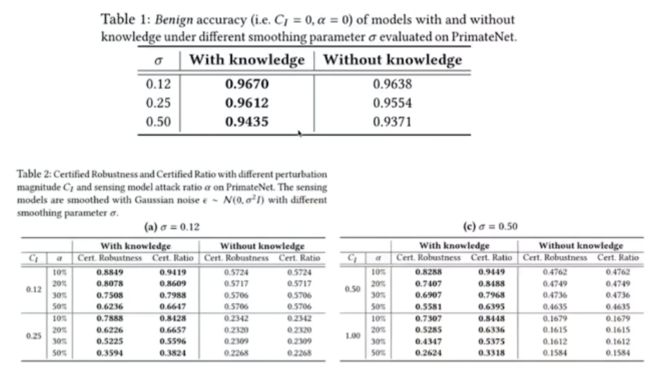
通常,研究者认为模型的鲁棒性和准确率是此消彼长的,存在一定的折中。而实验结果表明,通过加入知识规则,「良性准确率」(Benign Accuracy)也得到了一定的提升。
在表 2 中,「Certified Robustness」和「Certified Ratio」都刻画了扰动前后预测结果的一致性,而前者进一步要求预测结果与真实正确标签相符,σ 为随机平滑的参数。对于各种感知器被攻击的比例,可确保的鲁棒性都较目前最优的方法有 30%-40% 的巨大提升。

由于这一框架是与任务无关的,因此也可以被应用到自然语言处理领域。对于股价预测任务而言,我们可以将新闻中的「开盘价+涨幅=收盘价」信息作为知识。实验结果表明,通过引入知识,可保障鲁棒性具有了巨大的提升,且预测的置信度也很高。
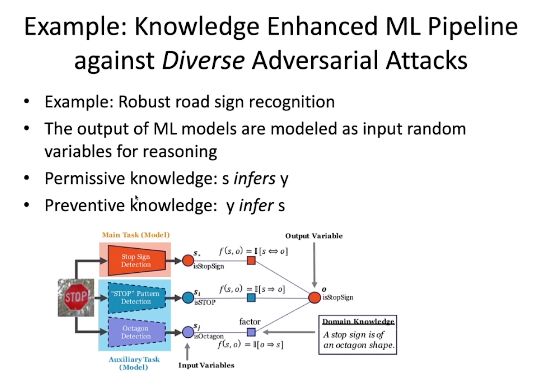
通过知识增强的机器学习框架也可以应对各种不同的对抗性攻击。对于「停止」路标,人类可以通过形状、颜色、文字等特征帮助对于路标的识别。然而,目前的技术还很难将这些特征强加于深度学习模型或统计模型中。为此,李博老师团队考虑通过引入额外的知识来提升模型的性能。
实际上,这些知识与具体的应用紧密相关。在如上图所示的框架中,李博老师设计了一个检测「停止」路标的感知器作为主要任务,并设计了检测「停止」文字和检测八角形的感知器作为辅助任务。这样一来,我们得到了「停止」(s)和「八角形」(o)之间的双向知识。如果主感知器预测图中有「停止」路标,则其形状一定为八角形。此外,我们还可以根据自己的需要加入更多的辅助任务。

李博老师团队从理论上证明了,引入知识后的框架的准确率下界要高于没有知识时的情况。直观上说,我们在训练模型的时候会为不同的模块赋予权重,只要辅助感知器的权重大于零,则表明这些辅助感知器是有用的,此时得到的准确率下界往往由于不引入辅助感知器时的模型准确率下界。

实验结果表明,从「良性准确率」的角度来说,李博老师团队提出的 KEMLP 框架在鲁棒性和准确率上都取得了提升。此外,针对 46 种不同类型的攻击方法(白盒攻击、黑盒攻击、自然情况下的攻击),采用 KEMLP 均可以得到鲁棒准确率的提升,证明了该框架是与任务无关的。
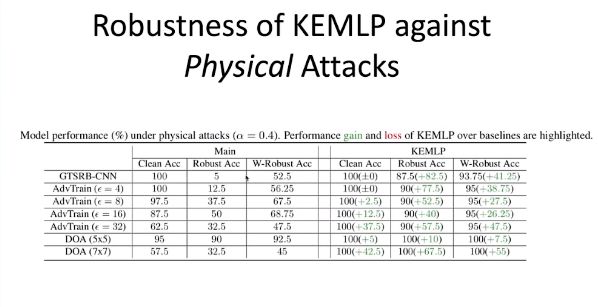
具体而言,针对不同的物理攻击、Lp 攻击、常见数据污染攻击,引入知识后的 KEMLP 框架均可以在 Clean Accuracy、Robust Accuracy、W-Robust Accuracy 等指标上取得一致的、大幅的性能提升(最高高达 82.5)。
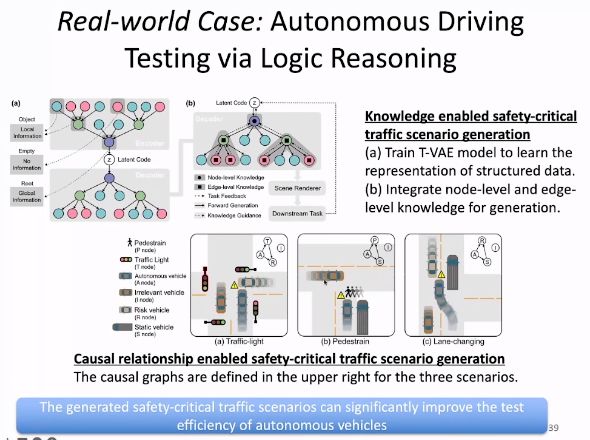
除了提升可保障鲁棒性的模型性能之外,我们还可以将知识引入在现实世界中具有巨大应用价值的生成模型中。例如,在自动驾驶测试任务中,一些与安全紧密相关的情况往往处于长尾分布中,需要生成相应的数据用于模型训练。然而,生成的这些场景需要符合交通规则、人类常识等知识。我们可以通过向生成模型中引入这些物理规则和因果关系,让模型生成的场景满足真实世界的要求。
结语
除了鲁棒性之外,引入知识也有助于提升模型在隐私保护和泛化性上的性能(例如,估计虚假关联)。李博老师指出,理解鲁棒性、隐私、泛化性等不同层面之间的底层关联十分关键。而从方法论的角度来说,引入知识和逻辑推理对于这些层面的研究发展以及理解它们之间的关系是十分有益的。