作为一名大数据工程师你需要掌握Spark深度学习
Tom M. Mitchell教授对于机器学习的定义对深度学习同样适用,深度学习是一种特殊的机器学习,它将现实世界表示为嵌套的层次概念体系(用较简单概念间的联系定义复杂概念,从一般抽象概括到高级抽象表示),从而获得强大的性能与灵活性。常见的深度学习算法有卷积神经网络、循环神经网络、受限波兹曼机等,本章将介绍如何用Spark深度学习框架Deeplearning4j来实现一些深度学习应用。
一般来说,深度学习与通常意义的机器学习还是有所不同,如下。
- 数据量大小,深度学习通常需要更多的样本才能达到更好的效果。因此通常深度学习的训练时间更长。
- 硬件区别,深度学习算法通常涉及大量浮点运算,加之样本量巨大,而GPU天然的海量流处理器架构非常适合并行计算,因此一般复杂的深度学习应用通常需要GPU的硬件架构。
- 特征选择,一般机器学习解决问题时,都需要专家指定或者先验知识来确定特征,如信用模型,这些特征在很大程度上影响了模型的准确性。
- 解决问题的方法,当使用传统机器学习方法解决问题时,经常采取化整为零、分别解决、再合并结果的求解策略。而深度学习主张端到端的模型,输入训练数据,直接输出最终结果,让深度神经网络自己学习如何提取关键特征。比如对一张有着多个目标的照片进行目标检测,需要识别出目标的类别并指出在图中的位置。典型机器学习方法将这个问题分为两步:目标检测与目标识别。首先,使用边框检测技术,扫描全图找到所有可能的对象,对这些对象使用目标识别算法,如支持向量机,识别出相关物体。深度学习方法按照端到端的方式处理这个问题,比如通过卷积神经网络,就能够实现目标的定位与识别,也就是原始图像输入到卷积神经网络模型中,直接输出图像中目标的位置和类别。
- 可解释性,同神经网络算法一样,深度学习模型很难进行解释,这也使深度学习算法无法应用于很多要求模型可解释的场景,如信用风险等。
本章包含以下内容:
- 常见的深度学习框架;
- Deeplearning4j;
- 卷积神经网络;
- 循环神经网络;
- 自动编码器。
1 常见的深度学习框架
作为AI技术的代表,深度学习框架发展势头迅猛,与Spark类似,仍然是以社区支持(开源)+ 公司支持的模式运营。常见的深度学习框架有以下几个。
- TensorFlow:TensorFlow是谷歌公司开源的深度学习框架,支持的接口为Python、C++,可以使用CPU与GPU的计算能力,GPU版本基于NVIDIA的CUDA计算库。TensorFlow 最先没有开源分布式版本,在开源了分布式版本后,很快成为世界上流行的深度学习框架,它抽象优美、接口简洁,但不足的是它还是需要用户编写大量的代码。
- Theano:Theano是历史悠久的深度学习库,由蒙特利尔大学LISA实验室开发。我第一次编写RNN的代码就是使用的Theano,与TensorFlow类似,它也是一个比较底层的框架,它也可以基于CUDA进行运算。
- Keras:Keras是一个比较高层的库,它是基于TensorFlow与Theano进行的封装,让用户能够轻易地构建神经网络。
- Caffe:Caffe 曾经是 CNN 算法最流行的实现框架之一,Caffe 的作者贾扬清也是TensorFlow的作者之一。Caffe的特点是容易上手,使用配置文件定义网络,不需要编写代码,训练速度快,组件模块化,可以方便地拓展到新的模型和学习任务上,支持单机多GPU。
- Torch:Facebook公司的AI研究院使用的就是Torch进行深度学习训练,在被谷歌公司收购之前,AlphaGo的作者DeepMind也使用的Torch。它的编程语言是Lua,这提高了Torch的学习成本。
- MXNet:MXNet是一个支持大多数编程语言的深度学习框架之一,包括 Python、R、C++、Julia 等。MXNet是Amazon AWS的官方深度学习平台。
- Deeplearning4j:简称DL4J,Deeplearning4j由Skymind开发并开源。它的编程接口语言为Java,是广大Java程序员接触深度学习的绝佳工具,它的分布式版本基于Spark,同时也可以基于GPU,并且能很好地与Hadoop生态圈融合。
选择一个合适的深度学习框架通常没有一个固定的答案,更合适的做法是根据当时用户所面临的场景、需要达到的性能、学习成本、硬件成本综合考虑。
2 Deeplearning4j
Deeplearning4j是一个为JVM编写的开源深度学习框架,主要用于商业需求。整体完全用Java编写。由于使用Java的原因,Deeplearning4j在很多Java程序员中比较流行。该框架基本上由与Hadoop和Spark集成的分布式深度学习库组成。在Spark框架的帮助下,我们可以轻松分发模型和海量数据集,并运行多个GPU和CPU来进行并行操作。Deeplearning4j主要在图像、语音、文本、时间序列的模式识别方面取得了巨大成功。除此之外,还可以应用于机器视觉、欺诈检测、业务分析、推荐引擎等各种情况。Deeplearning4j架构如图1所示。

图1 Deeplearning4j架构
Deeplearning4j是基于ND4J进行数值计算的,ND4J也是Skymind开发的Java接口的N维数组计算工具,与Python的Numpy类似,不过底层由C++编写。
Deeplearning4j可以看成是运行在YARN或者Mesos中的Spark作业。Deeplearning4j工作的原理是基于HDFS的数据块进行分布式训练,随着每个节点计算任务的完成,得到的参数会汇总到一个节点求其均值,再分发到各个工作节点更新参数,继续下一轮的训练。
3 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)受启发与视觉皮层生物学原理,改良了传统神经网络模型。Yann LeCun在1998年发表了一篇论文将其运用到了手写字符识别上,并取得了成功。目前卷积神经网络在图像识别领域应用得非常广泛。
3.1 理解卷积神经网络
随着神经科学与生物学的进步,人们发现大脑中的一些个体神经细胞只有在特定方向的边缘存在时才会产生电流,例如,一些神经元只对垂直边缘兴奋,另一些对水平或对角边缘兴奋。人们发现所有这些神经元都以柱状结构的形式进行排列,而且一起工作才能产生视觉感知。这代表了某些神经元细胞只对特定刺激做出回应,这就是卷积神经网络的理论基础。
图 2 来源于经典的卷积神经网络 LeNet,可以看到整个卷积神经网络有输入层、卷积层(C1、C3、C6)、下采样层(S2、S4)、全连接层(F6)以及输出层。

图2 卷积神经网络
输入层是一个32 × 32的手写图像,图中的黑色的5 × 5的小框被称作感受野,这个小框被映射为下一层的一个像素,这个过程被称作卷积,那么这个过程实际发生了什么呢?这其实是图像处理中常见的一种滤波操作,通过不同的卷积核对输入图像(5 × 5)进行过滤,提取出对应图像中的某种特征,如直线、曲线等,不同卷积核过滤的信息都是不同的。简单来说,卷积的过程可以表示为:
a•w
其中a代表感受野中的输入,w被称为一个卷积核或者滤波器,a•w的操作被称为卷积,实际上就是进行了一个向量内积的操作,也就是对应值相乘并求和。下面用一个例子来表示特征过滤的过程,我们假设滤波器是一个如下5 × 5的矩阵:(略)
而输入是一个如下这样的矩阵,同样都是5 × 5的矩阵,可以看出滤波器与输入图像都是一条竖线,不谋而合,那么内积的结果为500。(略)
假设输入是一条横线,如下:(略)
那么滤波的结果为100,这样就通过卷积操作对竖线特征做了一个区分。图7-2中的卷积神经网络的感受野以一个像素的步长进行滑动,C1层选用了6种卷积核,代表了6种特征。从这里可以看出,卷积层的主要目的是提取特征。由于图像的特征是与位置无关的,因此无论卷积核扫过哪一片区域,这个卷积核所包含的权值都是一定的,这样的设计非常合理并且大大降低了需要训练参数的个数。
下采样层是使用了池化(pooling)技术来实现的,目的就是用来减少特征维度并保留有效信息,一定程度上避免过拟合。采样的方式有最大值采样、平均值采样、求和区域采样和随机区域采样等,如图7-3所示。池化也是如此,比如最大值池化、平均值池化、随机池化、求和区域池化等。在图像处理中,采样分为上采样与下采样,简而言之,下采样就是将图片进行缩略,上采样放大图像,以适配更高分辨率的屏幕。

图3 采样
全连接层就是普通神经网络的输入层与隐藏层之间的那种连接方式。也就是说卷积神经网络其实是通过卷积层与下采样层对输入数据进行了提取特征的预处理操作,并将预处理结果作为神经网络的输入层。
输出层神经元的个数取决于需要识别类别的个数,如果是手写字母的话就是52个神经元,激活函数为径向基函数。输出层与上一层采用的连接方式是高斯连接。
3.2 用Deeplearning4j训练卷积神经网络
下面的代码主要是基于LeNet这篇论文实现的CNN,训练数据集为手写字符集MNIST,包含0~9的手写字符。MNIST数据集包含了60 000张手写字符图片,如图4所示。
图4 MNIST数据集
本书附带了原始的MNIST数据集,但是Deeplearning4j读取的数据是带有标签和特征的数据结构(DataSet)。本书已经将jpg格式的图片序列化为所需的格式,转换代码与处理后的数据集随书附在项目中,示例代码如下:
package com.spark.examples.dl;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.deeplearning4j.eval.Evaluation;import org.deeplearning4j.nn.api.OptimizationAlgorithm;import org.deeplearning4j.nn.conf.MultiLayerConfiguration;import org.deeplearning4j.nn.conf.NeuralNetConfiguration;import org.deeplearning4j.nn.conf.Updater;import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;import org.deeplearning4j.nn.conf.layers.DenseLayer;import org.deeplearning4j.nn.conf.layers.OutputLayer;import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;// import org.deeplearning4j.nn.conf.layers.setup.ConvolutionLayerSetup;import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;import org.deeplearning4j.nn.weights.WeightInit;import org.deeplearning4j.optimize.listeners.ScoreIterationListener;import org.deeplearning4j.spark.impl.multilayer.SparkDl4jMultiLayer;import org.deeplearning4j.spark.impl.paramavg.ParameterAveragingTrainingMaster;import org.deeplearning4j.util.ModelSerializer;import org.nd4j.linalg.lossfunctions.LossFunctions;import org.nd4j.linalg.dataset.DataSet;import java.io.IOException;public class CNNMNIST {public static void main(String[] args) throws IOException {SparkConf conf = new SparkConf().setMaster("local[*]").set("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator").setAppName("Mnist Java Spark (Java)");final String imageFilePath = "data/mnistNorm.dat";// 训练次数final int numEpochs = 10;final String modelPath = "your model path";// 一次训练的批大小final int numBatch = 64;JavaSparkContext jsc = new JavaSparkContext(conf);// 从加载HDFS上加载图像JavaRDDjavaRDDImageTrain = jsc.objectFile(imageFilePath); ParameterAveragingTrainingMaster.Builder trainMaster = new ParameterAveragingTrainingMaster.Builder(numBatch).workerPrefetchNumBatches(0).saveUpdater(true).averagingFrequency(5).batchSizePerWorker(numBatch);// 表示单色数据,图片的深度为1int nChannels = 1;// 表示输出的类型个数int outputNum = 10;// 每个batch训练的次数int iterations = 1;int seed = 123;// 构建整个卷积神经网络MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder() // define lenent.seed(seed).iterations(iterations).regularization(true).l2(0.0005).learningRate(0.1).learningRateScoreBasedDecayRate(0.5)// 随机梯度下降.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT).updater(Updater.ADAM).list()// 卷积核大小.layer(0, new ConvolutionLayer.Builder(5, 5).nIn(nChannels).stride(1, 1).nOut(20).weightInit(WeightInit.XAVIER).activation("relu").build()).layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2).build()).layer(2, new ConvolutionLayer.Builder(5, 5).nIn(20).nOut(50).stride(2, 2).weightInit(WeightInit.XAVIER).activation("relu").build())// 最大值池化层.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX).kernelSize(2, 2).build())// ReLU激活函数.layer(4, new DenseLayer.Builder().activation("relu").weightInit(WeightInit.XAVIER).nOut(500).build()).layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD).nOut(outputNum).weightInit(WeightInit.XAVIER).activation("softmax").build()).backprop(true).pretrain(false);MultiLayerConfiguration netconf = builder.build();MultiLayerNetwork net = new MultiLayerNetwork(netconf);net.setListeners(new ScoreIterationListener(1));net.init();SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(jsc, net, trainMaster.build());// 训练卷积神经网络for (int i = 0; i < numEpochs; ++i) {sparkNetwork.fit(javaRDDImageTrain);System.out.println("----- Epoch " + i + " complete -----");Evaluation evalActual = sparkNetwork.evaluate(javaRDDImageTrain);System.out.println(evalActual.stats());}// 保存模型FileSystem hdfs = FileSystem.get(jsc.hadoopConfiguration());Path hdfsPath = new Path(modelPath);FSDataOutputStream outputStream = hdfs.create(hdfsPath);MultiLayerNetwork trainedNet = sparkNetwork.getNetwork();ModelSerializer.writeModel(trainedNet, outputStream, true);}}
4 循环神经网络
循环神经网络(Recurrent Neutral Network,RNN)是一种特别的神经网络,它对于这些复杂的机器学习和深度学习问题提供了许多看似神秘的解决方案。在上一节,我们讨论了卷积神经网络,它专门用于处理X值集合(例如图像矩阵)。同样地,RNN很擅长处理时间序列,如x0, x1, x2, …, xt−1。
4.1 理解循环神经网络
卷积神经网络可以轻易地扩展所识别图像的长宽高和深度。某些卷积神经网络可以处理不同尺寸的图像,而循环神经网络可以轻易地扩展长序列数据,大多数循环神经网络也能处理可变长度的序列数据。为了处理这些带有属性的序列输入,RNN使用它们的内在记忆单元来完成这个工作。RNN通常以微批的形式来操作序列,时间序列包含向量xt,时间步长索引t的范围从0到τ − 1。时间步长索引不仅可以表示现实世界的时间间隔,还能表示序列中的位置。当RNN按照时间展开时,可以被看成一个有着不确定层数的深度神经网络。然而,与普通的深度神经网络相比,RNN的基础功能和架构还是有些不同。对于RNN,层的主要功能是将序列数据存到记忆单元中,而非逐层处理。
如图5所示,xt代表时间序列当前时刻的输入,A代表中间状态信息,存储了ht−1的计算结果,它会参与ht的计算,用一个公式来表示:
![]()
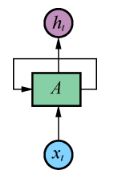
图5 循环神经网络
这个等式很好地说明了循环依赖的关系。我们可以将循环神经网络看成由外部信号xt驱动的动态平衡系统。将图7-6等式左边按照时间展开,如图6等式右边所示。

图6 RNN按照时间展开
从图 7-6 可以看出,前馈神经网络和循环神经网络的主要区别在于反馈回路。反馈回路吸收了自身的输出来作为下一状态的输入。对于输入序列的每个元素都会执行相同的任务,直到时间序列结束。因此,每个隐藏状态的输出结果取决于前面的计算结果。在实际情况中,每个隐藏状态不仅和当前操作的输入序列有关,还和之前的输入序列接收到的信息有关。所以,理想情况下,每个隐藏状态都会包含前面所有输出结果的信息。这种特性需要持久化信息,因此我们说RNN有自己的记忆。这种连续的信息被作为记忆保存在循环网络的隐藏状态中。
图7所示是一个完整的循环神经网络。
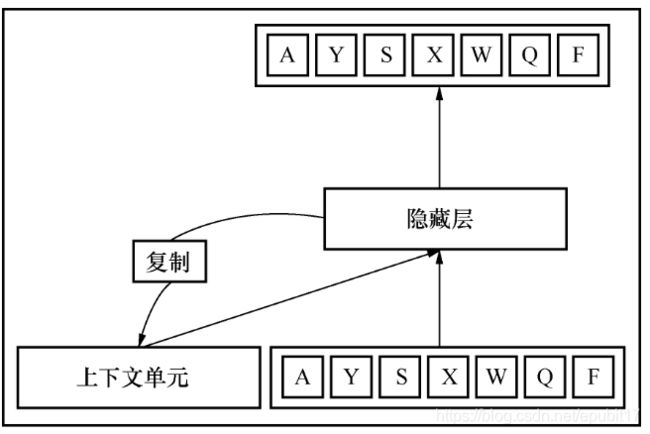
图7 单词序列作为循环神经网络的输入
底部单词序列AYSXWQF表示当前的输入序列。上下文单元,可以被认为是持久化记忆单元,保存了前面时刻输入隐藏层的输出信息。从隐藏层指向上下文单元的反向箭头展示了输出的复制操作,用来计算下一个时刻输入的输出结果。
RNN在t时刻的输出很大程度上取决于在t − 1时刻的输出。因此可以认为与传统神经网络不同,RNN有两个输入源。其中一个输入源就是当前时刻的输入,如图7-8中的x,另一个输入源是从最近的输出接收到的信息,这是从图中的上下文单元中获得的。两个输入源结合起来,决定当前时刻输入的结果。如果我们有一个10个单词的序列,RNN会被展开成一个10层的深度神经网络,每一层对应一个单词,如图8所示。

图8 展开循环神经网络
RNN的计算方法如下。
- 如图7-8所示,xt是在t时刻的输入。图中展示了3个时刻的计算,即t − 1、t和t + 1,输入分别是xt−1、xt和xt+1。例如,向量x1和x2,相当于序列中的第二个单词和第三个单词;
- st表示的是在t时刻的隐藏状态。这个状态在概念上定义了神经网络的记忆,在数学上,st的计算逻辑是
![]()
- 因此,隐藏状态是t时刻的输入xt乘以权值U,加上上一次步长st-1的隐藏状态,乘以其自身的“隐藏状态-隐藏状态”矩阵 W 的函数。“隐藏状态-隐藏状态”矩阵经常被称为状态转移矩阵,与马尔科夫链相似。权值矩阵就像过滤器,决定了过去隐藏状态和当前隐藏状态的重要性。当前状态产生的误差会通过反向传播被发送回去来更新权值,直到误差对于期望值已经最小。为了计算第一个隐藏状态,我们需要s-1的值,一般我们都会将其初始化为0。与传统深度神经网络每层都采用不同参数计算不一样,RNN在所有时间步长中共享相同的参数(这里指的是U、V和W)以计算隐藏层的值。这使得训练神经网络的过程更加容易,因为只需学习更少的参数。权值输入和隐藏状态的总和会通过函数
 进行计算,这通常是非线性的,如sigmoid函数、正切函数或者ReLU(Rectified Liner Units)激活函数。在图7-8中,ot表示为t时刻输入的结果。如下:
进行计算,这通常是非线性的,如sigmoid函数、正切函数或者ReLU(Rectified Liner Units)激活函数。在图7-8中,ot表示为t时刻输入的结果。如下:
![]()
- 然而,在训练阶段,循环权值需要学习哪些信息应该向前传播,而哪些信息应该被排除掉。这也是引起梯度消失与梯度爆炸的问题的起因。这种思考促成了传统RNN的改良,称为长短期记忆(LSTM)。
在20世纪90年代中期,一个拥有某个特殊单元(我们称其为长短期记忆(Long Short Term Memory,LSTM)单元)的RNN改良版本诞生了,它是由德国研究员Sepp Hochreiter和Juergen Schmidhuber提出来防止梯度爆炸或梯度消失问题的。
LSTM有助于维持一个恒定的误差,该误差可以通过时序在网络的每一层进行传播。这种恒定误差的保存使得展开的循环网络能基于一个极其深的神经网络进行学习。这最终打开了一个“通道”,它可以关联到很远之前的原因。例如,在文本处理中,一句话的某个单词的含义可能和几段话之前的一句话有关,LSTM在应对这种场景时,就显得明显优于传统RNN了。
LSTM的架构通过特殊内存单元的内部状态来维持一个恒定的误差流。为了便于理解,图9展示了LSTM的基本框图。

图9 长短期记忆的基本模型
如图9所示,LSTM单元主要由长时间存储信息的存储单元组成。3个专门的神经元控制门——写入门、读取门和遗忘门控制对记忆单元的访问。与计算机的数字存储不同,这些控制门本质上是连续的,范围从0到1。模拟信号对于数字信号有个额外的优点,即它们是可微的,因此,它们可以用于反向传播。LSTM的控制门单元,不是将信息作为输入传给下一个神经元,而是设置其余神经元与记忆单元相连的相应权值。记忆单元基本上都是自连接的线性神经元。当遗忘门被重置(变为0)时,记忆单元将它的内容写给自己,并记住上次记忆的内容。为了让写入记忆单元操作成功,遗忘门和写入门应该被设置为1,这样它就允许写入它的记忆单元任意信息。类似地,当读取门设置为1时,它就会允许网络中其余部分从它的记忆单元读取信息。
如前所述,计算传统RNN梯度下降的问题是,在展开的网络中基于时间进行传播,误差梯度会迅速消失。通过添加LSTM单元,从输出反向传播的误差值会被收集到LSTM单元的记忆单元中。这种现象也被称为误差传输。图7-9所示的是一个LSTM如何克服梯度消失的案例。
图10展示了一个长短期记忆单元按照时间展开。一开始将初始化遗忘门和写入门的值设为1。如图7-10所示,这会将信息K写入记忆单元里。写入后,通过设置遗忘门的值为0来使该值保留在记忆单元里。然后,将读取门的值设置为1,这就可以从存储单元读取并输出值K。从加载K到记忆单元的点再到从记忆单元读取相同的点都遵循根据时间进行反向传播。

图10 长短期记忆按照时间展开,3种门守卫记忆单元
从读取点接收到的误差导数通过网络反向传播,并进行一些变化,直到写入点为止。这样做的原因是由于记忆神经元的线性特性。因此,通过这个操作,我们可以在数以百计的时间步长中维持误差导数而不用受困于梯度消失问题。
LSTM在连续手写识别中取得了已知的最好结果,它也在自动语音识别中取得了成功,并且在全球顶尖的科技公司得到了广泛应用。除了LSTM,还有一些RNN的变体取得了成功,如双向RNN、递归神经网络、CW-RNN(如图11所示)等。

图11 CW-RNN
4.2 用Deeplearning4j训练循环神经网络
下面这段代码实现了一个正负情感分类的 RNN,使用的是谷歌公司新闻语料库(Google News 300),用word2vector算法将数据预处理为300维的特征向量,使用RNN实现对一段话的正负情感判断:
package com.spark.examples.dl;import org.apache.commons.io.FileUtils;import org.apache.commons.io.FilenameUtils;import org.deeplearning4j.eval.Evaluation;import org.deeplearning4j.models.embeddings.loader.WordVectorSerializer;import org.deeplearning4j.models.embeddings.wordvectors.WordVectors;import org.deeplearning4j.nn.conf.GradientNormalization;import org.deeplearning4j.nn.conf.MultiLayerConfiguration;import org.deeplearning4j.nn.conf.NeuralNetConfiguration;import org.deeplearning4j.nn.conf.WorkspaceMode;import org.deeplearning4j.nn.conf.layers.GravesLSTM;import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;import org.deeplearning4j.nn.weights.WeightInit;import org.deeplearning4j.optimize.listeners.ScoreIterationListener;import org.nd4j.linalg.activations.Activation;import org.nd4j.linalg.api.ndarray.INDArray;import org.nd4j.linalg.factory.Nd4j;import org.nd4j.linalg.indexing.NDArrayIndex;import org.nd4j.linalg.learning.config.Adam;import org.nd4j.linalg.lossfunctions.LossFunctions;import com.bbd.bigdata.report.SentimentExampleIterator;import java.io.File;public class Word2VecSentimentRNN {public static final String DATA_PATH = "data/sentiment-rnn";public static final String WORD_VECTORS_PATH = DATA_PATH +"/GoogleNews-vectors-negative300.bin.gz";public static void main(String[] args) throws Exception {// 设置网络参数int batchSize = 64;// 向量长度,根据Google News模型int vectorSize = 300;// 迭代次数int nEpochs = 1;// 大于该长度的文本则截断int truncateReviewsToLength = 256;final int seed = 0;// 设置GC频率,单位毫秒Nd4j.getMemoryManager().setAutoGcWindow(10000);// 配置网络MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().seed(seed).updater(new Adam()).l2(1e-5).weightInit(WeightInit.XAVIER).gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue).gradientNormalizationThreshold(1.0).trainingWorkspaceMode(WorkspaceMode.SEPARATE).inferenceWorkspaceMode(WorkspaceMode.SEPARATE).list().layer(0, new GravesLSTM.Builder().nIn(vectorSize).nOut(256).activation(Activation.TANH).build()).layer(1, new RnnOutputLayer.Builder().activation(Activation.SOFTMAX).lossFunction(LossFunctions.LossFunction.MCXENT).nIn(256).nOut(2).build()).pretrain(false).backprop(true).build();MultiLayerNetwork net = new MultiLayerNetwork(conf);net.init();net.setListeners(new ScoreIterationListener(1));// 读取已训练好的word2vector模型WordVectors wordVectors = WordVectorSerializer.loadStaticModel(new File(WORD_VECTORS_PATH));// SentimentExampleIterator.class将训练集和测试集解析为Dataset,数据集奇数行为负面评论,偶数行为正面评论,解析出标签和特征向量SentimentExampleIterator train = new SentimentExampleIterator(DATA_PATH, wordVectors, batchSize, truncateReviewsToLength, true);SentimentExampleIterator test = new SentimentExampleIterator(DATA_PATH, wordVectors, batchSize, truncateReviewsToLength, false);// 训练System.out.println("Starting training");for (int i = 0; i < nEpochs; i++) {net.fit(train);train.reset();System.out.println("Epoch " + i + " complete. Starting evaluation:");Evaluation evaluation = net.evaluate(test);System.out.println(evaluation.stats());}// 用测试集的一段话来测试下模型输出File firstPositiveReviewFile = new File(FilenameUtils.concat(DATA_PATH, "aclImdb/test/pos/0_10.txt"));String firstPositiveReview = FileUtils.readFileToString(firstPositiveReviewFile);INDArray features = test.loadFeaturesFromString(firstPositiveReview, truncateReviewsToLength);INDArray networkOutput = net.output(features);int timeSeriesLength = networkOutput.size(2);INDArray probabilitiesAtLastWord = networkOutput.get(NDArrayIndex.point(0), NDArrayIndex.all(), NDArrayIndex.point(timeSeriesLength - 1));// 输出判断结果System.out.println("\n\n-------------------------------");System.out.println("First positive review: \n" + firstPositiveReview);System.out.println("\n\nProbabilities at last time step:");System.out.println("p(positive): " + probabilitiesAtLastWord.getDouble(0));System.out.println("p(negative): " + probabilitiesAtLastWord.getDouble(1));System.out.println("----- Example complete -----");}}
5、6(略)
7 小结
Deeplearning4j 是目前流行的分布式深度学习框架之一,它的优点在于对 Java 友好、与Hadoop生态圈无缝融合、文档齐全。作为一名大数据工程师,还是很有必要掌握它,但深度学习框架的选择还是需要根据具体场景具体分析。本章还介绍了 3 个基础的深度学习算法:卷积神经网络、循环神经网络和自动编码器及其Deeplearning4j版的实现。
本文截选自《Spark海量数据处理 技术详解与平台实战》,范东来 著。 
- 基于Spark新版本编写,包含大量的实例
- 用一个完整项目贯穿整个学习过程的实用Spark学习指南
- 层次分明、循序渐进,带你轻松玩转Spark大数据
本书基于Spark发行版2.4.4写作而成,包含大量的实例与一个完整项目,技术理论与实战相结合,层次分明,循序渐进。本书不仅介绍了如何开发Spark应用的基础内容,包括Spark架构、Spark编程、SparkSQL、Spark调优等,还探讨了Structured Streaming、Spark机器学习、Spark图挖掘、Spark深度学习、Alluxio系统等高级主题,同时完整实现了一个企业背景调查系统,借鉴了数据湖与Lambda架构的思想,涵盖了批处理、流处理应用开发,并加入了一些开源组件来满足业务需求。学习该系统可以使读者从实战中巩固所学,并将技术理论与应用实战融会贯通。
本书适合准备学习Spark的开发人员和数据分析师,以及准备将Spark应用到实际项目中的开发人员和管理人员阅读,也适合计算机相关专业的高年级本科生和研究生学习和参考,对于具有一定的Spark使用经验并想进一步提升的数据科学从业者也是很好的参考资料。