VALSE2022内容总结
valse2022于8月21日在天津国家会展中心召开

做记录主要是分享大会介绍的CV领域内最新模型,方便后续可以引经据典。
文章目录
- 第一天
-
- 1.卢湖川(大连理工):一网通吃:跟踪与分割大一统
- 2.张磊(oppo):深度神经网络优化技术探索
- 3.张拳石(上交):深度学习从经验主义到去芜存菁
- 4.年度进展评述
-
- 0.华为宣讲
- 1. 目标检测与Transformer进展
-
- 1.轻量化与硬件配置
- 2.卷积神经网络
- 3.推广到分割、3D与多模态
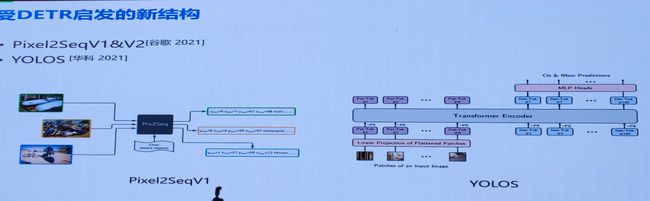
- 4.受DETR启发新结构(Pixel2Seq 与 YOLOS)
- 5.训练方法:自监督与半监督
- 2.微小目标检测:韩军伟
- 3.自动驾驶与3D目标检测
- 5.周晓巍(浙大):多视图三维重建:基于表示学习的方法
- 第二天
-
- 1.workshop3:Transformer
-
- 1.清华大学:分类、检测、与融合检测
- 2.王栋:Transformer in tracking
- 3.华科:YOLOS:纯ViT做检测
- 4.华中科大&腾讯:QueryInst(分割)
- 5.上海交大:Transformer for Vision Tasks:Computationally Efficient Vision Transformers
- 2.目标检测、分割与跟踪

第一天
这天都是专题报告。前两篇都是通用性介绍,尽量做综合的大模型
1.卢湖川(大连理工):一网通吃:跟踪与分割大一统
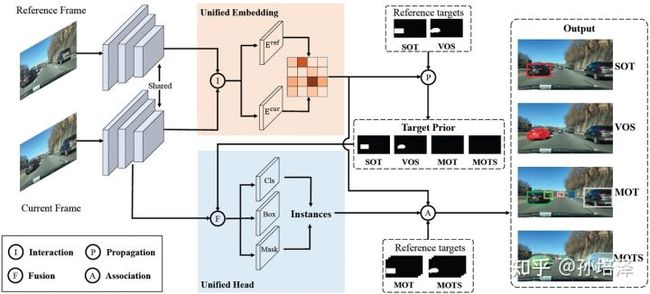
这里主要设计了模型UNICORN,统一了四个任务:SOT\MOT(单多目标检测)、实例分割与场景分割。
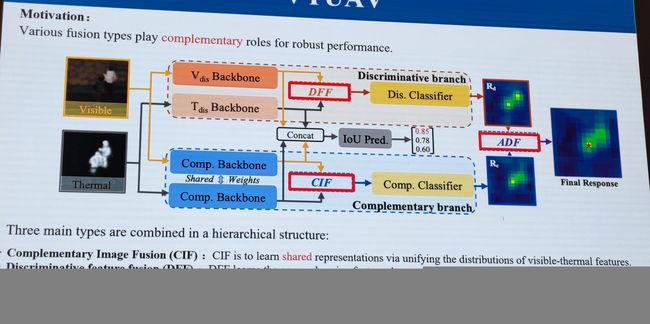
随后讲述了可见、红外目标融合检测框架 VTUAV
后面就是介绍算法UAVMOT。MOT任务的三个数据集:

MOT常用方法:

2.张磊(oppo):深度神经网络优化技术探索
张教授讲的很好,优化算法从Adam到SGD,不过最好的还是AdamGrad及其他Adam算法。由于不是专门研究优化的,这里不做详细叙述。
3.张拳石(上交):深度学习从经验主义到去芜存菁
4.年度进展评述
0.华为宣讲
主要介绍了华为的几个大一统模型:



1. 目标检测与Transformer进展
1.轻量化与硬件配置
2.卷积神经网络

3.推广到分割、3D与多模态

4.受DETR启发新结构(Pixel2Seq 与 YOLOS)
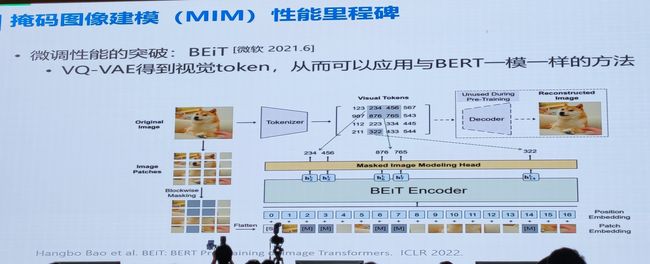
5.训练方法:自监督与半监督

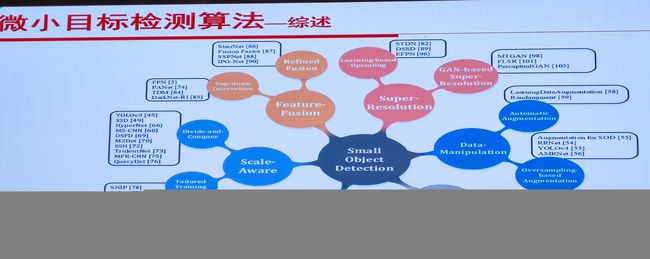
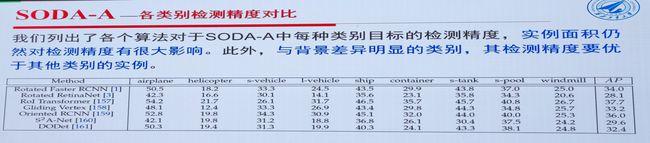
2.微小目标检测:韩军伟
3.自动驾驶与3D目标检测
先看算法目录:

然后是算法介绍:
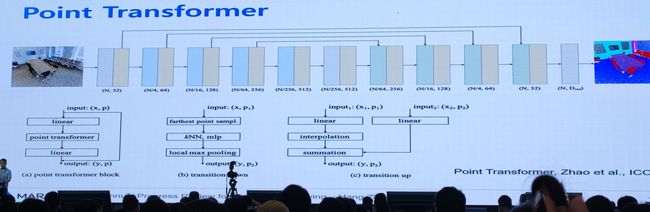

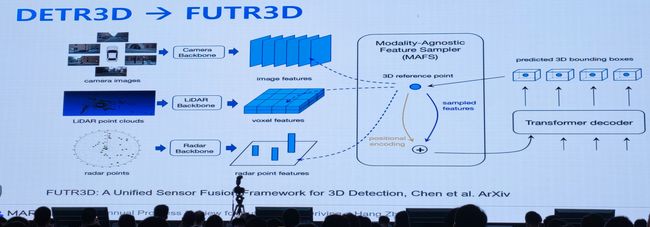


5.周晓巍(浙大):多视图三维重建:基于表示学习的方法
多视图三维重建,传统流程:


算法介绍:LoFTR

第二天
1.workshop3:Transformer
1.清华大学:分类、检测、与融合检测
01:Dynamic vision transformer(DVT)
Not all images are worth the same number of torkns;
Mind the sample-wise computational redundancy.
ViT 根据经验将tokens数量设置为 16x16。通常,用更多的标记表示图像会导致更高的预测精度,同时也会导致计算成本急剧增加
理想情况下,tokens数量应以每个单独的输入为条件。事实上,我们已经观察到存在相当多的“简单”图像,它们可以用仅仅数量的 4x4 标记准确预测,而只有一小部分“难”图像需要更精细的表示。
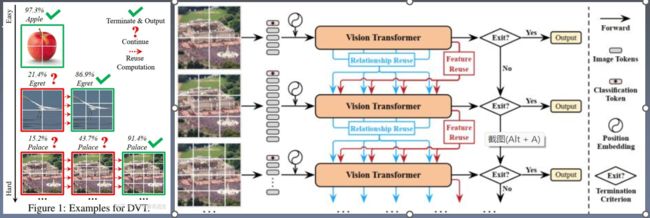
提出了一种动态Transformer来为每个输入图像自动配置适当数量的token。这是通过级联多个具有增加令token数量的 Transformer 来实现的,这些token在测试时以自适应方式顺序激活,即,一旦产生足够自信的预测,推理就会终止。
02.:Deformable attention transformers(DAT)
Not all regions are of same importance;
Mind the spatial-wise computational redundancy
思路主要来源于可变形卷积 DCN,理解起来很容易,就是保持 Q 不变,针对每个 K / V 学习一个位置偏差,取该处的特征值即可。
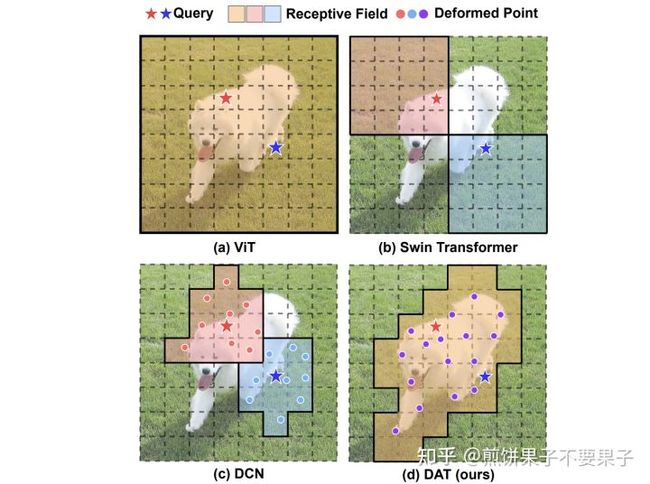
1.ViT 中所有 Q 的感受野是一样的,都针对全局所有位置特征;
2.Swin 中则是局部 Attention,因此处于不同窗口的两个 Q 针对的感受野区域是不一样的;
3.DCN 则是针对周围九个位置学习偏差,之后采样矫正过的特征位置,可以看到图中红点蓝点数量均为 9;
4.本文提出的 DAT 则结合了 ViT 和 DCN,所有的 Q 会共享相同的感受野,但这些感受野会有学出来的位置偏差;为了降低计算复杂度,针对的特征数量也会降采样,因此图中采样点一共 16 个,相比原来缩小了 1/4。
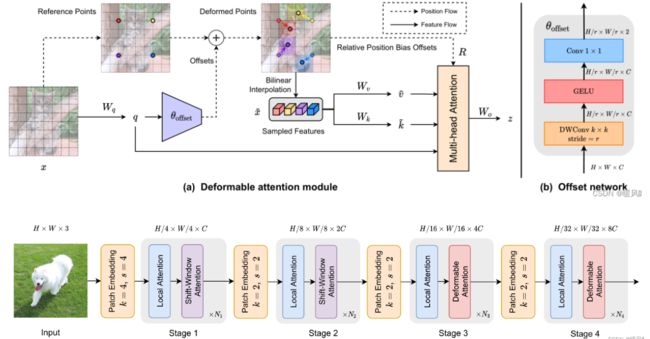
是相对于Swin-Transformer和PVT进行改进,加入了可变形机制,同时控制网络不增加太多的计算量,作者认为,缩小q对应的k的范围,能够减少无关信息的干扰,增强信息的捕捉,于是引入了DCN机制到注意力模块中,提出了一种新的注意力模块:可变形多头注意力模块——对k和v进行DCN偏移后再计算注意力。将这个模块替换到Swin-Transformer的第三四阶段的滑动窗口注意力部分,获得了较好的实验性能。
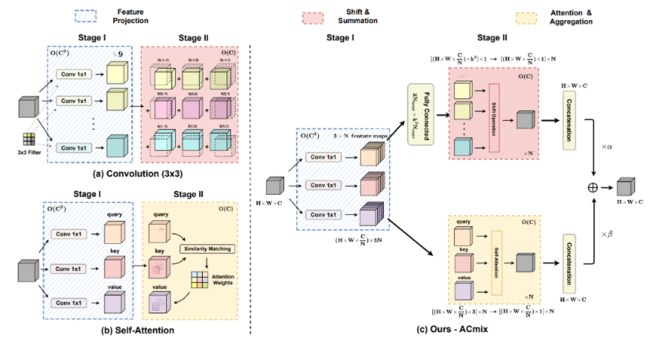
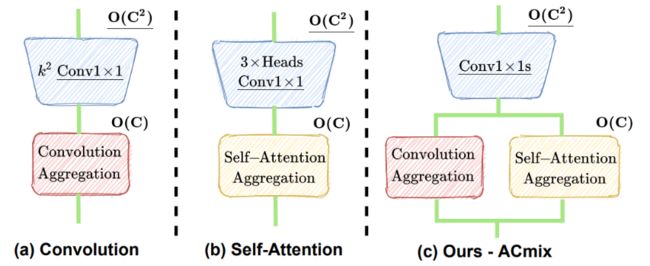
03.:integration of convolution and attention(ACMix)
CNN and transformers are not as diffrenrt as their name;
论文主要考虑到:一个33 CNN相当于9个11卷积,Trans的最原始映射也相当于1*1卷积。因此,两个模块的第一阶段都包含了类似的操作。更重要的是,与第二阶段相比,第一阶段的计算复杂度(通道的平方)占主导地位。
2.王栋:Transformer in tracking
即TransT:开发了一个基于self-attention的ego-context augment模块和基于cross-attention的cross-feature augment模块的特征融合网络。与基于correlation-based的特征融合相比,我们基于attention-based的方法自适应地关注有用的信息,如边缘和相似的目标,并建立 distant features之间的关联,使跟踪器获得更好的分类和回归结果。

作者还提供了微信,想要的可以留言,图片违规啦
3.华科:YOLOS:纯ViT做检测
YOLOS:You Only Look at One Sequence
- YOLOS在ViT中丢弃了 [CLS] token,并向输入序列中添加100个可学习的 [DET] token用于目标检测。
- YOLOS将ViT中的图像分类损失替换为二分匹配损失,以便按照DETR的预测方式执行目标检测。
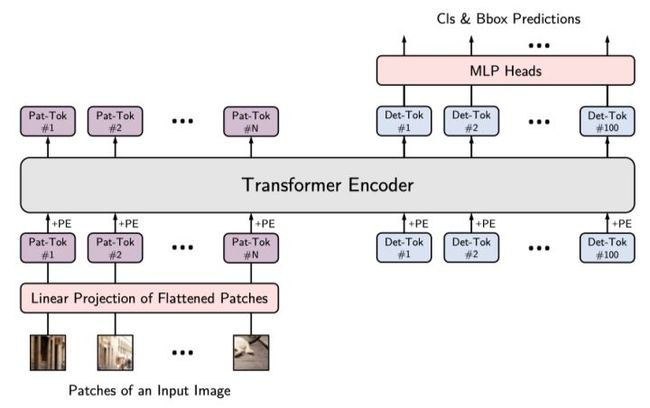
作者用随机初始化的 [DET] token作为对象表示的代理,以避免2D结构的归纳偏置和标签分配过程中注入任务的先验知识。在COCO数据集上进行微调时,对于每个向前传播,由[DET] token生成的预测output和GT对象之间的最佳二分匹配被建立,从而执行目标检测任务。此过程起着与标签分配相同的作用,但并没有重建图像的2D结构,即,YOLOS不需要将ViT的输出序列重新解释为2D特征图以进行标签分配(因此也可用于3D 1D等)
目标检测中常用的FPN,local attention和region-wise pooling等为了提高性能的操作在本文中都没有被采用。这是为了在最少的输入空间结构和几何知识的情况下,以纯序列到序列的方式揭示Transformer从图像识别到目标检测的多功能性和可迁移性。
、
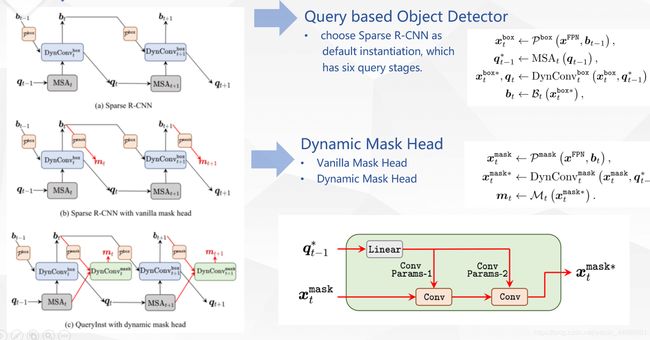
4.华中科大&腾讯:QueryInst(分割)
解决方法:
提出了QueryInst,基于query的实例分割,通过在动态mask heads上并行监督驱动。核心的思想是利用在不同stages的queries的内在intrinsic一对一对应联系,即mask RoI feature和object queries在同一阶段的一对一联系。
优点:
1.成功地在基于query的端到端检测框架中使用并行动态mask头的新角度解决实例分割问题;
2. 成功地通过利用共享query和多头自注意力设计为基于查询的目标检测和实例分割建立了任务联合范式;
3. 将QueryInst延展到例如YouTube-VIS数据集上,表现SOTA.
代码解读:
https://blog.csdn.net/qq_33642342/article/details/119028324
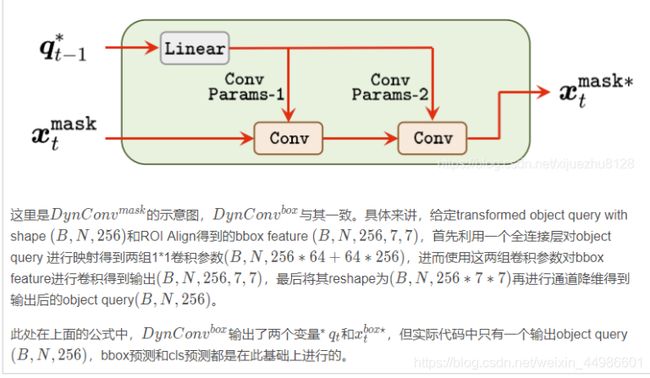
给定上一阶段的bbox预测结果和object query,首先通过ROI Align操作从FPN特征图提取bbox特征 (B,N,256,7,7)
随后利用multi-head self-attention计算transformed object query
随后利用object query和bbox feature之间的动态卷积得到增强后的bbox feature和object query
紧接着在其基础上进行bbox预测和分类。

5.上海交大:Transformer for Vision Tasks:Computationally Efficient Vision Transformers

提出了一个全局间隔采样+局部细节捕捉的新网络,如下:
2.目标检测、分割与跟踪
SOLO作者讲解分割(2D和3D)


其他自动驾驶领域介绍(大连理工大:王立君)