高并发day03(zookeeper)
简介
https://apache.org/index.html
https://apache.org/index.html#projects-list
http://zookeeper.apache.org/
一、概述
1.是Apache提供的开源的、用于进行分布式架构的管理的框架
2. Zookeeper是根据Google关于chubby Lock的论文来实现的
二、分布式带来的问题
1.在分布式条件下,为了确定请求访问的对应的主机,那么引入管理节点来实现
2.管理节点如果只有1个容易存在单点故障,那么需要引入管理集群
3.在管理集群中,需要选择一个主节点,需要选举算法
4.当主节点宕机,那么需要从节点来立即切换为主节点5.主从节点之间要进行实时备份
三、安装
1.单机:只在I一个节点上安装,大部分框架的单机模式都只能启动一部分功能
2.伪分布式:在一个节点上安装,利用不同的端口来模拟集群环境,从而启动框架中所有的功能
3.完全分布式:利用集群安装,能够启动框架中所有的服务
1.关闭防火墙
service iptables stop 临时关闭
chkconfig iptables off 永久关闭
2安装JDK
3.下载Zookeeper安装包
https://archive.apache.org/dist/zookeeper/
4.解压:tar -xvf zookeeper-3.4.8.tar.gz
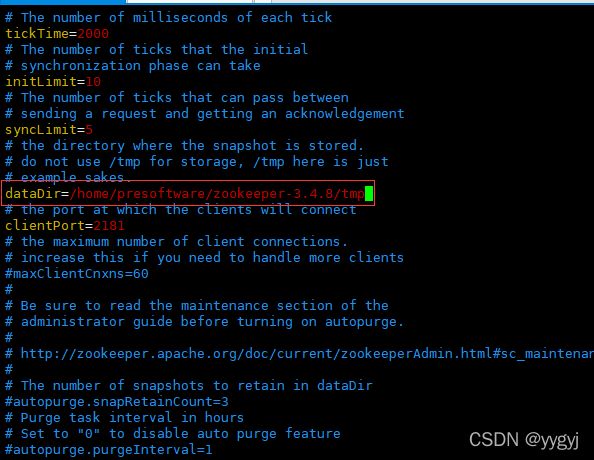
[root@hadoop01 conf]# pwd
/home/presoftware/zookeeper-3.4.8/conf
[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg
zookeeper启动
[root@hadoop01 bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[root@hadoop01 bin]# pwd
/home/presoftware/zookeeper-3.4.8/bin
[root@hadoop01 bin]# sh zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
证明zookeeper没问题【Mode: standalone】
[root@hadoop01 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: standalone
开启客户端
[root@hadoop01 bin]# sh zkCli.sh
关闭zk
[root@hadoop01 bin]# sh zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[root@hadoop01 bin]# pwd
/home/presoftware/zookeeper-3.4.8/bin
关闭进程
[root@hadoop01 bin]# kill -9 进程号
一、特点
1.Zookeeper本身是一个树状结构—Znode树
2.根节点是斜杠(/)
3.每一个子节点称之为是Znode节点
4.在Zookeeper中,每一个子节点都必须存储数据,这个数据往往是对这个节点的描述
5.所有节点的路径都必须从根节点开始计算
6.任意一个持久节点下都可以挂载子节点
7.Znode树维系在内存以及磁盘中—在磁盘中的存储位置由dataDir决定
8.维系在内存中的目的:快速查询
维系在磁盘中的目的:崩溃恢复
9. Zookeeper理论上可以作为缓存服务器使用,但是实际开发中几乎不这么做。Zookeeper本身是做分布式架构的管理和协调的,如果存储大量数据占用大量内存,就会导致管理和协调所能使用的资源减少
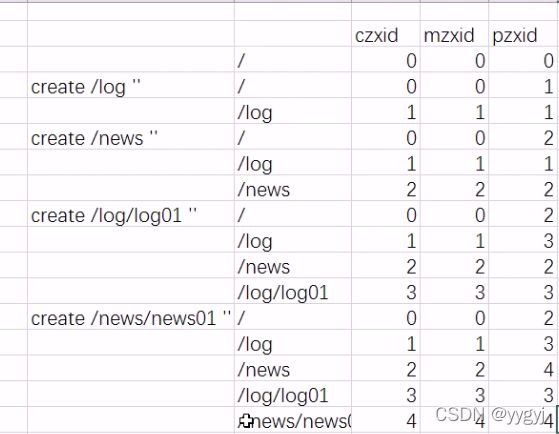
10. Zookeeper会对每一次的写操作(create/set/delete/rmr)分配一个全局递增的编号,这个编号称之为事务新id - Zxid
命令
| 命令 | 解释 |
|---|---|
| ls / | 查看根节点的子节点 |
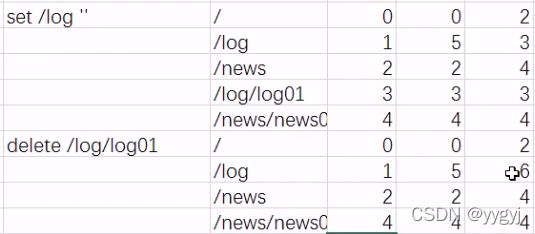
| create /log ‘log servers’ | 在根节点下创建了一个子节点log,log的数据时"log servers" |
| delete /video | 删除/video节点–要求这个节点没有子节点 |
| rmr / log | 递归删除log节点 |
| set /log ‘log’ | 更新log节点的数据为log |
| get /log | 获取log节点的数据以及节点信息 |
三、节点信息
| 信息 | 解释 |
|---|---|
| cZxid | 创建事务id(十六进制) |
| ctime | 创建时间 |
| mZxid | 修改事务id |
| mtime | 修改时间 |
| pZxid | 子节点的事务变化id |
| cversion | 子节点的变化次数 |
| dataVersion | 当前节点的更新次数(set ) |
| aclVersion | 当前节点的权限变化次数 |
| ephemeralOwner | 标记当前节点是否是一个临时节点。如果是持久节点,该属性是0x0;如果是临时节点,该属性是当前的sessionid |
| dataLength | 数据的字节个数 |
| numChildren | 子节点的个数 |
| create -e/node02 | 创建一个临时节点 |
| create -s /log ‘’ | 创建一个顺序节点logxxxxx(持久) |
| create -e -s /log ‘’ | 创建一个顺序节点logxxxxx(临时) |
节点信息
cZxid = 0x2
ctime = Tue Nov 30 19:17:50 CST 2021
mZxid = 0x7
mtime = Tue Nov 30 19:23:57 CST 2021
pZxid = 0x3
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 1
四、节点类型
创建持久节点()
create /node02
创建临时节点(多了一个-e)
create -e/node02
| 持久节点 | 临时节点 | |
|---|---|---|
| 顺序节点 | Persistent_Sequential | Ephemeral_Sequential |
| 非顺序节点 | Persistent | Ephemeral |
package cn.tedu.zookeeper;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;
public class ZookeeperDemo {
ZooKeeper zk;
//连接zookeeper
// @Test
@Before
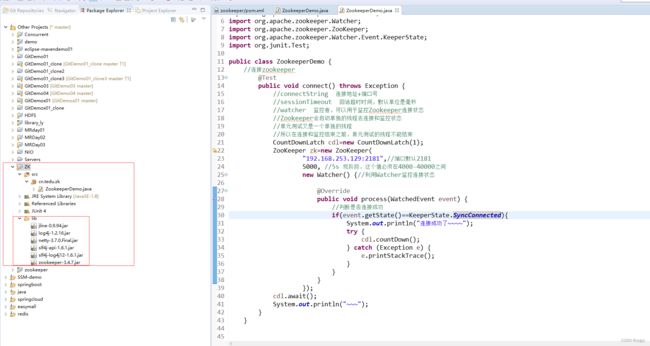
public void connect() throws Exception {
//connectString 连接地址+端口号
//sessionTimeout 回话超时时间,默认单位是毫秒
//watcher 监控者,可以用于监控Zookeeper连接状态
//Zookeeper会启动单独的线程去连接和监控状态
//单元测试又是一个单独的线程
//所以在连接和监控结束之前,单元测试的线程不能结束
CountDownLatch cdl=new CountDownLatch(1);
zk=new ZooKeeper(
"192.168.253.129:2181",//端口默认2181
5000, //5s 现阶段,这个值必须在4000-40000之间
new Watcher() {//利用Watcher监控连接状态
@Override
public void process(WatchedEvent event) {
//判断是否连接成功
if(event.getState()==KeeperState.SyncConnected){
System.out.println("连接成功了~~~~");
try {
cdl.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
cdl.await();
System.out.println("~~~");
}
//创建节点
@Test
public void createNode() throws KeeperException, InterruptedException{
//path, data, acl, createMode, cb, ctx
//path -路径
// data -数据
// acl -权限策略
//createMode -节点类型
//返回值表示节点名字
//节点创建成功返回节点名字
//创建失败无返回--是一个bug,应该有返回失败或null
String name = zk.create("/log", "log_servers".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println(name);
}
//更新数据
@Test
public void setData() throws KeeperException, InterruptedException{
//path, data, version
//path-路径
//data-数据
//version-版本 dataVersion
//更新时候dataVersion会校验,如果一致才更新
//返回值表示节点信息
//如果version 为-1,忽略校验,强制更新
Stat s = zk.setData("/log", "log server".getBytes(), 1);
System.out.println(s);
}
//查询
@Test
public void getData() throws KeeperException, InterruptedException{
//path, watch, stat
//path-路径
//watch -监控着 先为null
//stat -节点信息
//
Stat s=new Stat();
// zk.getData("/log", null, s);
byte[] data = zk.getData("/log", null, null);
System.out.println(new String(data));
}
//删除节点
@Test
public void deleteNode() throws InterruptedException, KeeperException{
//path -路径
//version -1 强制
zk.delete("/log",-1);
}
}
//判断节点是否存在
@Test
public void exists() throws KeeperException, InterruptedException{
//path, watch
//返回值表示节点的信息
//存在返回节点的信息,不存在返回null
Stat s = zk.exists("/log", null);
System.out.println(s);
}
加油吧骚年 20220710~~~~~
非maven工程Java连接zk
新建lib文件,自己导入相应的jar包
zk里有相应的jar包,直接粘过来
线程监控
package cn.tedu.zk;
import java.io.IOException;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.junit.Before;
import org.junit.Test;
public class ZookeeperDemo2 {
//连接zookeeper
ZooKeeper zk;
@Before
public void connect() throws IOException, InterruptedException{
CountDownLatch cdl = new CountDownLatch(1);
zk=new ZooKeeper("192.168.253.129:2181", 5000, new Watcher(){
@Override
public void process(WatchedEvent event) {
// TODO Auto-generated method stub
if(event.getState()==KeeperState.SyncConnected){
System.out.println("连接成功~~~~");
cdl.countDown();
}
}
});
cdl.await();
}
//监控节点的数据是否发生改变
//
@Test
public void dataChanged() throws KeeperException, InterruptedException{
CountDownLatch cdl = new CountDownLatch(1);
zk.getData("/log", new Watcher(){
@Override
public void process(WatchedEvent event) {
// TODO Auto-generated method stub
if(event.getType()==EventType.NodeDataChanged){
System.out.println("节点数据发生改变");
cdl.countDown();
}
}
}, null);
cdl.await();
System.out.println("测试线程结束");
}
//获取子节点
@Test
public void getChildren() throws KeeperException, InterruptedException{
//List放的是子节点的路径
List<String> paths = zk.getChildren("/", null);
for ( String path : paths) {
System.out.println(path);
}
}
//监控一个节点的子节点个数是否发生变化
@Test
public void childrenChanged() throws KeeperException, InterruptedException{
CountDownLatch cdl = new CountDownLatch(1);
zk.getChildren("/", new Watcher(){
@Override
public void process(WatchedEvent event) {
// TODO Auto-generated method stub
if(event.getType()==EventType.NodeChildrenChanged){
System.out.println("子节点发生了变化");
cdl.countDown();
}
}
});
cdl.await();
}
//监听节点变化是增加还是删除
@Test
public void nodeChanged() throws KeeperException, InterruptedException{
CountDownLatch cdl = new CountDownLatch(1);
zk.exists("/log", new Watcher(){
@Override
public void process(WatchedEvent event) {
// TODO Auto-generated method stub
if(event.getType()==EventType.NodeCreated){
System.out.println("节点被创建");
}else if(event.getType()==EventType.NodeDeleted){
System.out.println("节点被删除");
}
cdl.countDown();
}
});
cdl.await();
}
}
zk分布式搭建
删除操作
[root@hadoop01 presoftware]# rm -rf zookeeper-3.4.8
解压
[root@hadoop01 presoftware]# tar -xvf zookeeper-3.4.8.tar.gz
拷贝
[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg
[root@hadoop01 conf]# pwd
/home/presoftware/zookeeper-3.4.8/conf
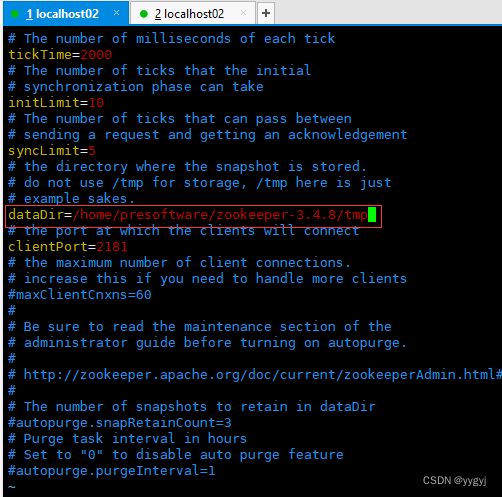
三台主节的ip,端口随意(不重复即可)
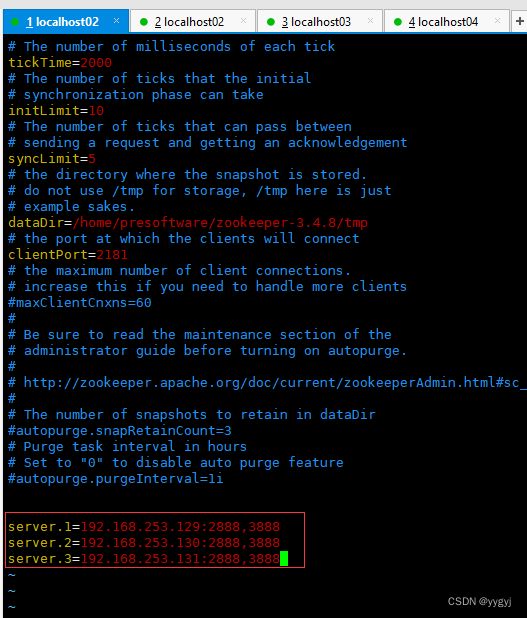
注意冒号
dataDir=/home/presoftware/zookeeper-3.4.8/tmp
server.1=192.168.253.129:2888:3888
server.2=192.168.253.130:2888:3888
server.3=192.168.253.131:2888:3888
[root@hadoop01 zookeeper-3.4.8]# mkdir tmp
[root@hadoop01 zookeeper-3.4.8]# pwd
/home/presoftware/zookeeper-3.4.8
[root@hadoop01 zookeeper-3.4.8]# cd tmp
[root@hadoop01 tmp]# vim myid
服务拷贝(或者xftp)
[root@hadoop01 presoftware]# scp -r zookeeper-3.4.8 root@192.168.253.130:/home/presoftware/
第二台机器
[root@localhost03 tmp]# ls
myid
[root@localhost03 tmp]# vi myid
[root@localhost03 tmp]# pwd
/home/presoftware/zookeeper-3.4.8/tmp
第三台机器
[root@localhost04 tmp]# ls
myid
[root@localhost04 tmp]# vi myid

依次启动三台机器的zk
[root@hadoop01 bin]# sh zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
失败了
[root@localhost04 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
解决关闭另外两台机器防火墙
启动详情(两个follower一个leader)
[root@hadoop01 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower
[root@localhost03 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: leader
[root@localhost04 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/presoftware/zookeeper-3.4.8/bin/../conf/zoo.cfg
Mode: follower
zk选举机制
一、概况
1.第一个阶段:数据恢复阶段
每一个主机(节点)在启动之后,都会先查找当前主机(节点)中的最大事务id
二、选举阶段
刚开始的时候,每一个节点都会选举自己当leader,并且将自己的选举信息发送给其他节点。经过多轮比较之后会选举出一个节点成为leader
二、细节
1.选举信息:
a.最大事务id
b.选举编号-myid
c.逻辑时钟值-用于进行控制所有的节点处在同一轮选举上
2.比较过程
a.先比较两个节点之间的最大事务id,谁的最大事务id大就胜出
b.如果事务id一致,则比较myid,谁的myid大谁就胜出
c.如果一个节点赢过一半及以上的节点那么这个节点就会成为leader-选举的过半性
3.如果leader产生宕机,那么剩余的Zookeeper节点会自动选举出一个新的leader,因此在Zookeeper中不存在单点故障
4.如果在集群中因为分裂而导致出现多个leader的现象称之为脑裂
5.在Zookeeper中,如果存活的节点数量不足整个集群中节点的数量的一版,那么这个时候Zookeeper集群不再选举也不对外提供服务。因此在集群中节点的个数一般为奇数个
6 Zookeeper会对每一次选出的leader分配一个全局的递增编号-epochid。如果集群中出现了多个leader,那么Zookeeper就会kill掉epochid相对较小的leader
7.节点的状态变化
a.looking/voting:选举状态
b.follower:追随者
c.leader:领导者
d.observer:观察者(从始至终不会改变的状态)
8.如果整个集群中已经存在leader,那么新添加的节点的事务id和myid无论是多少只能成为follower