Flume04:【案例】使用Flume采集文件内容上传至HDFS
案例:采集文件内容上传至HDFS
接下来我们来看一个工作中的典型案例:
采集文件内容上传至HDFS
需求:采集目录中已有的文件内容,存储到HDFS
分析:source是要基于目录的,channel建议使用file,可以保证不丢数据,sink使用hdfs
下面要做的就是配置Agent了,可以把example.conf拿过来修改一下,新的文件名为file-to-hdfs.conf
首先是基于目录的source,咱们前面说过,Spooling Directory Source可以实现目录监控
来看一下这个Spooling Directory Source
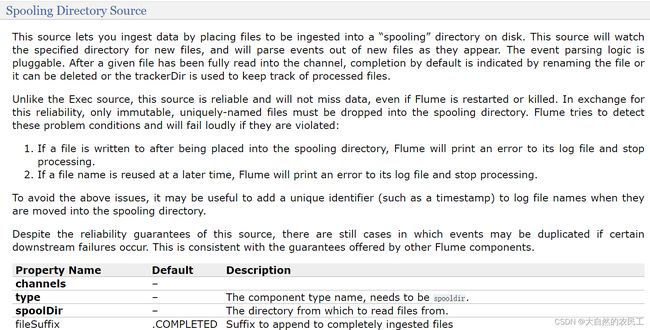
channels和type肯定是必填的,还有一个是spoolDir,就是指定一个监控的目录
看他下面的案例,里面还多指定了一个fileHeader,这个我们暂时也用不到,后面等我们讲了Event之后大家就知道这个fileHeader可以干什么了,先记着有这个事把。
那来配置一下source
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
接下来是channel了
channel在这里使用基于文件的,可以保证数据的安全性
如果针对采集的数据,丢个一两条对整体结果影响不大,只要求采集效率,那么这个时候完全可以使用基于内存的channel
咱们前面的例子中使用的是基于内存的channel,下面我们到文档中找一下基于文件的channel
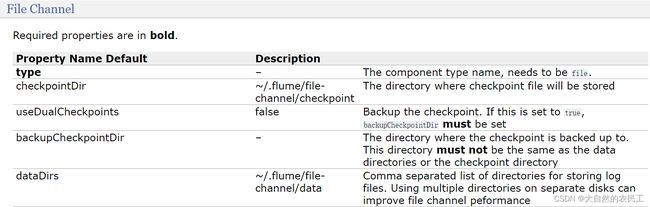
根据这里的例子可知,主要配置checkpointDir和dataDir,因为这两个目录默认会在用户家目录下生成,建议修改到其他地方
checkpointDir是存放检查点目录
data是存放数据的目录
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir/checkpoint
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/data
最后是sink
因为要向hdfs中输出数据,所以可以使用hdfssink

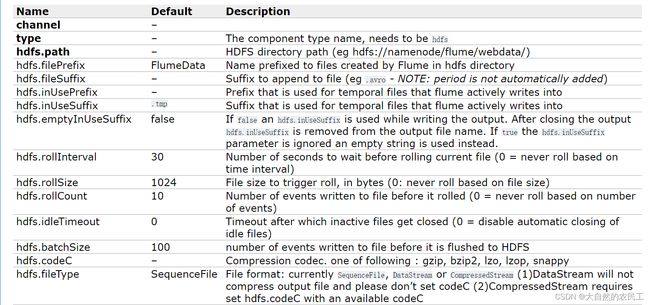

hdfs.path是必填项,指定hdfs上的存储目录
看这里例子中还指定了filePrefix参数,这个是一个文件前缀,会在hdfs上生成的文件前面加上这个前缀,这个属于可选项,有需求的话可以加上
一般在这我们需要设置writeFormat和fileType这两个参数
默认情况下writeFormat的值是Writable,建议改为Text,看后面的解释,如果后期想使用hive或者impala操作这份数据的话,必须在生成数据之前设置为Text,Text表示是普通文本数据
fileType默认是SequenceFile,还支持DataStream 和 CompressedStream ,DataStream 不会对输出数据进行压缩,CompressedStream 会对输出数据进行压缩,在这里我们先不使用压缩格式的,所以选择DataStream
除了这些参数以外,还有三个也比较重要
hdfs.rollInterval、hdfs.rollSize和hdfs.rollCount
1、hdfs.rollInterval默认值是30,单位是秒,表示hdfs多长时间切分一个文件,因为这个采集程序是一直运行的,只要有新数据,就会被采集到hdfs上面,hdfs默认30秒钟切分出来一个文件,如果设置为0表示不按时间切文件
2、hdfs.rollSize默认是1024,单位是字节,最终hdfs上切出来的文件大小都是1024字节,如果设置为0表示不按大小切文件
3、hdfs.rollCount默认设置为10,表示每隔10条数据切出来一个文件,如果设置为0表示不按数据条数切文件
这三个参数,如果都设置的有值,哪个条件先满足就按照哪个条件都会执行。
在实际工作中一般会根据时间或者文件大小来切分文件,我们之前在工作中是设置的时间和文件大小相结合,时间设置的是一小时,文件大小设置的128M,这两个哪个满足执行哪个
所以针对hdfssink的配置最终是这样的
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
最后把组件连接到一起
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
把Agent的配置保存到flume的conf目录下的file-to-hdfs.conf文件中:
[root@bigdata04 conf]# vi file-to-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir/checkpoint
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/data
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
下面就可以启动agent了,在启动agent之前,先初始化一下测试数据
创建/data/log/studentDir目录,然后在里面添加一个文件,class1.dat
class1.dat中存储的是学生信息,学生姓名、年龄、性别
[root@bigdata04 ~]# mkdir -p /data/log/studentDir
[root@bigdata04 ~]# cd /data/log/studentDir
[root@bigdata04 studentDir]# more class1.dat
jack 18 male
jessic 20 female
tom 17 male
启动Hadoop集群
[root@bigdata01 ~]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
启动Agent,使用在前台启动的方式,方便观察现象
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-hdfs.conf -Dflume.root.logger=INFO,console
2020-05-02 15:36:58,283 (conf-file-poller-0) [ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:150)] Failed to start agent because dependencies were not found in classpath. Error follows.
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
at org.apache.flume.sink.hdfs.HDFSEventSink.configure(HDFSEventSink.java:246)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.SequenceFile$CompressionType
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 12 more
但是发现在启动的时候报错,提示找不到SequenceFile,但是我们已经把fileType改为了DataStream,但是Flume默认还是会加载这个类
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.SequenceFile$CompressionType
就算你把SequenceFile相关的jar包都拷贝到flume的lib目录下解决了这个问题,但是还是会遇到找不到找不到HDFS这种文件类型,还是缺少hdfs相关的jar包
No FileSystem for scheme: hdfs
当然这个问题也可以通过拷贝jar包来解决这个问题,但是这样其实太费劲了,并且后期我们有很大可能需要在这个节点上操作HDFS,所以其实最简单直接的方法就是把这个节点设置为hadoop集群的一个客户端节点,这样操作hdfs就没有任何问题了。
咱们之前在讲Hadoop的时候讲了客户端节点的特性,其实很简单,我们直接把集群中修改好配置的hadoop目录远程拷贝到bigdata04上就可以了。
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 192.168.182.103:/data/soft/
The authenticity of host '192.168.182.103 (192.168.182.103)' can't be established.
ECDSA key fingerprint is SHA256:SnzVynyweeRcPIorakoDQRxFhugZp6PNIPV3agX/bZM.
ECDSA key fingerprint is MD5:f6:1a:48:78:64:77:89:52:c4:ad:63:82:a5:d5:57:92.
Are you sure you want to continue connecting (yes/no)? yes
[email protected]'s password:
由于bigdata01和bigdata04没有做免密码登录,也不认识它的主机名,所以就使用ip,并且输入密码了。
拷贝完成之后到bigdata04节点上验证一下
[root@bigdata04 soft]# ll
total 255844
drwxr-xr-x. 8 root root 216 May 2 15:36 apache-flume-1.9.0-bin
-rw-r--r--. 1 root root 67938106 May 1 23:27 apache-flume-1.9.0-bin.tar.gz
drwxr-xr-x. 8 root root 134 May 2 15:50 hadoop-3.2.0
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
[root@bigdata04 soft]# cd hadoop-3.2.0/
[root@bigdata04 hadoop-3.2.0]# bin/hdfs dfs -ls hdfs://192.168.182.100:9000/
Found 20 items
-rw-r--r-- 2 root supergroup 1860100000 2020-04-28 22:15 hdfs://192.168.182.100:9000/hello_10000000.dat
drwxr-xr-x - root supergroup 0 2020-04-19 20:20 hdfs://192.168.182.100:9000/log
drwxr-xr-x - yehua supergroup 0 2020-04-28 21:21 hdfs://192.168.182.100:9000/mapFile
...............
注意:还需要修改环境变量,配置HADOOP_HOME,否则启动Agent的时候还是会提示找不到SequenceFile
[root@bigdata04 hadoop-3.2.0]# vi /etc/profile
.....
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
[root@bigdata04 hadoop-3.2.0]# source /etc/profile
再重新启动Agent
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/file-to-hdfs.conf -Dflume.root.logger=INFO,console
此时可以看到Agent正常启动
2020-05-02 15:56:01,954 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2020-05-02 15:56:01,955 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r1 started
还可以看到类似这样的日志
2020-05-02 16:14:21,162 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:246)] Creating hdfs://192.168.182.100:9000/flume/studentDir/stu-.1588407260986.tmp
到hdfs上验证结果
[root@bigdata04 apache-flume-1.9.0-bin]# hdfs dfs -ls hdfs://192.168.182.100:9000/flume/studentDir
Found 1 items
-rw-r--r-- 2 root supergroup 42 2020-05-02 16:14 hdfs://192.168.182.100:9000/flume/studentDir/stu-.1588407260986.tmp
此时发现文件已经生成了,只不过默认情况下现在的文件是.tmp结尾的,表示它在被使用,因为Flume只要采集到数据就会向里面写,这个后缀默认是由hdfs.inUseSuffix参数来控制的。
文件名上还拼接了一个当前时间戳,这个是默认文件名的格式,当达到文件切割时机的时候会给文件改名字,去掉.tmp
这个文件现在也是可以查看的,里面的内容其实就是class1.dat文件中的内容
[root@bigdata04 ~]# hdfs dfs -cat hdfs://192.168.182.100:9000/flume/studentDir/stu-.1588407260986.tmp
jack 18 male
jessic 20 female
tom 17 male
所以此时Flume就会监控linux中的/data/log/studentDir目录,当发现里面有新文件的时候就会把数据采集过来。
那Flume怎么知道哪些文件是新文件呢?它会不会重复读取同一个文件的数据呢?
不会的,我们到/data/log/studentDir目录看一下你就知道了
[root@bigdata04 ~]# cd /data/log/studentDir/
[root@bigdata04 studentDir]# ll
total 4
-rw-r--r--. 1 root root 42 May 2 13:46 class1.dat.COMPLETED
我们发现此时这个文件已经被加了一个后缀.COMPLETED,表示这个文件已经被读取过了,所以Flume在读取的时候会忽略后缀为.COMPLETED的文件。
接着我们再看一下channel中的数据,因为数据是存在本地磁盘文件中的,所以是可以去看一下的,进入dataDir指定的目录
[root@bigdata04 studentDir]# cd /data/soft/apache-flume-1.9.0-bin/data/studentDir/data/
[root@bigdata04 data]# ll
total 1028
-rw-r--r--. 1 root root 0 May 2 16:14 in_use.lock
-rw-r--r--. 1 root root 1048576 May 2 16:14 log-1
-rw-r--r--. 1 root root 47 May 2 16:14 log-1.meta
发现里面有一个log-1的文件,这个文件中存储的其实就是读取到的内容,只不过在这无法直接查看。
现在我们想看一下Flume最终生成的文件是什么样子的,难道要根据配置等待1个小时或者弄一个128M的文件过来吗,
其实也没必要,我们可以暴力操作一下
停止Agent就可以看到了,当Agent停止的时候就会去掉.tmp标志了
[root@bigdata04 checkpoint]# hdfs dfs -ls hdfs://192.168.182.100:9000/flume/studentDir
Found 1 items
-rw-r--r-- 2 root supergroup 42 2020-05-02 16:34 hdfs://192.168.182.100:9000/flume/studentDir/stu-.1588407260986
那我再重启Agent之后,会不会再给加上.tmp呢,不会了,每次停止之前都会把所有的文件解除占用状态,下次启动的时候如果有新数据,则会产生新的文件,这其实就模拟了一下自动切文件之后的效果。
但是这个文件看起来比较别扭,连个后缀都没有,没有后缀倒不影响使用,就是看起来不好看
在这给大家留一个作业,下一次再生成新文件的时候我希望文件名有一个后缀是.log,大家下去之后自己查看官网文档资料,修改Agent配置,添加测试数据,验证效果。
答案:其实就是使用hdfs sink中的hdfs.fileSuffix参数