【3D点云】算法总结(持续汇总)
文章目录
- 前言
- 一、PointNet++(分类+分割2018)
-
- 1.关键代码
-
- 1.点云采样
- 2.卷积下采样(升维)
- 3.上采样:self.fp4(l3_xyz, l4_xyz, l3_points, l4_points)
- 二、MVF(动态体素融合2019)
-
- 1.动态体素
- 2.特征融合网络结构
- 3.损失函数
- 三、Point RCNN(检测 CVPR2019)
- 四、深度估计的雷达成像(检测 CVPR2019)
- 五、RandLA-Net(分割 2019)
-
- 一、简介
- 二、取样
- 三、局部特征聚合
- 四、补充与实验
- 六、SqueezeSeg V3(分割 2021oral)
-
- 一、投影公式
- 二、SAC卷积
- 三、损失函数
- 四、重点代码
- 七、LiDAR Panoptic Segmentation(全景分割 2021)
- 八、IA-SSD目标检测(2022 CVPR)
-
- 1.摘要
- 2、相关工作(综述)
-
- 1.基于Voxel方法
- 2.基于Point方法
- 3.Point-Voxel方法
- 3.创新点
-
- 1.实例感知下采样策略
- 2.上下文实例质心感知
- 4.实验细节
- 九、RepSurf(CVPR2022 Oral)
-
- 1.点云提取方法
- 2.伪代码
- #、常用点云分割数据集
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、PointNet++(分类+分割2018)
VoxelNet:(苹果2017)
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
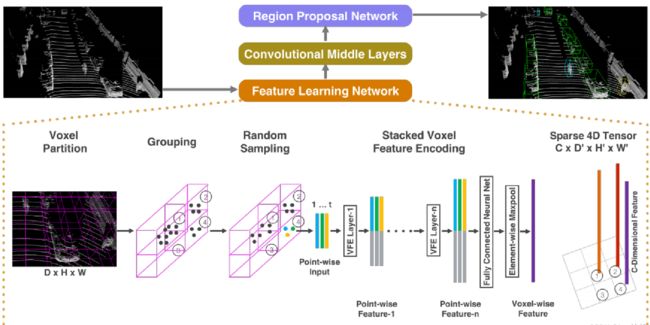
PointPillar:(2019)
- 点云到伪图像的转换
- 2D backbone 网络学习高层次表征
- 检测头进行 3D Box 的检测和回归


Set abstraction 包括 sampling,grouping 和PointNet三部分:
1)sampling:对输入点云进行采样,只保留部分点进入下一层网络。采样数一般是输入点云总数量的一半,
采样算法是Farthest point sampliing (FPS),以保证采样点均匀分布在整个点云集上 。
2)grouping:为每个采样点寻找半径r(r=0.2)范围内的固定k(k=32)个邻域点,所有点坐标都是归一化后的。
3)PointNet:对这些点用PointNet(MLP)提取特征并max pooling 聚合为采样点坐标。
1.关键代码
1.点云采样
1.new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
输入: 1024 0.1 32 (8,4096,3) (8,4096,9) -> 输出: ( 8,1024,3 ) ( 8,1024,32,3+9 )
def sample_and_group(npoint, radius, nsample, xyz, points, returnfps=False):
"""
Input:
npoint 1024:
radius 0.1:
nsample 32:
xyz: input points position data, [B, N, 3] (8,4096,3)
points: input points data, [B, N, D] (8,4096,9)
Return:
new_xyz: sampled points position data, [B, npoint, nsample, 3]
new_points: sampled points data, [B, npoint, nsample, 3+D]
"""
B, N, C = xyz.shape # 8, 4096, 3
S = npoint # 1024
fps_idx = farthest_point_sample(xyz, npoint) # [B=8, 1024, C=1] 最远点采样
new_xyz = index_points(xyz, fps_idx) # ( 8,1024,3 )
idx = query_ball_point(radius, nsample, xyz, new_xyz) # ( 8,1024,32 ) 采样点附近选32个点
grouped_xyz = index_points(xyz, idx) # [B, npoint, nsample, C] (8,4096,3) -- > ( 8,1024,32, 3 )
grouped_xyz_norm = grouped_xyz - new_xyz.view(B, S, 1, C) # ( 8,1024,32, 3 ) 归一化后
if points is not None:
grouped_points = index_points(points, idx) # ( 8,1024,32, 9 )
new_points = torch.cat([grouped_xyz_norm, grouped_points], dim=-1) # [B, npoint, nsample, C+D] ( 8,1024,32,12 )
else:
new_points = grouped_xyz_norm
if returnfps:
return new_xyz, new_points, grouped_xyz, fps_idx # 跳过
else:
return new_xyz, new_points # ( 8,1024,3 ) ( 8,1024,32,3+9 )
1.最远点采样
输入是(bs,4096,3)的点云,输出为( 8,1024 )的索引
def farthest_point_sample(xyz, npoint):
device = xyz.device
B, N, C = xyz.shape # ( 8,4096,3 )
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) # ( 8,1024 ) *[0]
distance = torch.ones(B, N).to(device) * 1e10 # ( 8,4096 ) *[100000]
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) # (8)
batch_indices = torch.arange(B, dtype=torch.long).to(device) # [ 0,1,2,3,4,5,6,7 ]
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
def index_points(points, idx):
device = points.device
B = points.shape[0]
view_shape = list(idx.shape) # [ 8,1024 ]
view_shape[1:] = [1] * (len(view_shape) - 1) # [ 8, 1 ]
repeat_shape = list(idx.shape) # [8,1024]
repeat_shape[0] = 1 # [1,1024]
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape) # (8,1024)
new_points = points[batch_indices, idx, :]
return new_points
2.采样点附近,选最近32个点
xyz是原始点云(4096),new_xyz是采样后点云(1024)
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape # 8, 4096, 3
_, S, _ = new_xyz.shape # 1024
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1]) # (8,1024,4096):[0,1,2,...4095]
sqrdists = square_distance(new_xyz, xyz) # ( 8,1024,4096 )
group_idx[sqrdists > radius ** 2] = N
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample] # ( 8,1024,32 ) 从小到大排序
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
mask = group_idx == N
group_idx[mask] = group_first[mask]
return group_idx # ( 8,1024,32 )
2.卷积下采样(升维)
#----------------------------------1.先定义网路------------------------------------------
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1)) # 这里是(12,32) (32,32) (32,64)
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
#----------------------------------2. forward------------------------------------------
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, nsample,npoint] ( 8,12,32,1024 )
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points))) # ( 8,64,32,1024 )
new_points = torch.max(new_points, 2)[0] # ( 8, 64, 1024 )
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points # (8,3,1024) (8,64,1024)
以上就是如下函数的全部内容:
l1_xyz, l1_points = self.sa1(l0_xyz, l0_points)
随后是:
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points) # (8,3,256) (8,128,256)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points) # (8,3,64) (8,256,64)
l4_xyz, l4_points = self.sa4(l3_xyz, l3_points) # (8,3,16) (8,512,16)
l3_points = self.fp4(l3_xyz, l4_xyz, l3_points, l4_points) # ( 8,256,64 )
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points) # ( 8,256, 256)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points) # (8,128,1024)
l0_points = self.fp1(l0_xyz, l1_xyz, None, l1_points) # (8,128,4096)
x = self.drop1(F.relu(self.bn1(self.conv1(l0_points))))
x = self.conv2(x) # (8,13,4096)
x = F.log_softmax(x, dim=1)
x = x.permute(0, 2, 1) # (8,4096,13)
return x, l4_points
其中, self.sa2同样用到:
new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
其中超参数改为:self.npoint= 256(上一步是1024),self.radius =0.2。其余不变;
self.sa3中:self.npoint= 64,self.radius =0.4。其余不变;
self.sa4中:self.npoint= 16,self.radius =0.8。其余不变;
self.conv1 = nn.Conv1d(128, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, num_classes, 1)
3.上采样:self.fp4(l3_xyz, l4_xyz, l3_points, l4_points)
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N]
xyz2: sampled input points position data, [B, C, S]
points1: input points data, [B, D, N]
points2: input points data, [B, D, S]
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2) # 求2个矩阵距离,函数同上 (8,64,3)(8,16,3) --> (8,64,16)
dists, idx = dists.sort(dim=-1) # (8,64,16)
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3] 取最近的前三个点: (8,64,3)
dist_recip = 1.0 / (dists + 1e-8) # (8,64,3)
norm = torch.sum(dist_recip, dim=2, keepdim=True) # (8,64,1)
weight = dist_recip / norm
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2) # 16个点,找到对应最近(前三名)的64个点,求和:(8,64,512)
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1) # cat(8,64,256),(8,64,512) --> (8,64,768)
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points))) # 再映射回256维
return new_points # ( 8,256,64 )
二、MVF(动态体素融合2019)
论文:End-to-End Multi-View Fusion for 3D Object Detection in Lidar Point Clouds
链接:https://arxiv.org/abs/1910.06528v2
Multi-View Fusion (MVF):两个创新:动态体素 和 特征融合网络结构
1.动态体素
Voxelization and Feature Encoding 体素和特征编码
hard体素化:给定点云P = {p1;::;pN},该过程将N个点分配给大小为 KTF 的缓冲区,其中K为体素的最大数量,T为一个体素的最大的点的数量,F为特征维数。在分组阶段:基于空间的坐标将点{Pi}分配到体素{Vj}.由于一个体素可能被分配了比它的固定点容量T所允许的更多的点,采样阶段子样本从每个体素中抽取固定的T个点。相似的,如果点云产生的体素大于固定体素容量K,则对体素进行降采样。另一方面,当点(体素)比固定容量T (V)少时,缓冲区中未使用的条目将被填充为零。我们称这个过程为硬体素化。

dynamic 体素化 (DV):DV保持了分组阶段的不变,但是,它没有将点采样到固定数量的固定容量体素中,而是保留了点与体素之间的完整映射。因此,体素的数量和每个体素的点的数量都是动态的,这取决于特定的映射函数。这消除了对固定大小缓冲区的需要,并消除了随机点和体素dropout。

2.特征融合网络结构
融合来自不同观点的信息激光雷达点云:鸟瞰视图和透视视图。鸟瞰图是基于笛卡尔坐标系统定义的,在该系统中,物体保持其规范的三维形状信息,并自然可分离。当前的大多数硬体素化的三维物体探测器就是在这种情况下工作的。然而,它的缺点是点云在较长的范围内变得高度稀疏。另一方面,透视视图可以表示LiDAR距离图像密集,并能在球面坐标系中对场景进行相应的平铺。透视图的缺点是对象的形状不是距离不变的,而且在一个杂乱的场景中对象之间可能会大量重叠。因此,最好利用两种观点的互补信息
到目前为止,我们认为每个体素在鸟瞰时都是一个长方体的体积。在这里,我们建议将传统的体素扩展为一个更通用的概念,在我们的例子中,在透视图中包含一个3D截锥体。给定点云f(xi;yi;zi) 定义在笛卡尔坐标系中,其球面坐标表示计算为:
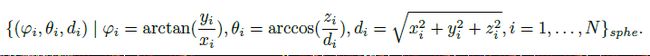

1)提出的MVF首先通过一个全连接(FC)层将每个点嵌入到一个高维特征空间中,该层用于不同的视图(将两个视图的局部坐标和点强度连接起来,然后通过一个全连接(FC)层嵌入到一个128D特征空间中。)
2)然后分别在鸟瞰图和透视图中应用动态体素化,建立点与体素之间的双向映射Fv(Pi) 和 Fp(Vj)
3)接下来,在每个视图中,它使用一个额外的FC层来学习与视图相关的特性,它通过参考Fv(Pi)来最大池来聚合体素信息(FC层:学习64维视图相关的特性)
4)在体素方向的特征图上,它使用一个卷积塔在扩大的接受域内进一步处理上下文信息,同时仍然保持相同的空间分辨率。(卷积塔,就是常用卷积下采样+反卷积。输入、输出都64维)
5)它融合了来自三个不同来源的特征:鸟瞰点对应的笛卡尔体素,透视点对应的球面体素;。
3.损失函数
ground truth 和 anchor box 为:{Xg, Yg, Zg, Lg, Wg, θg},{Xa, Ya, Za, La, Wa, θa}。回归差值表示如下:

anchor的对角线为da ^2 = la^2 + wa^2, 总的回归损失为

评估模型的标准平均精度(AP)指标为7自由度(DOF) 3D box和5自由度BEV box,使用相交超过联合(IoU)阈值,车辆0.7,行人0.5(数据集官网建议)。
实验设置:设置立体像素大小0.32m和检测范围(-74:88)沿着这X轴和Y轴两个类。

waymo开放数据集和KITTI数据集上:视图融合生成了更准确的远程遮挡对象检测。即与BEV相比,透视图体素化可以捕获互补信息,这在对象距离远、采样稀疏的情况下尤其有用。
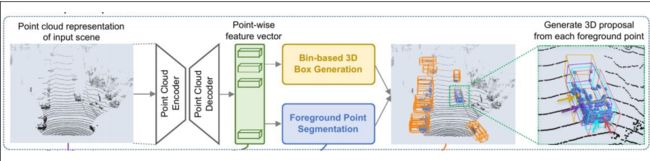
三、Point RCNN(检测 CVPR2019)
论文:PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
Two-stage detector (Faster R-CNN!)
● Stage-1: proposal generation
Stage-II
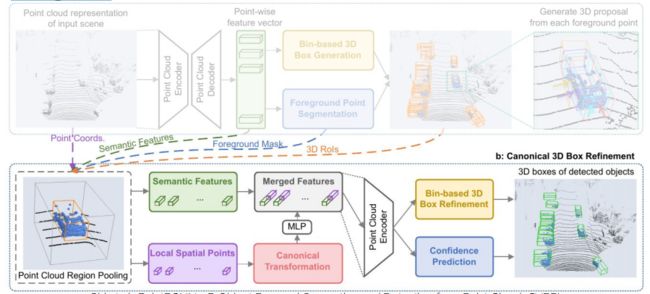
result:
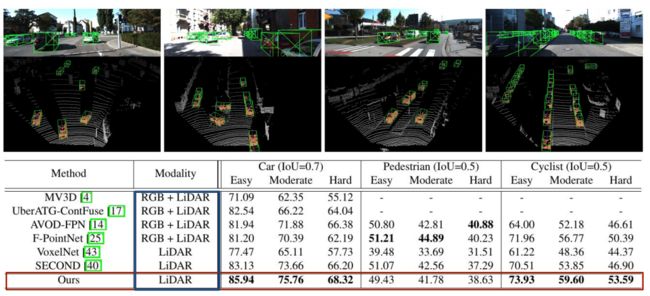
四、深度估计的雷达成像(检测 CVPR2019)
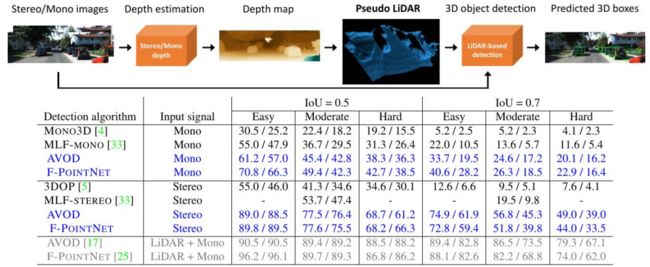
题目:Pseudo-LiDAR from Visual Depth Estimation
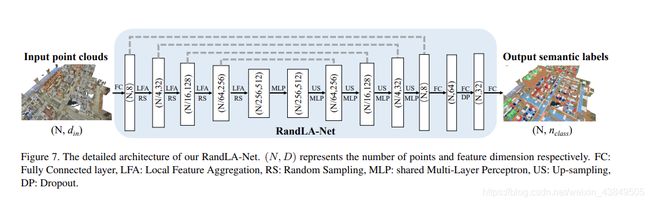
五、RandLA-Net(分割 2019)
Randla-net: Efficient semantic segmentation of large-scale point clouds. arXiv
preprint arXiv:1911.11236 (2019)
一、简介
在大规模的3D点云语义分析中,现有的技术主要是依赖于复杂的取样技术以及包含有繁重计算的预处理和后处理,而 RandLA-Net 是一种 高效而且轻量级 的技术,用在大型的点云中,关键是用 随机点取样 来代替其它复杂的取样技术,由于随机取样可能会带来关键信息的丢失,所以为了防止丢失又引入了局部特征聚合这一关键技术,能够兼顾高效和数据量。
二、取样
点云数据量庞大,需要选取一部分点进行计算,这样在不影响判断的情况下简化数据。现有的取样方式主要是分为两类:
①启发式采样
a-最远点采样(Farthest Point Sampling)
这种采样方式,给我最直观的感受就是一个反向的dijkstra算法,这个算法并不难,首先选择一个初始点a,之后初始化一个距离数组,记录剩下点到这个初试点的距离,选择里面最远的点加入集合,假设加入的点为b,那么现在集合里面有点a和b,之后计算b到所有点的距离,如果这个距离小于距离数组中记录的值,就更新为到b的值,全部更新完之后,将距离最大的点加入集合,重复操作知道采样的数目达到要求。
可见这个距离数组记录的实际上是剩下所有点到集合的最短距离,每次加入集合的点都是最远的点,所以叫最远点采样。这种采样方式在小范围的点云中应用比较广泛,但是如果放在大范围的点云中,缺点也很直观,基本就是一个暴力的运算,这个算法的时间复杂度可以达到o(N2),所以点一旦多了起来,耗时会特别大。所以在大范围的点云中,并不能采用这种方式
b-反密度重要性采样(Inverse Density Importance Sampling)
这种采样方式和名字一样,就是根据密度进行选择,而选择的方式是选择密度低的点。对于这种采样方式,相比于FPS时间复杂度的降低是很明显的,但是由于需要计算密度,对噪音比较敏感。此外尽管时间复杂度已经有了一定的改善,但是对于实时系统而言,仍然是达不到标准。
在论文最后的appendices部分中补充了这里密度计算的方法,给出一个点,密度并不是像物理上那样计算,而是利用距离,这里的密度其实是一个距离和,计算这个点周围的最近的t个点的距离之和作为密度,然后选择点的时候,根据密度的倒数来进行选点,也就是选择密度小的点。
c-随机采样(Random Sampling)
这种采样方式是这片论文所采用的方式,随机采样公平地从所有点中选择一定数目的点,由于是等概率的随机选择,所以时间复杂度是O(1),其计算量与输入点云的总数并没有关系,只与要采样的点的数目有关,在实时性和扩展性上都表现不错,尽管在数据量上还是有一点限制,但是时间复杂度的性能已经优于FPS和IDIS太多。
②基于学习的采样
a-基于生成器的采样(Generator-based Sampling)
与传统的采样方式不同,这种采样方式通过学习生成一个子集来近似表征原始的点云,相当于训练了一个替身,但是缺点也很致命,这种方式在匹配子集的时候需要使用FPS,前面也提到了,FPS的时间复杂度特别大,所以相当于是使用了一个特别费时间的工具去完成一个任务,所以引入了更复杂的过程,时间复杂度也上升了。
b-基于连续松弛的采样(Continuous Relaxation based Sampling)
这种采样方式是用大量的矩阵计算,得到的每个采样点实际上是整个点云的一个加权和。这个方式出发点是好的,但是采用了矩阵去计算,反而导致开销变大了。
c-基于策略梯度的采样(Policy Gradient based Sampling)
本身属于一种马尔可夫决策过程,采用概率分布去进行采样,但是由于采用了排列组合去产生搜索空间,所以当用于大型点云的时候,网络十分难收敛。
总结一下论文中提到的六种采样方式,FPS/IDIS/GS这三种方式在用于大型点云时时间复杂度都太大,CRS需要额外的存储空间,PGS在大型点云的情况下难以收敛。但是正相反,随机采样一方面时间复杂度有着绝对优势,另一方面也不需要额外的存储空间。因此选择随机采样作为算法的一个关键。
三、局部特征聚合
从名字就可以看出来,聚合的是局部的特征,用来防止采用随机采样而将重要数据丢失。局部特征聚合的总图示如下:
局部特征聚合主要是三个部分:局部空间编码、注意力池化和扩张残块。下面记录一下三个部分:
①局部空间编码
这部分的主要目的特征扩充,首先输入的数据是包含各种特征的向量,输出的结果是扩充后的特征向量。
局部空间编码主要是三步:
a 寻找临近点。给定N个点,对每个点使用一次KNN算法,找出欧式距离最近的K个点。
b 相对位置编码。这一部分最好结合图片去理解,根据上面的图示,绿色部分是局部空间编码,其中选中的点利用KNN算法变成了K个点,每个点有3+d个属性,其中3代表三维空间的位置坐标,d代表特征属性,将三维坐标取出来,就是K个三维向量,这些向量做下面的操作:
结合上面的图,这个公式的意思就是将中心点的三维坐标、当前点的三维坐标、相对坐标、欧式距离给连接起来,之后利用MLP对维度进行调整,调整成长d的向量。

c 点特征增强: 将前面扩充的矩阵和原输入矩阵拼接,最后结果是一个k×2d的矩阵。
②注意力池化
经过局部特征编码,我们将一个点变成了一组扩展细节之后的向量(代表着周围一定范围的信息)。随后需要将其整合为一个特征向量。注意力池化主要分为两个步骤:计算注意力值和加权求和。下面分别记录一下两个步骤。

a-计算注意力值
这一部分主要是根据局部特征编码得到的矩阵,计算得到一个新矩阵。论文里面的原话是说需要设计一个共用的函数g(),利用这个函数来学习一个特征向量对应的注意力值,其中在计算过程中需要用到一个共享MLP,所以s_ik的计算应该是下面的式子:
其中W是 共享MLP 的可学习权重。原话为:“Shared MLP 是点云处理网络中的一种说法,强调对点云中的每一个点都采取相同的操作。其本质上与普通MLP没什么不同,其在网络中的作用即为MLP的作用:特征转换、特征提取”。

b-加权求和
这一步主要还是利用前面学习的注意力值来加权求和,注意力值可以看做一个可以自动筛选重要信息的soft mask,将周围点信息进行筛选,得到的就是精简之后的特征向量。特征向量应该按照下面的式子进行计算:

局部信息编码 是扩充信息的过程,将一个点的信息变成了一个范围的点的信息,再经过 注意力池化,将范围的点的信息再次整个为一个向量,也就是用一个点来代表一个范围,从而实现了对范围信息的整合。经过这两个步骤,一开始N个长度为3+d的向量显示变成了N×K×2d的向量组,之后经过注意力池化,变成N个1×d‘的向量,这些向量包含着一开始N个点周围的信息。
③扩张残块
在RandLA-Net中选择使用两轮的局部信息编码和注意力池化。

由于大的点云将大幅向下采样,因此需要显著增加每个点的感知域,这样即使一些点被删除,输入点云的几何细节也更有可能被保留。一般来说采用的轮(一次编码一次池化)数越多,最终得到的点能代表的范围信息就越大,但是轮数过多会牺牲一定的计算效率,而且容易导致过拟合,所以在RandLa-Net中使用两轮就可以了,这样就可以实现效率和效果的平衡。
四、补充与实验
整个RandLA-Net的结构如下,从大的层面上分分成四轮的编码解码、输入、最终语义分割以及网络的输出。这里面的一层实际上对应的是一个箭头,而不是一个方框,方框是经过一层的处理之后数据的规模。解码层,对于每一层,都使用KNN算法来找出每个点的最临近点,使用最临近插值来放大数据。之后将放大后的特征地图与原来的编码后的地图进行拼接。解码完成后就可以进行最后的语义分析(三层的全连接+一层dropout)。
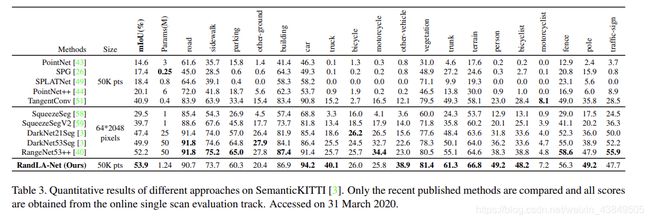
实验采用SemanticKITTL数据集,包含有43552个带有注解的LIDAR扫描数据,分为21个序列,其中10个序列用来训练,1个用来核验,10个用来检测,最终的比较结果为:
六、SqueezeSeg V3(分割 2021oral)
论文:SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation
代码:https://github.com/chenfengxu714/SqueezeSegV3.
1.概述:球形投影 三维点云得到一个二维激光雷达图像,并使用卷积进行处理。整体框架为:

2.解决问题与创新:
提出了空间自适应卷积(SAC),根据输入图像对不同的位置采用不同的滤波器。由于投影后的2D图像的特征分布在不同的图像位置有很大变化:使用标准卷积来处理会有误差,因为卷积滤波器接收到只在图像的特定区域活跃的局部特征。
下面左图显示了COCO2017和CIFAR10中所有图像中红色通道的像素分布情况。右边显示了投影后的2D雷达图像上X坐标上像素的分布。

一、投影公式

(x,y,z)是三维坐标,(p,q)是角坐标,(h,w)是所需的投影地图的高度和宽度,实验中为(64,2048);f=f_up+ f_down是激光雷达传感器的垂直视场,实验中为【-5,1.5】,r=x、y、z的平方和开根号,是每个点的范围。对于投影到(p、q)的每个点,我们使用它对(x、y、z、r)和强度的测量作为特征,并沿着通道维度堆叠它们。
二、SAC卷积
原始卷积:

其中Y∈R(O×S×S)为输出张量,X∈R(I×S×S)为输入张量,W∈R(O×I×K×K)为卷积权值。O、I、S、K分别为输出通道大小、输入通道大小、图像大小和权值的核大小。ˆi=i− K/2,ˆj=j− K/2。σ(·)是一个非线性激活函数。
SAC卷积:被设计为具有空间自适应和内容感知的。根据输入,它调整其滤波器来处理图像的不同部分。

W(·)∈R(O×I×S×S×K×K)是原始输入X_0的函数。它是空间自适应的,因为W取决于位置(p,q)。它是内容感知的,因为W是原始输入x0的函数。以这种一般形式计算W是非常昂贵的,因为W包含太多的元素来计算。为了降低计算成本,我们将W分解为标准卷积权值和空间自适应注意图的乘积,代码如下。
![]()
def forward(self, input):
xyz, new_xyz, feature = input # 输入为3维坐标和32维特征,new_xyz = xyz
N,C,H,W = feature.size()
new_feature = F.unfold(feature, kernel_size = 3, padding = 1).view(N, -1, H, W) # feature:(1, 32, 64, 2048) --> ( 1, 288, 64, 2048 ) 特征重复或扩展
attention = F.sigmoid(self.attention_x(new_xyz)) # 7*7conv: (1, 3, 64, 2048) --> ( 1, 288, 64, 2048 )
new_feature = new_feature * attention
new_feature = self.position_mlp_2(new_feature) # 2*CBR: ( 1, 288, 64, 2048 ) --> ( 1, 32, 64, 2048 )
fuse_feature = new_feature + feature # ( 1, 32, 64, 2048 )
return xyz, new_xyz, fuse_feature # ( 1, 3, 64, 2048 ) ( 1, 3, 64, 2048 ) ( 1, 3, 64, 2048 )
文中还设计了几种SAC卷积变体,代表不同的精度和计算量:

三、损失函数
引入一个多层交叉熵损失来训练所提出的网络,在训练过程中,从阶段1到阶段5,我们在每个阶段的输出中添加一个预测层。对于每个输出,我们分别将GT映射降采样为1x、2x、4x、8x和8x,并使用它们来训练阶段1的输出到阶段5。损失函数可以描述为

四、重点代码
1.球面投影
函数 do_range_projection,在文件 src/common/laserscan.py 中
def do_range_projection(self):
""" Project a pointcloud into a spherical projection image.projection.
Function takes no arguments because it can be also called externally
if the value of the constructor was not set (in case you change your
mind about wanting the projection)
"""
# 雷达参数
fov_up = self.proj_fov_up / 180.0 * np.pi # 视野的up值,固定参数:3/180*pi = 0.0523
fov_down = self.proj_fov_down / 180.0 * np.pi # 视野的 down 值:-25/180*pi = -0.43
fov = abs(fov_down) + abs(fov_up) # 整体视野范围 0.488
# 得到所有点的深度
depth = np.linalg.norm(self.points, 2, axis=1) # (124668) 个点的2范数
# get scan components
scan_x = self.points[:, 0]
scan_y = self.points[:, 1]
scan_z = self.points[:, 2]
# 得到所有点的角度
yaw = -np.arctan2(scan_y, scan_x) # 偏移角 (124668)
pitch = np.arcsin(scan_z / depth) # 仰角 (124668)
# 得到图像坐标系的映射
proj_x = 0.5 * (yaw / np.pi + 1.0) #角度归一化
proj_y = 1.0 - (pitch + abs(fov_down)) / fov # 角度归一化
# 使用角度分辨率,缩放到图像尺寸
proj_x *= self.proj_W # 归一化的角度*2048
proj_y *= self.proj_H # 归一化的角度*64
# round and clamp for use as index
proj_x = np.floor(proj_x)
proj_x = np.minimum(self.proj_W - 1, proj_x)
proj_x = np.maximum(0, proj_x).astype(np.int32) # in [0,W-1]
self.proj_x = np.copy(proj_x) # store a copy in orig order
proj_y = np.floor(proj_y)
proj_y = np.minimum(self.proj_H - 1, proj_y)
proj_y = np.maximum(0, proj_y).astype(np.int32) # in [0,H-1]
self.proj_y = np.copy(proj_y) # stope a copy in original order
# 投影前的点云深度(npoints,1)
self.unproj_range = np.copy(depth)
# 根据点云 depth 做降序排列
indices = np.arange(depth.shape[0]) # [0,1,2,3,4...124668]
order = np.argsort(depth)[::-1] # (124668)*index : 点云按照由远到近排序
depth = depth[order]
indices = indices[order]
points = self.points[order]
remission = self.remissions[order]
proj_y = proj_y[order]
proj_x = proj_x[order]
# assing to images
# 重构的图像从左上角(0,0)到右下角(63,2048),depth值由大到小。
# 没有depth值的地方填充-1。若坐标重复(偏移角与仰角接近),则近的点会替代远的
self.proj_range[proj_y, proj_x] = depth # ( 64, 2048 )
self.proj_xyz[proj_y, proj_x] = points # ( 64, 2048, 3 )
self.proj_remission[proj_y, proj_x] = remission # ( 64, 2048 )
self.proj_idx[proj_y, proj_x] = indices # ( 64, 2048 )
self.proj_mask = (self.proj_idx > 0).astype(np.int32) # ( 64, 2048 )
2.数据预处理
在迭代过程中,一个输入点云经过预处理,会产生8个变量:
src/tasks/semantic/dataset/kitti/parser.py
scan = LaserScan(project=True,
H=self.sensor_img_H,
W=self.sensor_img_W,
fov_up=self.sensor_fov_up,
fov_down=self.sensor_fov_down)
# 打开点云文件
scan.open_scan(scan_file)
if self.gt:
scan.open_label(label_file)
# 将标签映射到【0~19】 (also for projection)
scan.sem_label = self.map(scan.sem_label, self.learning_map)
scan.proj_sem_label = self.map(scan.proj_sem_label, self.learning_map)
# 按照张量维度,初始化8个变量
unproj_n_points = scan.points.shape[0] # 124668
unproj_xyz = torch.full((self.max_points, 3), -1.0, dtype=torch.float) # 15000
unproj_xyz[:unproj_n_points] = torch.from_numpy(scan.points)
unproj_range = torch.full([self.max_points], -1.0, dtype=torch.float)
unproj_range[:unproj_n_points] = torch.from_numpy(scan.unproj_range)
unproj_remissions = torch.full([self.max_points], -1.0, dtype=torch.float)
unproj_remissions[:unproj_n_points] = torch.from_numpy(scan.remissions)
if self.gt:
unproj_labels = torch.full([self.max_points], -1.0, dtype=torch.int32)
unproj_labels[:unproj_n_points] = torch.from_numpy(scan.sem_label)
else:
unproj_labels = []
# 得到点和标签(利用上一步的球面投影)
proj_range = torch.from_numpy(scan.proj_range).clone() # ( 64, 2048 )
proj_xyz = torch.from_numpy(scan.proj_xyz).clone() # ( 64, 2048, 3 )
proj_remission = torch.from_numpy(scan.proj_remission).clone() # ( 64, 2048 )
proj_mask = torch.from_numpy(scan.proj_mask) # ( 64, 2048 )
if self.gt:
proj_labels = torch.from_numpy(scan.proj_sem_label).clone()
proj_labels = proj_labels * proj_mask
else:
proj_labels = []
proj_x = torch.full([self.max_points], -1, dtype=torch.long) # (15000)* -1
proj_x[:unproj_n_points] = torch.from_numpy(scan.proj_x)
proj_y = torch.full([self.max_points], -1, dtype=torch.long)
proj_y[:unproj_n_points] = torch.from_numpy(scan.proj_y)
proj = torch.cat([proj_range.unsqueeze(0).clone(),
proj_xyz.clone().permute(2,0,1),
proj_remission.unsqueeze(0).clone()]) # 深度、坐标、强度拼接成5维 (5,64,2048)
proj = (proj - self.sensor_img_means[:, None, None]) / self.sensor_img_stds[:, None, None] # 归一化
proj = proj * proj_mask.float()
# get name and sequence
path_norm = os.path.normpath(scan_file)
path_split = path_norm.split(os.sep)
path_seq = path_split[-3]
path_name = path_split[-1].replace(".bin", ".label")
return proj, proj_mask, proj_labels, unproj_labels, path_seq, path_name, \
proj_x, proj_y, proj_range, unproj_range, proj_xyz, unproj_xyz, proj_remission, unproj_remissions, unproj_n_points
3.主函数
for i, (proj_in, proj_mask, _, _, path_seq, path_name, p_x, p_y, proj_range, unproj_range, _, _, _, _, npoints) in enumerate(loader):
proj_output, _, _, _, _ = self.model(proj_in, proj_mask) # ( 1, 5, 64, 2048 ) --> (1, 20, 64, 2048)
proj_argmax = proj_output[0].argmax(dim=0) # ( 64, 2048 )
if self.post:
# knn后处理,可以提升检测结果的精度
unproj_argmax = self.post(proj_range, unproj_range, proj_argmax, p_x, p_y)
else:
# put in original pointcloud using indexes
unproj_argmax = proj_argmax[p_y, p_x]
if torch.cuda.is_available():
torch.cuda.synchronize()
print("Infered seq", path_seq, "scan", path_name,
"in", time.time() - end, "sec")
end = time.time()
# save scan
# get the first scan in batch and project scan
pred_np = unproj_argmax.cpu().numpy()
pred_np = pred_np.reshape((-1)).astype(np.int32)
# map to original label
pred_np = to_orig_fn(pred_np) # 从[0-19]映射回原来类别
# save scan
path = os.path.join(self.logdir, "sequences",
path_seq, "predictions", path_name) # sample_output/sequences/00/predictions/000000.label'
pred_np.tofile(path)
depth = (cv2.normalize(proj_in[0][0].cpu().numpy(), None, alpha=0, beta=1,
norm_type=cv2.NORM_MINMAX,
dtype=cv2.CV_32F) * 255.0).astype(np.uint8) # ( 64,2048 )
print(depth.shape, proj_mask.shape,proj_argmax.shape)
out_img = cv2.applyColorMap(
depth, Trainer.get_mpl_colormap('viridis')) * proj_mask[0].cpu().numpy()[..., None]
# make label prediction
pred_color = self.parser.to_color((proj_argmax.cpu().numpy() * proj_mask[0].cpu().numpy()).astype(np.int32)) # ( 64,2048,3 )
out_img = np.concatenate([out_img, pred_color], axis=0) # (128,2048,3)
print(path)
cv2.imwrite(path[:-6]+'.png',out_img)
4.KNN后处理
原理:将预测结果与周围最近的7个点预测值放在一起,进行投票。类别数最多的class代表盖点的类别。
class KNN(nn.Module):
def __init__(self, params, nclasses):
super().__init__()
print("*"*80)
print("Cleaning point-clouds with kNN post-processing")
self.knn = params["knn"]
self.search = params["search"]
self.sigma = params["sigma"]
self.cutoff = params["cutoff"]
self.nclasses = nclasses
print("kNN parameters:")
print("knn:", self.knn)
print("search:", self.search)
print("sigma:", self.sigma)
print("cutoff:", self.cutoff)
print("nclasses:", self.nclasses)
print("*"*80)
def forward(self, proj_range, unproj_range, proj_argmax, px, py):
''' Warning! Only works for un-batched pointclouds.
If they come batched we need to iterate over the batch dimension or do
something REALLY smart to handle unaligned number of points in memory
'''
# get device
if proj_range.is_cuda:
device = torch.device("cuda")
else:
device = torch.device("cpu")
# sizes of projection scan
H, W = proj_range.shape # 64, 2048
# number of points
P = unproj_range.shape # 124668
# check if size of kernel is odd and complain
if (self.search % 2 == 0):
raise ValueError("Nearest neighbor kernel must be odd number")
# calculate padding
pad = int((self.search - 1) / 2) # 3
# unfold neighborhood to get nearest neighbors for each pixel (range image)
proj_unfold_k_rang = F.unfold(proj_range[None, None, ...],
kernel_size=(self.search, self.search),
padding=(pad, pad)) # ( 1, 49, 64, 2048 )--># ( 1, 49, 131072)
# index with px, py to get ALL the pcld points
idx_list = py * W + px # (124668): 64*2048 =131072个图像点中的索引
unproj_unfold_k_rang = proj_unfold_k_rang[:, :, idx_list] # ( 1, 49, 124668 )
# WARNING, THIS IS A HACK
# Make non valid (<0) range points extremely big so that there is no screwing
# up the nn self.search
unproj_unfold_k_rang[unproj_unfold_k_rang < 0] = float("inf") # depth: ( 1, 49, 124668 ) 其中(781331)* inf
# now the matrix is unfolded TOTALLY, replace the middle points with the actual range points
center = int(((self.search * self.search) - 1) / 2) # 24
unproj_unfold_k_rang[:, center, :] = unproj_range # ( 1, 49, 124668 ) : 49中的第24为depth(124668)
# now compare range
k2_distances = torch.abs(unproj_unfold_k_rang - unproj_range) # ( 1, 49, 124668 )
# make a kernel to weigh the ranges according to distance in (x,y)
# I make this 1 - kernel because I want distances that are close in (x,y)
# to matter more
inv_gauss_k = (
1 - get_gaussian_kernel(self.search, self.sigma, 1)).view(1, -1, 1)
inv_gauss_k = inv_gauss_k.to(device).type(proj_range.type()) # (1,49,1): 生成 7*7高斯核,最外侧为1,中心为0.84
# apply weighing
k2_distances = k2_distances * inv_gauss_k # ( 1, 49, 124668 )
# find nearest neighbors
_, knn_idx = k2_distances.topk(
self.knn, dim=1, largest=False, sorted=False) # ( 1, 7, 124668 )
# do the same unfolding with the argmax
proj_unfold_1_argmax = F.unfold(proj_argmax[None, None, ...].float(),
kernel_size=(self.search, self.search),
padding=(pad, pad)).long() # (1,64,2048) --> (1,49,64,2048) --> (1,49, 131072) 每个点的预测类别
unproj_unfold_1_argmax = proj_unfold_1_argmax[:, :, idx_list] # ( 1, 49, 124668 ) 每个点(及其周围49个点) 的预测类别
# get the top k predictions from the knn at each pixel
knn_argmax = torch.gather(
input=unproj_unfold_1_argmax, dim=1, index=knn_idx) # ( 1, 7, 124668 ) : 7*7=49的范围内,找到depth距离最近的7个点
# fake an invalid argmax of classes + 1 for all cutoff items
if self.cutoff > 0:
knn_distances = torch.gather(input=k2_distances, dim=1, index=knn_idx) # ( 1, 7, 124668 ):排名前7的点到中心点的depth距离
knn_invalid_idx = knn_distances > self.cutoff # ( 1, 7, 124668 )
knn_argmax[knn_invalid_idx] = self.nclasses # 距离大于1的,类别设置为20
# now vote
# argmax onehot has an extra class for objects after cutoff
knn_argmax_onehot = torch.zeros(
(1, self.nclasses + 1, P[0]), device=device).type(proj_range.type()) # ( 1, 21, 124668 )
ones = torch.ones_like(knn_argmax).type(proj_range.type()) # ( 1, 7, 124668 )
knn_argmax_onehot = knn_argmax_onehot.scatter_add_(1, knn_argmax, ones) # ( 1, 21, 124668 ) 将7个点的类别,分别分配到对应的21个类别当中
# now vote (as a sum over the onehot shit) (don't let it choose unlabeled OR invalid)
knn_argmax_out = knn_argmax_onehot[:, 1:-1].argmax(dim=1) + 1 # ( 1, 124668 )
# reshape again
knn_argmax_out = knn_argmax_out.view(P)
return knn_argmax_out # (124668)
七、LiDAR Panoptic Segmentation(全景分割 2021)
A Benchmark for LiDAR-based Panoptic Segmentation based on KITTI, arXiv:2003.02371

八、IA-SSD目标检测(2022 CVPR)
题目:End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds
论文:https://arxiv.org/abs/1910.06528v2
1.摘要
对于detector(即预测7自由度的三维box框,包括三维位置、三维尺寸、方向和类别标签)来说,前景点本质上比背景点更重要。基于此,论文提出了一种高效的单级基于point的3D目标检测器,称为IA-SSD:利用两种可学习的, 面向任务、实例感知 的下采样策略来分层选择属于感兴趣对象的前景点。此外,还引入了上下文质心感知模块,以进一步估计精确的实例中心。为了提高效率,论文按照 纯编码器 架构构建了IA-SSD。
由于三维点云的非结构化和无序性质,早期的工作通常首先将原始点云转换为中间规则表示,包括将三维点云投影到鸟瞰视图或正面视图的二维图像,或转换为密集的三维体素(3D-2D投影或体素化引入了量化误差),基于点的pipeline,许多重要的前景点在最终的边界框回归步骤之前被丢弃。
在kitti数据集上:
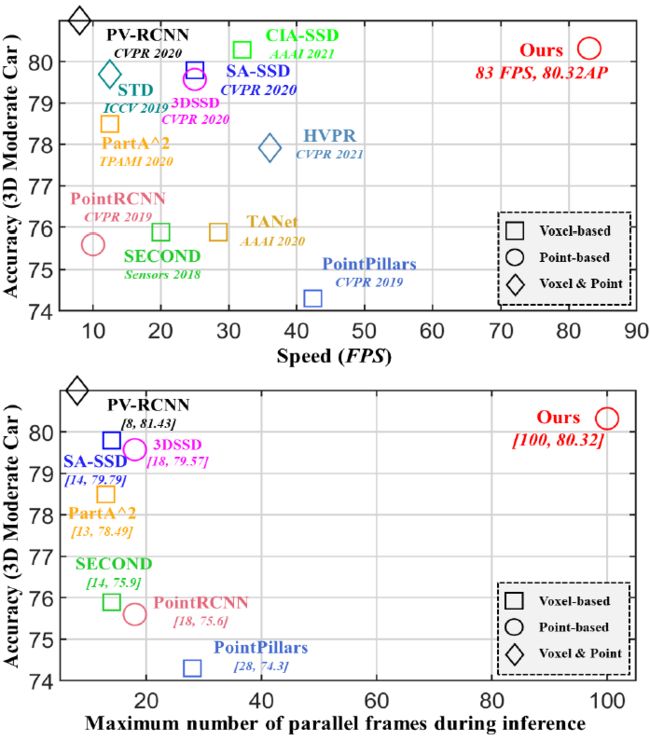
2、相关工作(综述)
1.基于Voxel方法
为了处理非结构化三维点云,基于体素的检测器通常首先将不规则点云转换为规则体素网格,这允许利用成熟的卷积网络架构。早期的工作,对输入点云进行密集体素化,然后利用卷积神经网络学习特定的几何模式。然而,效率是这些方法的主要限制之一,因为计算和内存成本随着输入分辨率呈立方体增长。为此,Yan等人[49]通过利用3D子流形稀疏卷积[9],提出了一种称为SECOND的高效架构。通过减少对空体素的计算,计算和存储效率显著提高。此外,提出了PointPillars,以进一步将体素简化为pillars (即仅在平面中进行体素化)。
现有的方法大致可分为单级检测器[7,11,54,55,57,58]和两级检测器[4,36–39,53]。尽管简单有效,但由于空间分辨率降低和结构信息不足,尤其是对于具有稀疏点的小对象,它们通常无法实现令人满意的检测性能。为此,SA-SSD通过引入辅助网络来利用结构信息。Ye等人[54]介绍了一种混合体素网络(HVNet),用于集中和投影多尺度特征图,以获得更好的性能。郑等人[58]提出了置信IoU感知(CIA-SSD )网络来提取空间语义特征,用于目标检测。相比之下,两级检测器可以获得更好的性能,但计算/存储成本较高。Shi等人[39]提出了一种两级检测器,即Part-A2,它由Part-aware和聚合模块组成。Deng等人[5]通过引入完全卷积网络来扩展PV-RCNN[36],以进一步利用原始点云的体积表示并同时进行细化。
总的来说,基于体素的方法可以实现良好的检测性能和良好的效率。然而,体素化不可避免地引入量化损耗。为了补偿预处理阶段的结构失真,需要在[20,25,27,28,35]中引入复杂的模块设计,这反过来会大大降低最终检测效率。此外,考虑到复杂的几何结构和各种不同的对象,在实践中确定最佳分辨率并不容易。
2.基于Point方法
与基于体素的方法不同,基于点的方法[30,38,52]直接从非结构化点云学习几何,进一步为感兴趣的对象生成特定proposal。考虑到3D点云的无序性,这些方法通常采用PointNet[31]及其变体[22、32、33、45、47],使用对称函数聚合独立的逐点特征。Shi等人[38]提出了PointRCNN,一种用于3D对象检测的两阶段3D区域proposal框架。该方法首先从分割的前景点生成对象建议,然后利用语义特征和局部空间线索回归高质量的三维边界框。Qi等人[30]介绍了VoteNet,这是一种基于深度Hough投票的单级point 3D检测器,用于预测实例质心。受2D图像中单级检测器[21]的启发,Yang等人[52]提出了一种3D单级检测(3DSSD)框架,而关键是融合采样策略,包括特征和欧几里德空间上的最远点采样。PointGNN[40]是一个将图形神经网络推广到3D对象检测的框架。
基于点的方法直接在原始点云上操作,无需任何额外的预处理步骤(如体素化),因此通常直观直观。然而,基于点的方法的主要瓶颈是学习能力不足和效率有限。
3.Point-Voxel方法
为了克服基于点的方法(即不规则和稀疏的数据访问、较差的内存局部性[23])和基于体素方法(如量化损失)的缺点,已经开始使用几种方法[3、16、36、37、53]从3D点云学习点-体素联合表示。PV-RCNN【36]及其后续工作[37]从体素抽象网络中提取逐点特征,以细化从三维体素主干生成的proposal。
HVPR[29]是一种单级3D探测器,通过引入高效内存模块以增强基于点的功能,从而在准确性和效率之间提供更好的折衷。Qian等人[34]提出了一种轻量级区域聚合细化网络(BANet)通过局部邻域图构造,产生更精确的box边界预测。
3.创新点
梗概: 首先将输入的激光雷达点云送入网络以提取逐点特征,然后进行拟议的实例感知下采样,以逐步降低计算成本,同时保留信息丰富的前景点。学习的潜在特征进一步输入到上下文质心感知模块,以生成实例建议并回归最终边界框。
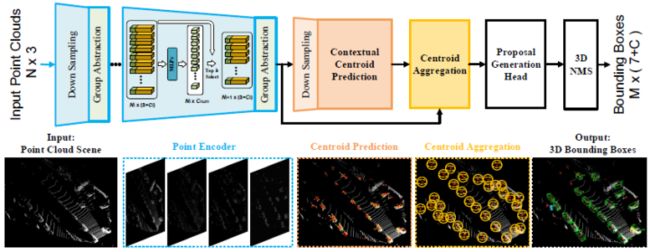
1.实例感知下采样策略
在 计算效率 和 前景点的保留 之间实现理想的权衡。为此,论文首先进行了一项实证研究,以定量评估不同的抽样方法,并遵循常用的编码体系结构(即具有4个编码层的PointNet++[32]),评估了随机点采样[14]、基于欧几里德距离的FPS(D-FPS)[32]和特征距离(Feat FPS)[52]等方法。
实验显示,在多次随机下采样操作后,实例召回率显著下降,表明大量前景点已被删除。D-FPS和Feat FPS在早期阶段都实现了相对较好的实例召回率,但在最后一个编码层也无法保留足够的前景点。因此,精确检测感兴趣的目标仍然是一项挑战,特别是对于行人和骑自行车的人等小目标,在这些小目标中只剩下极有限的前景点。
为了尽可能多地保留前景点,论文利用每个点的潜在语义,因为随着分层聚合在每个层中运行,学习的点特征可能包含更丰富的语义信息。根据这一思想,论文通过将前景语义先验合并到网络训练管道中,提出了以下两种面向任务的采样方法:
Class-aware Sampling
该采样策略旨在学习每个点的语义,从而实现选择性下采样。为了实现这一点,论文引入了额外的分支来利用潜在特征中丰富的语义。通过将两个MLP层附加到编码层,以进一步估计每个点的语义类别:
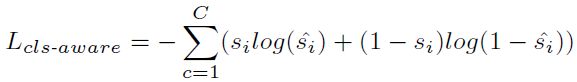
C表示类别数,si表示one-hot标签,si^表示预测Logit。在推理过程中,具有前k个前景分数的点被保留,并被视为馈送到下一编码层的代表点(为保留更多的前景点,实现了较高的实例召回率)。

Centroid-aware Sampling
考虑到实例中心估计是最终目标检测的关键,进一步提出了一种质心感知下采样策略,为更接近实例质心的点赋予更高的权重。将实例i的soft point mask定义如下:
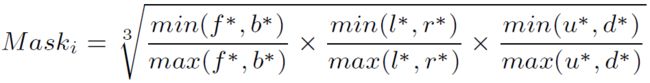
其中f∗, b∗, l∗, r∗, u∗, d∗ 分别表示点到边界框的6个surface(前、后、左、右、上和下)的距离。在这种情况下,靠近长方体质心的点可能具有更高的mask score(最大值为1),而位于surface上的点的mask分数为0。在训练期间,soft point mask将用于根据空间位置为边界框内的点指定不同的权重,因此将几何先验隐含地纳入网络训练。
将soft point mask与前景点的损失项相乘,以便为中心附近的点分配更高的概率。注意,在推理过程中不再需要box,如果模型训练充分,只需在下采样后保留得分最高的前k个点。
2.上下文实例质心感知
上下文质心预测
受2D图像中上下文预测成功的启发[6,51],论文试图利用边界框周围的上下文线索(质心预测)。遵循[30]明确预测偏移量∆ c到实例中心,并添加了正则化项以最小化质心预测的不确定性,质心预测损失公式如下:
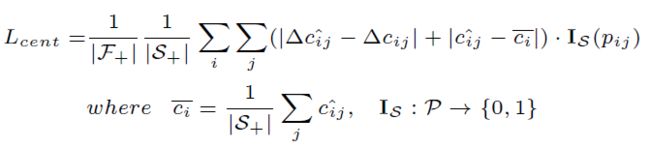
基于质心的实例聚合
对于移位代表(质心)点,进一步利用PointNet++模块学习每个实例的潜在表示。将相邻点转换为局部规范坐标系,然后通过共享MLP和对称函数聚合点特征。
Proposal Generation Head
将聚集的质心点特征输入到提案生成头中,预测具有带有类别的bounding box。论文将proposal编码为具有位置、规模和方向的多维表示。最后,所有proposal都通过具有特定IoU阈值的3D-NMS后处理进行过滤。
4.实验细节
为了提高效率,论文基于单级编码器体系结构构建了IA-SSD。SA层[32]用于提取逐点特征,并使用具有递增半径组的多尺度分组([0.2,0.8]、[0.8,1.6]、[1.6,4.8])来稳定地提取局部几何特征。考虑到早期层中包含的有限语义,在前两个编码层中采用D-FPS,然后是所提出的实例感知下采样。256个代表点特征被馈送到上下文质心预测模块中,然后是三个MLP层(256→256→3) 以预测实例质心。最后,添加分类和回归层(三个MLP层)以输出语义标签和相应的边界框。
九、RepSurf(CVPR2022 Oral)
题目:Surface Representation for Point Clouds,波士顿东北大学联合腾讯优图
代码地址: https://github.com/hancyran/RepSurf
论文地址: http://arxiv.org/abs/2205.05740
0.摘要
提出了 RepSurf(representative surface),一种新颖的点云表示,显式的描述了非常局部的点云结构。
RepSurf 包含两种变体,Triangular RepSurf (轻量)和 Umbrella RepSurf,其灵感来自计算机图形学中的三角形网格和伞形曲率。我们在表面重建后通过预定义的几何先验计算 RepSurf 的表征。RepSurf 可以成为绝大多数点云模型的即插即用模块,这要归功于它与无规则点集的自由协作。
在只有0.008M参数数量、0.04G FLOPs 和 1.12ms推理时间的增的情况下,我们的方法在分类数据集 ModelNet40 上达到 94.7% (+0.5%),在 ScanObjectNN 上达到 84.6% (+1.8%) ;而在分割任务的 S3DIS 6-fold 上达到74.3%(+0.8%) mIoU,在ScanNet 上达到70.0% (+1.6%) mIoU 。检测在 ScanNetV2 上达到71.2% (+2.1%) mAP25、54.8% (+2.0%) mAP50 和在 SUN RGB-D数据集上64.9% (+1.9%) mAP25、47.7% (+ 2.5%) mAP50的性能。
1.点云提取方法
受到泰勒级数的启发。泰勒级数用导数表示局部曲线。为了简化它,我们只考虑到二阶导数。因此,我们可以通过其对应的切线粗略地表示局部曲线,或者我们称之为 3D 点云中的“surface”。
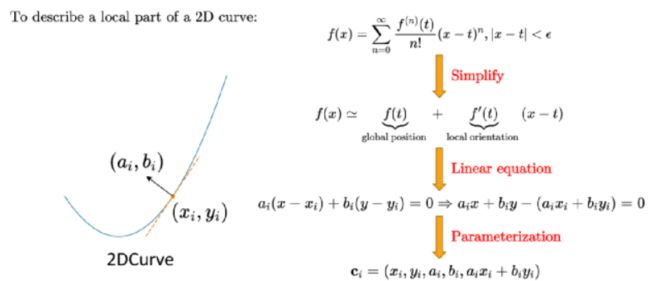

2.伪代码


#、常用点云分割数据集

代码如下(示例):
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。