hive3.1decimal计算详细逻辑
本文章参考
DECIMAL data type

先备注下hive2合hive3计算逻辑不一样 且hive2存在bug 详情见上篇文章。
decimal计算中我们主要是用+-*/
那么这几个计算到底是什么样呢?
比如 decimla(38,18)*decimla(38,18) =我们期望的是什么呢? decimla(38,18) 还是decimla(38,36)
那万一数值是1234567890123456789.1*1234567890123456789.1
注意这个前面是19位*19位 那么我们期望的值是什么呢?
1.直接报错。因为我们期望得到的格式是decimla(38,18) 个数位只能有20位
2.算出结果,截取小数位,因为最后会有38位个数,小数位不要了
3. 如果算出的结果是39、40位个数呢?报错吗?
那如果是1.012345678912345678*1.012345678912345678
我们又期望是什么结果呢?
1整数或者小数超过精度即报错
2.计算后截取整数或者小数
3.太多了报错,稍微超过一点截取小数位
所以现在hive3.1来研究下。直接git clone 源码。然后找到源码

例如 org.apache.hadoop.hive.ql.udf.generic.GenericUDFOPMultiply
研究加减乘除前我们先看hive3 针对hive2的bug 做了一个adjustPrecScale()的方法。
这个入参是计算后的精度例如 decimal(77,36) decimal(38,18) 各种
protected DecimalTypeInfo adjustPrecScale(int precision, int scale) {
// Assumptions:
// precision >= scale
// scale >= 0
// 这里说明 精度p >=刻度s 没啥好说的 必须的
if (precision <= HiveDecimal.MAX_PRECISION) {
// Adjustment only needed when we exceed max precision
return new DecimalTypeInfo(precision, scale);
}
//这个max=38 说明p<=38了 那么直接就返回了(38,18) (38,38) (38,0)
// Precision/scale exceed maximum precision. Result must be adjusted to HiveDecimal.MAX_PRECISION.
// See https://blogs.msdn.microsoft.com/sqlprogrammability/2006/03/29/multiplication-and-division-with-numerics/
int intDigits = precision - scale; //算出有多少整数位
// If original scale less than 6, use original scale value; otherwise preserve at least 6 fractional digits
//如果原先的刻度也就是小数位小于6,那么就用原来的小数,否则就用6
int minScaleValue = Math.min(scale, MINIMUM_ADJUSTED_SCALE); 算出最小的刻度,反正不超过6,原先是1还是1 原先是6还是6 原先是7变6 原先30变6
int adjustedScale = HiveDecimal.MAX_PRECISION - intDigits;//38-整数位
adjustedScale = Math.max(adjustedScale, minScaleValue); // 两者取最大值
// 其实这里就是算小数位到底是多少。因为精度已经确定了就是38
return new DecimalTypeInfo(HiveDecimal.MAX_PRECISION, adjustedScale);
}
我们先看乘
@Override protected DecimalTypeInfo deriveResultDecimalTypeInfo(int prec1, int scale1, int prec2, int scale2) { // From https://msdn.microsoft.com/en-us/library/ms190476.aspx // e1 * e2 // Precision: p1 + p2 + 1 // Scale: s1 + s2 int scale = scale1 + scale2; int prec = prec1 + prec2 + 1; return adjustPrecScale(prec, scale); }很简单,举例
(38,18)*(38,18)=(77,36)
adjust
77>38 所以我们走下面的逻辑 整数位 77-36=41 小数位36
int adjustedScale = HiveDecimal.MAX_PRECISION - intDigits=38-41=-2
adjustedScale = Math.max(adjustedScale, minScaleValue); max(-2,6)
所以结果 (38,6)
这里有个问题了。 这个精度6总感觉很低 我还是想要38,18或者说38,10那么怎么办?
adjustedScale = Math.max(adjustedScale, minScaleValue)=10 因为adjustedScale<=6
所以minScaleValue=10 才会有adjustedScale=10
int adjustedScale = HiveDecimal.MAX_PRECISION - intDigits=10
所以intDigits=38-20=28
int intDigits = precision - scale; 由此我们可以推出针对乘以来说
(p1+p2+1)-(s1+s2)=28
随便写两个吧 (20,6)*(19,6)=(38,18)
create table test.cc_decimal2(id decimal(20,6) ,score decimal(19,6))
insert into table cc_decimal2 values(1.123456789,1.123456789)
select id, score,id*id,score*score ,id*score from cc_decimal2

所以说不吹牛比,看着源码写就是简单。
(20,6)*(20,6) 因为20+20+1=41>38 刻度6+6=12 整数位=41-12=29 ,所以小数位=38-29=9
(19,6)*(19,6) 因为19+19+1=39>38 刻度6+6=12 整数位=39-12=27, 所以小数位=38-27=11 图错了
(19,6)*(19,6)*(19,6)=(38,11)*(19,6) 19+38+1=58>38 刻度=11+6=17 整数=58-17=41 小数=38-41=-1 所以max(-1,6)=6 所以结果(38,6) 如下图。
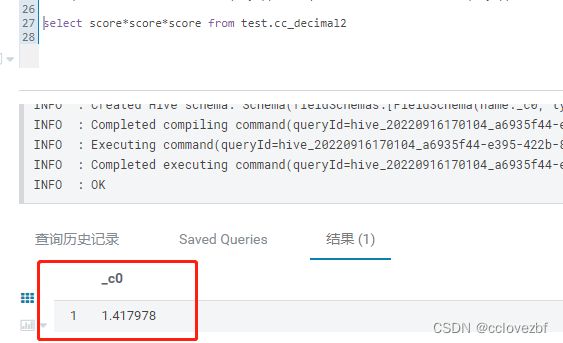
所以不要想着保留几位小数了 就按hive的来默认保留6位
其实看着复杂,总结下。
1看两个p1+p2+1大不大于38 如果小于等于 那么最终精度就是(p1+p2+1,s1+s2)
2.如果精度>38 那么就保留整数位,同时看保留的整数位后的小数位和6比谁大。(也不一定是6)
这样做的目的是尽可能的保证小数多的相乘的精度,又保证了整数多的数相乘的位数(能够保留38-6=32位整数)
我们来看除
protected DecimalTypeInfo deriveResultDecimalTypeInfo(int prec1, int scale1, int prec2, int scale2) {
// From https://msdn.microsoft.com/en-us/library/ms190476.aspx
// e1 / e2
// Precision: p1 - s1 + s2 + max(6, s1 + p2 + 1)
// Scale: max(6, s1 + p2 + 1)
int intDig = prec1 - scale1 + scale2;
int scale = Math.max(6, scale1 + prec2 + 1);
int prec = intDig + scale;
return adjustPrecScale(prec, scale);
}、艹 这个计算这么麻烦
刻度 max(6, s1 + p2 + 1)
还是以6为基准不过是最小是6,为啥呢? e1/e2
精度 p1 - s1 + s2 + max(6, s1 + p2 + 1)
-------未完待续------