李宏毅机器学习26—Anomaly Detection
Anomaly Detection 异常侦测
这节课学习了异常侦测,通俗来讲,就是让机器识别出与训练集不同的异常输入。
anomaly detection的主要想法就是将正常数据与异常数据进行分类
anomaly detection分为两大类:训练数据有label和训练数据无label。
对于有label这类,做法是将x输入给分类器,得到一个信心分数,用信心分数的大小,来评价数据是否异常。同时,针对不同的需求,评估分类系统好坏的标准也不同。
对于无label这类,用极大似然估计的方法,求出样本的概率密度函数,当x的概率密度大于λ,为正常数据,反之,为异常数据
目录
一、Anomaly Detection
1.举例说明什么是Anomaly:
2. Anomaly Detection的想法
3. Anomaly Detection的分类
二、有label的情况
1.如何评估信心分数?
2.如何评估分类系统的好坏
3.分类系统的一些其他问题
三、无label的情况
1.做法
2.极大似然估计
总结:
一、Anomaly Detection
首先有训练集x1到xn
我们希望找到一个函数,可以识别出输入x是不是近似于训练数据
如果x近似于训练数据,x就是正常的数据
X不近似于训练数据,那么x就是异常数据。
Anomaly指的是找出与训练数据不同的数据。

1.举例说明什么是Anomaly:
通俗来说,就是与训练数据不同类别的数据

2. Anomaly Detection的想法
训练一个二分类,将正常数据与异常数据分类
以下面的情况为例,采用二分类出现的问题,非宝可梦的数据太多了。没办法把异常数据收集齐。
另一个角度 ,异常数据一般情况下也很难收集。

3. Anomaly Detection的分类
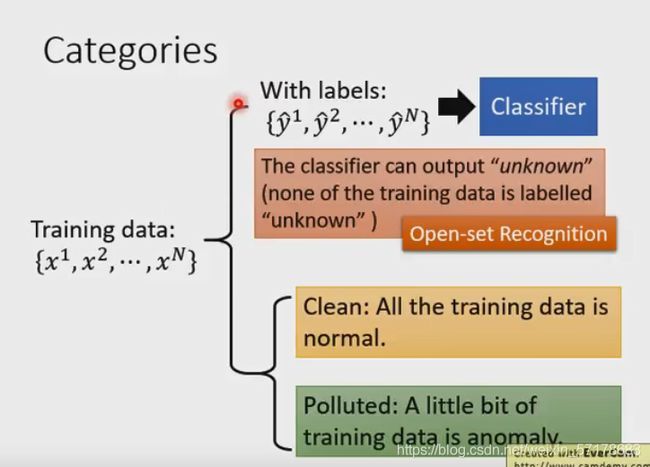
1.每个数据都有label,这样可以进行分类。我们希望这个分类可以让机器输出unknown(当机器看到非训练数据时) 这个叫做open-set recognition
2.所有训练数据时没有label的,这种情况可以分成两类:
1.手上的所有数据都是正常的。
2.手上的一部分数据是正常的。
二、有label的情况
例子:判断人物是否来自于辛普森家庭

输入x,经过分类器,得到一个类别和信心分数。
设定一个λ,信心分数高于λ,为正常数据,反之,为异常数据

1.如何评估信心分数?
将分类器的结果中,取分布结果的最大值
比如下面输入凉宫春日,分类器得到的分布结果很平均,表示机器对分类结果很没有信心

对这个分类器进行了一些测试:
结果还是不错的,是辛普森家庭的人物,得到的信心分数都比较高。

将大量的辛普森家族的人物(1000个data)和非辛普森家族人物的图片(15000个)
输入到分类器中。结果表现的也还不错。

2.如何评估分类系统的好坏
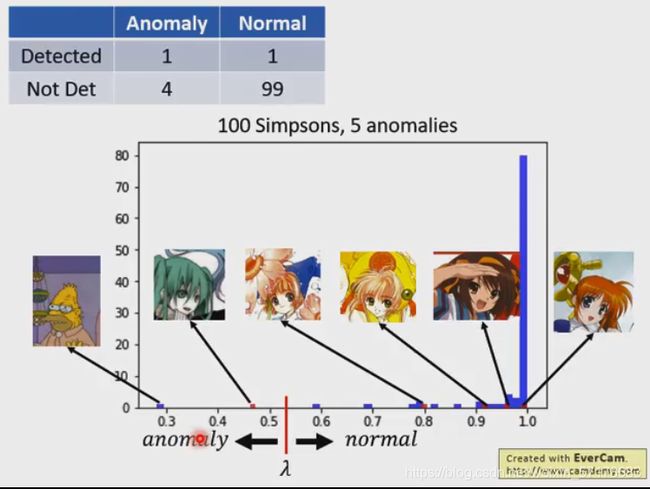
输入100个辛普森家族人物和5个异常数据,得到的信心分数分布
异常数据最大的信心分数是0.998,不过大多数辛普森家族的信心分数都大于0.998
当把λ设置的很小时,得到的正确率很高。(此时,将5个异常数据也当做正常数据 )
虽然这个系统的精确程度很高,但是,这个它的异常数据量太少,没什么用。并不是一个好的分类系统。

将λ取更大值,此时,有1个异常数据被侦测出来,有一个正常数据没有被判断错误
异常数据没有侦测出来:missing。正常数据判断错误:false alarm
继续往右移动λ,得到变化的侦测结果

如何评价上述几种情况,哪个分类系统更好,这个是很难说的,取决于更在意missing还是更在意false alarm。
我们可以用不同的cost table,来评估取不同λ时,系统的好坏。
在cost table A中,false alarm每个扣100,missing每个扣1分。

不同的情况应该选取不同的cost table
例如癌症检测中,应该更重视异常数据未被侦测出来(癌细胞未被侦测出来应该扣更多分),此时应该选取cost table B。
总结:系统的好坏取决于使用系统的背景环境
3.分类系统的一些其他问题
用二分类处理简单的问题是可行的,比如将猫和狗进行分类,根据猫和狗分别的特征进行分类。
但是对于一些没有猫或狗的特征的图片,就会将它们分到边界位置。还有一些动物,会比猫更像猫(从特征角度来看),对于这种动物,比如老虎,虽然是异常数据,但是机器会认为其属于猫的信心分数很高。

之前对辛普森家族的判定,很大程度上是因为人物的脸是黄色的,将异常数据的脸涂成黄色,得到的信心分数就是大幅提高。
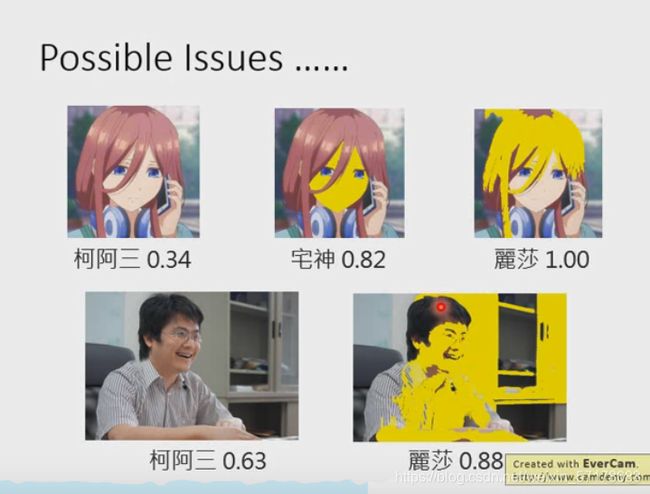
对于异常数据,就给其低的信心分数。但是通常情况,异常数据是不容易收集的。
这时候可以训练一个生成模型去生成异常数据

三、无label的情况
以宝可梦的游戏为例,在一个多人同时操作一个人物的游戏中,大多数人的目的是通关,但是存在少量网络小白,因为种种原因来捣乱,异常侦测的目的就是识别出捣乱的玩家。

1.做法
对于这个问题,首先有一组训练数据x1到xn
每个X是一个玩家。由一个向量组成
向量中的第一维表示说垃圾话的频率,第二维表示无xx状态下的频率。

这组训练数据是没有label的,
我们可以用一个几率模型P(x)来表示某一个玩家的行为影响
如果P(x)大于λ,则表示这个玩家x的行为是正常的。反之,说明这个玩家在捣乱。

将表示所有玩家的二维向量画在平面图上
结果表明这个游戏多数情况下是无政府状态(最大值在0.8),而且多数人也会偶尔说垃圾话(最大值在0.1)
这样左上方的点,它的x1和x2都符合多数人的情况,那么他是正常数据的可能性就比较大,P(x)也会比较大,同理,另外两个点更可能是异常数据,它们的P(x)也会相对较小,
但是对于这两个点,来比较它们的p(x)的大小,我们还是需要数字化的方法来给每个玩家一个分数。这就需要用到极大似然估计。

2.极大似然估计
(这部分在第五节讲过)
数据分布服从概率密度函数fθ(x),θ决定概率密度函数的形状。
θ是未知的,但是可以通过数据求出来。

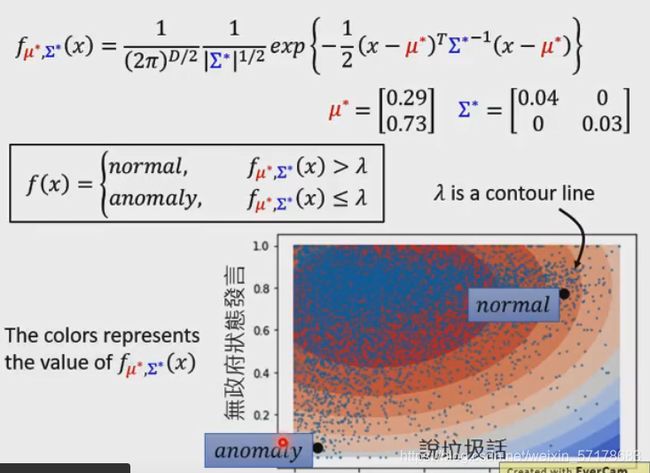
概率密度函数(用高斯分布)
把点的坐标带入到概率密度函数,让L函数最大,得到概率密度函数的形状就是要求的。
μ和∑也有单独的公式求解

不同的环状带表示不同x,fθ(x)的值,蓝色表示捣乱,红色表示正常玩家。
λ就是其中一条环状带的边界。
这里只用了两个维度来评估玩家是否是异常玩家,还可以采用更多的维度来进行评估。
下面的例子就是采用了五个维度,进行计算

总结:
异常侦测的应用非常广泛,下面几项是常见的应用:
1.对银行卡盗刷进行异常检测
2.对网络入侵、网络攻击进行异常检测
3.对于细胞进行侦测,识别出癌细胞
还有其他方法实现anomaly detection
One-class SVM:只需要正常的data,就可以训练出SVM,用来分类正常的data和异常的data。
Isolated forest:给出正常的资料,可以训练出一个模型,告诉你异常资料长什么样子。