paper—A Hierarchical Graph-Based Neural Network for Malware Classification
基于层次图的神经网络恶意软件分类
目录
摘要
一、引言
二、相关工作
三、模型架构
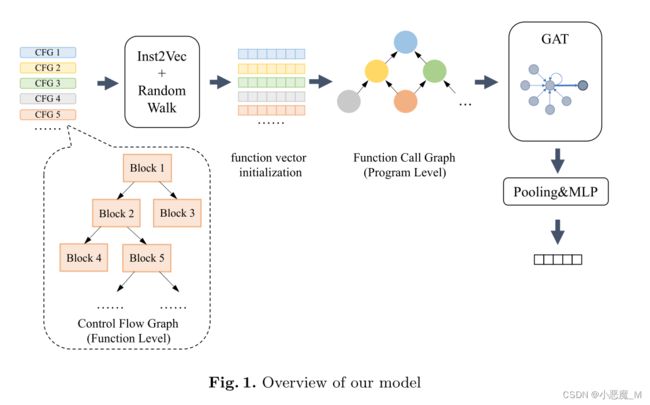
3.1 概述
3.2 Inst2Vec
3.3 函数矢量化
3.4 程序矢量化和分类
四、实验
4.1数据集
4.2 用于比较的模型
4.3 结果和分析
五、结论
摘要
近年来,基于机器学习和深度学习的恶意软件分类模型发展迅速。虽然这些模型取得了很好的效果,但由于缺乏良好的语义信息,其中许多模型的泛化能力有限。为了解决这个问题,我们首先找到程序的适当表示,并将程序转换为由一个函数调用图和多个控制流图组成的层次图结构。在图结构的基础上,利用BERT和图注意网络实现了一个语义表示更好、泛化能力更强的恶意软件分类模型。在两个不同数据集上的实验结果表明,我们的模型优于其他最先进的模型。
一、引言
首先,我们将二进制程序转换为层次图结构,而不是简单地将其视为序列。一个程序可以由多个函数调用形成的函数调用图(FCG)表示,而每个函数可以由由多个顺序执行的指令块组成的控制流图(CFG)表示。FCG和所有CFG构成了程序的层次结构图,它保存了所有指令以及跳转指令和函数调用的信息。
其次,由于指令的长度不同,我们将每条指令视为一个句子,这样既可以保留指令的更多信息,又可以避免单词词典过大的问题。
基于以上分析,我们提出了一种基于层次图的恶意软件分类模型。我们首先在CFGs和BERT[3]的基础上设计了一个用于指令矢量化的预训练模型Inst2Vec,这是NLP中一种流行的预训练语言模型。然后利用FCGs和图形神经网络(GNN)生成函数和整个程序的向量表示,GNN是一种直接作用于图形结构的网络。最后,我们将程序的向量表示形式输入到前馈网络中,得到分类结果。在两个分类难度不同的数据集上的实验表明,与其他先进的模型相比,我们的模型可以获得更好的分类性能,并具有更强的泛化能力。我们的贡献如下:
- 1、提出了一种基于CFGs和FCGs的层次图结构的二进制程序表示方法。该方法不仅维护了汇编代码中的大部分信息,而且还考虑了执行流信息。
- 2、我们设计了一个基于BERT和CFGs的无监督汇编语言模型Inst2Vec,它可以生成更合适的指令表示,并提供函数的初始表示。
- 3、基于程序的FCG,我们将图注意网络(GAT)和图池化合到我们的模型中,将更多的语义和结构信息集成到整个二进制程序的表示中。
二、相关工作
恶意软件分类。最常用的表示包括两种类型:字节和汇编指令。基于字节的方法通常将程序转换为图像,并使用端到端模型(如CNN)进行训练,而CNN缺乏程序的语义信息。为了充分利用装配指令中的语义信息,基于指令的模型采用了多种处理方法。
二进制相似性检测。虽然GNN很少被基于指令的模型用于恶意软件分类,但它已经被应用于二进制相似性检测。二进制代码相似性检测是计算机安全中的另一项重要任务,其目的是通过二进制代码来检测相似的二进制函数。二进制相似性检测只考虑特定的功能。传统的方法通常基于CFG的相似性。
三、模型架构
3.1 概述
我们的模型采用基于程序层次图的层次结构,使用不同的方法和网络分别生成指令、函数和整个程序的嵌入。
指令的矢量化是通过一个类似于BERT的预训练模型Inst2Vec来实现的,它利用了CFGs。
函数矢量化过程包括两个阶段。通过对函数的CFG进行随机游走,得到函数的初始向量。随后,所有函数向量都被输入到图形注意网络(GAT)中,并使用程序的FCG进行微调。然后,使用图池化层将所有函数表示合并为程序表示。最后,将程序表示发送到多层感知器(MLP)中,得到分类结果。
3.2 Inst2Vec
Inst2Vec使用BERT架构,它可以学习标记的上下文表示,并继续生成整个指令的向量。我们采用并修改了PalmTree[12]中描述的两个任务:蒙蔽语言模型(MLM)和上下文指令预测(CIP)来训练Inst2Vec模型。图2显示了Inst2Vec的训练过程。当Inst2Vec的训练完成后,我们使用与[CLS]对应的输出向量,即在原始指令之前添加的特殊标记,作为输入指令的表示。
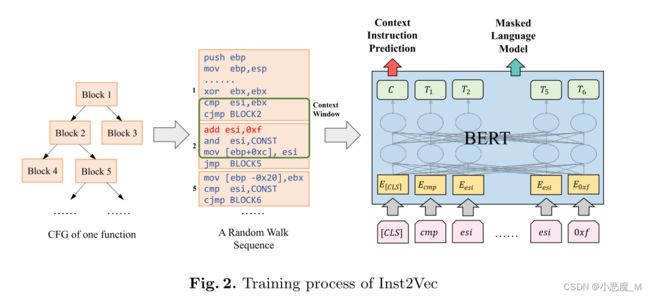
Task 1: Masked Language Model. 假设指令为I=[i1,i2,···,in],由n个标记组成。指令中的每个标记将以15%的概率替换。如果选择替换ik,则在80%的情况下,它将被蒙蔽为[MASK],或在10%的情况下随机放置为词汇表中的另一个标记,并且它也有10%可能被保留。最后,模型需要预测ik的原始值,这是通过模型顶部的softmax函数完成的:
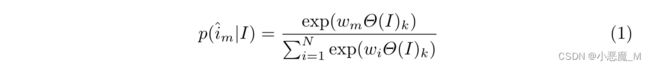
其中,ˆim是ik的预测。N是词汇表的大小。![]() 是标记m的权重,Θ是Inst2Vec模型的参数,而Θ(I)k是最后一层中ik的对应向量。
是标记m的权重,Θ是Inst2Vec模型的参数,而Θ(I)k是最后一层中ik的对应向量。
Task 2: Context Instruction Prediction. 此任务旨在帮助Inst2Vec学习指令的上下文信息。首先,我们利用随机游走方法基于CFG创建多个完整的指令序列。然后,我们考虑发生在相同上下文窗口中的指令对。具体来说,对于指令Icur,我们在Icur之前选择w指令,在Icur之后选择w指令,与Icur构成2w指令对,其中w是窗口的大小。我们将这些对输入到模型中,并执行二进制分类来判断两个给定的指令是否在同一窗口中同时出现。在我们的实验中,我们将w=2。最后一层中对应于【CLS】的输出用于预测两条指令之间的关系:
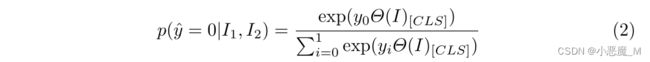
这两个任务都使用交叉熵损失函数进行训练。Inst2Vec的总损耗函数为:
3.3 函数矢量化
函数矢量化部分可分为两个阶段,即初始化阶段和微调阶段。初始化阶段基于Inst2Vec模型和函数的CFG提供的指令向量,而微调阶段基于整个程序的FCG。
Initialization Stage. 首先,我们从上面介绍的Inst2Vec模型中获取具有上下文信息的指令向量。然后,采用CFG上随机游走的思想生成初始函数向量,这与Inst2Vec的训练过程类似。每个随机游走路径表示函数中顺序执行的完整指令序列。对于每个函数,我们生成R个随机游走序列,并串联每个序列中所有指令向量的平均值来表示函数。在我们的实现中,R设置为5。函数的初始向量可以表示为:
Fine-Tuning Stage. 函数调用的内容是其语义的重要部分。由于在初始化阶段忽略了函数之间的关系,因此需要进一步优化。我们利用GAT微调函数的向量表示。
对于函数节点A和函数节点B,如果函数B调用函数A,则FCG中将有一条从A到B的边。与普通FCG相比,我们的FCG中的边缘具有相反的方向。普通的FCG关注这些函数的调用顺序,而我们的CFG则考虑函数之间的语义影响。此外,函数的语义还受其先前语义表示的影响,因此每个函数也有一个自循环边。
由于调用函数对语义的影响因函数而异,因此我们选择GAT来更新函数向量。GAT通过自我注意机制实现不同权重邻居的自适应匹配。
我们在模型中使用了一个2层GAT网络。为了简单起见,这里我们仅描述单个GAT层的结构。它的输入是程序中函数节点的特征集,![]() ,其中F是输入节点的特征维度。输出是由GAT层更新的函数节点的特征集
,其中F是输入节点的特征维度。输出是由GAT层更新的函数节点的特征集![]() ,其中F'是输出节点的特征维度。函数i和函数j之间的注意力系数αij可以表示为:
,其中F'是输出节点的特征维度。函数i和函数j之间的注意力系数αij可以表示为:
![]() 是权重矩阵。
是权重矩阵。![]() 是一个单层前馈神经网络。LeakyReLU用于非线性化过程。Ni表示函数节点 i 调用的函数节点集,i∈ Ni。
是一个单层前馈神经网络。LeakyReLU用于非线性化过程。Ni表示函数节点 i 调用的函数节点集,i∈ Ni。
为了稳定自我注意的学习过程,我们在模型中加入了多头注意和剩余连接。输出函数节点特征![]() 为:
为:
![]() 是剩余连接的权重矩阵。
是剩余连接的权重矩阵。![]() 和
和![]()
![]() 是头k的参数。k是注意头的数量。
是头k的参数。k是注意头的数量。
3.4 程序矢量化和分类
为了完成恶意软件分类的任务,有必要将所有经过微调的函数表示组合成一个程序表示。在我们的模型中,我们利用图池化算法获取FCG的表示作为程序的表示。我们最后的选择是平均池化,这在我们的实验中显示了最好的性能。在池化层之后,使用具有softmax函数的MLP来获得类别的预测可能性分布。事实上,函数向量的微调过程、程序向量的获取和分类过程共同构成了一个端到端的网络。整个过程可以描述为:
![]()
![]() 是程序p类别的预测值。我们使用交叉熵损失作为分类任务的损失函数。
是程序p类别的预测值。我们使用交叉熵损失作为分类任务的损失函数。
四、实验
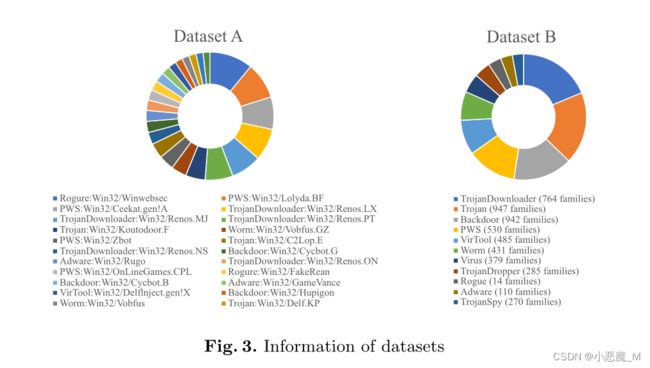
4.1数据集
我们使用良性数据集来训练Inst2Vec模型。由于恶意软件数据集中的程序都是32位PE程序,Inst2Vec模型使用32位x86指令进行训练。我们在32位Window 7和Ubuntu 16.04操作系统上收集了50000多个程序,最后提取了约3250000个指令对来训练我们的Inst2Vec模型。
我们的恶意软件数据集中的样本和类别信息来自VirusShare和VirusTotal网站。我们使用radare2生成程序的FCG和CFG。经过预处理和过滤,我们创建了两个不同的PE恶意软件数据集,这两个数据集在数据量和类别粒度上是不同的。第一个数据集共有24个类别的6021个恶意软件样本,其标签包含类型和家族信息。第二个数据集包含11个类别的27432个样本。第二个数据集中的示例标签仅包含恶意软件类型,这意味着一个类别可能包括多个恶意软件家族。因此,与第一个数据集相比,第二个数据集更难正确分类。我们将它们分别记为数据集A和数据集B。
4.2 用于比较的模型
我们实现了其他一些恶意软件分类模型进行比较,这些模型可以分为基于字节的模型和基于指令的模型。
我们首先测试了文献[14]中介绍的一些基本模型,包括CNN-2D、CNN-1D、BiLSTM和BiGRU。CNN-2D和CNN-1D都是基于字节码生成的图像,分别使用二维和一维图像。BiLSTM和BiGRU使用每个示例中的前5000个操作码。我们还使用了文献[14]中描述的两个转移学习(TL)模型,即VGG19和ResNet152,这两个模型经过预训练,比其他基于图像的模型具有更复杂的结构。此外,我们还采用MalConv模型进行比较,这是一种基于字节的方法,但不是基于图像的方法。
由于我们的模型是基于汇编指令的,因此我们还实现了几个最先进的基于指令的模型。Gibert等人[6]提出了一种基于指令的模型,使用CNN网络和各种大小的过滤器,在我们的实验中称为CNN- op。我们还实现了两个采用层次结构的模型,HCNN【5】和H-Tran【11】。HCNN考虑了功能层次,实现了多层CNN模型。H-Tran使用三层转换器分别获取块、函数和整个程序的特征向量。由于他们的模型是针对恶意软件检测而提出的,我们通过改变输出层的维度并用softmax替换输出层的逻辑函数来修改该模型以执行恶意软件分类任务。公平地说,我们没有在PE头中使用特征。
4.3 结果和分析
我们使用5倍交叉验证来评估我们的模型和其他模型。表1显示了两个数据集上每个模型的分类性能。由于每个类别中的数据量非常不同,我们在实验结果中重点关注加权F1分数。
数据集A上的结果表明,总体而言,基于字节的模型的性能略优于基于指令的模型。由于数据集A相对较小且粒度较细,基于字节的方法更适合完成分类任务,这些方法利用了更多的结构信息,如程序头和数据段。考虑到像VGG19这样的TL模型通常已经学到了很多先验知识,难怪VGG19的得分最高。然而,值得注意的是,我们的模型得分与VGG19之间只有很小的差距,这表明仅使用程序的代码段就有机会获得与基于字节的方法相当的结果。此外,与其他基于指令的模型相比,我们的模型F1得分至少高出1.43分,证明了我们的程序表示的有效性。
由于数据集B上的分类任务比较困难,需要泛化能力,因此结果更有价值。一般来说,基于指令的模型比基于字节的模型性能更好,表明代码段背后的语义信息对于更复杂的分类至关重要。
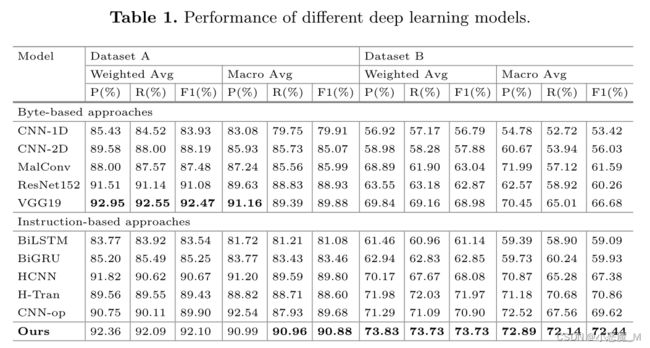
值得注意的是,我们的模型在所有精度、召回率和F1分数方面都取得了最好的结果,这表明我们的模型可以适应更一般的场景。此外,与其他基于层次表示的模型(如HCNN和H-Tran)相比,我们的模型的F1得分至少为1.76分,证明了在整个二进制程序的语义表示中使用图形结构的重要性。
我们还通过在数据集A上的实验验证了模型中每个模块对分类性能的影响,如表2所示。
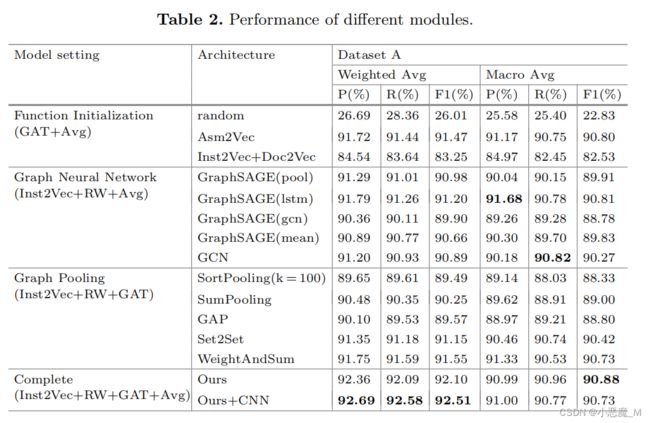
我们首先测试不同函数初始化方法的效果。除模型中使用的方法外,还采用了其他三种方法。
- 当使用随机初始化时,该模型只能依靠GNN学习的程序FCG的结构信息来预测其类别。在这种情况下,模型的精度仅为26.69%,证明了Inst2Vec模型的必要性。
- Asm2Vec,另一种无监督函数初始化方法,也会产生比我们稍差的结果。
- 此外,我们尝试将Inst2Vec与Doc2Vec相结合,以获得初始函数表示,它采用PV-DM算法修改Inst2Vec生成的表示。其结果不如我们的结果好,表明了我们提出的平均随机游动指令集结果的方法的有效性。
此外,我们还检验了GNN在我们的模型中的作用。我们将GAT替换为其他几个GNN,如GraphSAGE[7]和GCN[9]。结果表明,我们的GAT在这些GNN中运行得最好。此外,我们还测试了各种图形池化算法以进行比较,包括Set2Set[17]、SortPooling、SumPooling、WeightAndSum、AvgPooling和全局注意池(GAP)[13]。结果表明,AvgPooling算法保证了最显著的结果。
以前的工作已经声明了数据段和程序头中信息的重要性。因此,我们将CNN-2D中使用的包含非指令信息的CNN模型集成到我们的模型中。在数据集A上的实验结果表明,该多模态网络能够在一定程度上改善分类结果,验证了以往研究的有效性。此外,它还证明了我们的模型可以学习不同于基于字节的模型的特征。
五、结论
- 本文提出了一种基于层次图的神经网络恶意软件分类方法。我们利用CFGs和FCGs获得恶意软件程序的新表示,然后利用BERT和GNN实现一个分类模型。该模型弥补了以往模型中忽略执行流信息的不足。
- 实验结果表明,该模型的泛化能力强于现有的大多数模型。
- 由于我们的模型只关注程序的代码段,因此它没有利用程序中的其他有用信息,并且不适用于无法反编译的程序。在未来的工作中,我们将探索将更多的非指令信息集成到我们的模型中,以获得更好的性能。