自己标注数据集训练基于pytorch3.7的yolov5手掌识别模型
准备数据集
1. 拍摄
使用iphone 7 Plus连拍功能,拍摄左右手在不同光照下的1000张图片。

2. 图片重新命名
手机自动命名不方便遍历,需要改成1.jpg,2.jpg的形式。运行以下代码。
import os
import re
import sys
path = r"D:data\images"
fileList = os.listdir(path) # 待修改文件夹
print("修改前:" + str(fileList)) # 输出文件夹中包含的文件
os.chdir(path) # 将当前工作目录修改为待修改文件夹的位置
num = 1 # 名称变量
for fileName in fileList: # 遍历文件夹中所有文件
pat = ".+\.(jpg|jpeg|JPG)" # 匹配文件名正则表达式
pattern = re.findall(pat, fileName) # 进行匹配
print('pattern[0]:', pattern)
print('num:', num, 'filename:', fileName)
os.rename(fileName, (str(num) + '.' + pattern[0])) # 文件重新命名
num = num + 1 # 改变编号,继续下一项
print("---------------------------------------------------")
sys.stdin.flush() # 刷新
print("修改后:" + str(os.listdir(path))) # 输出修改后文件夹中包含的文件
所有图片1-1000.jpg
3. 标注数据集
我们在这里使用pascal VOC数据格式,什么是pascal VOC格式。
(1)安装labelImg
傻瓜式pip安装教程
(2)整理data文件夹
yolov5-5.0版本的原始目录下有data文件夹,里面已有文件如下。
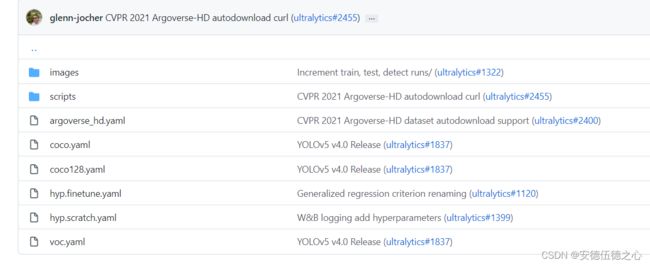
- 删除images文件夹里的原始图像,将用iphone拍的照片全部导入。
- 新建Annotations、ImageSets、labels文件夹。
(3)标注数据
参考1
win键点击Anaconda prompt (Anaconda3)进入命令行,输入
conda activate pytorch3.7
labelImg
conda activate pytorch3.7进入项目环境,输入labelImg打开标注软件。
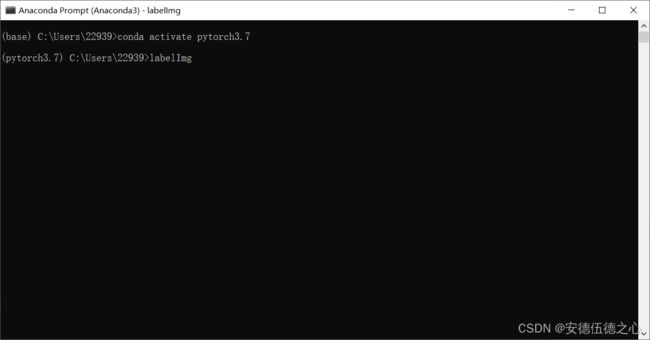
打开成功后如下
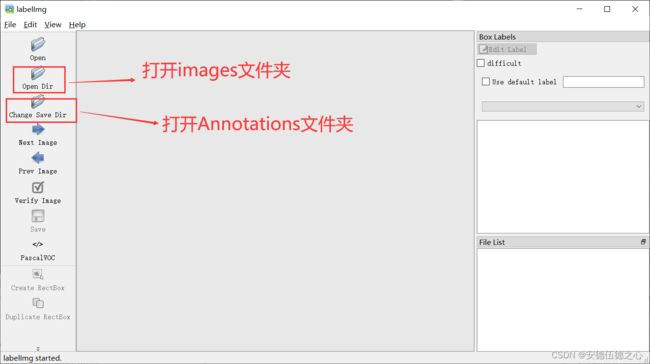
- 打开对应文件夹(如上图)
- 点击左上角View勾选Auto save mode(自动保存)。
- 右侧勾选并输入palm。(如下图)
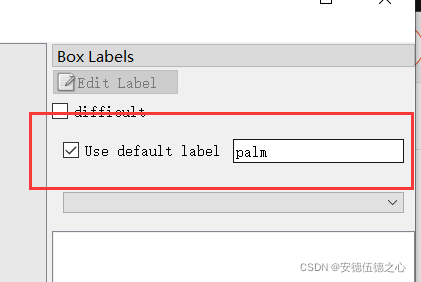
w:开始标注
a:上一张
d:下一张
每标注一张,就会在Annotations文件夹下生成一个.xml文件。
最后会有1000个.xml文件。
4. 划分数据集
参考
(1)将划分好的序号存入.txt
在yolov5-5.0下创建split.py并运行
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在ImageSets下会生成四个文件
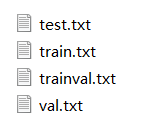
(2)将划分好的完整路径存入.txt
在yolov5-5.0下创建voc_label.py并运行
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['palm']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
注意在这里填入我们的palm类。
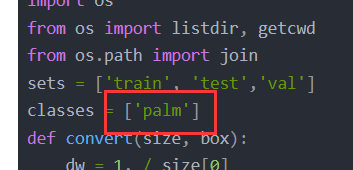
输出:运行后会发现在data文件夹下多了三个.txt:test.txt、train.txt、val.txt.
他们与ImageSets下的区别就是,一个是完整路径,一个是序号。完整路径方便直接读图片。
此外还会在labels文件夹下生成1000个.txt,从1-1000,里面记录每张图片的标签和两个点的信息。由于我们只有一类palm所以标签都是0.
5. 修改配置文件
数据集配置
训练模型
未完待续
一些相关文章
YOLOv5训练及使用(基础详细版)
Yolov5训练自己的数据集(详细完整版)