HaGRID手势识别数据集使用说明和下载
HaGRID手势识别数据集使用说明和下载
目录
HaGRID手势识别数据集使用说明和下载
1. HaGRID手势识别数据集说明
2. HaGRID数据集下载(约716GB)
3.Light-HaGRID数据集下载(约18GB)
(1)Light-HaGRID数据集说明
(2)Light-HaGRID数据集下载
4. 基于目标检测的手势识别
5. 基于目标检测+分类识别的手势识别
1. HaGRID手势识别数据集说明
本篇,我们将介绍一个超大的手势识别图像数据集 HaGRID (HAnd Gesture Recognition Image Dataset)。 HaGRID数据集种类非常丰富,包含one,two,ok等18种常见的通用手势, 标注了手势框和手势类别标签,可以用于图像分类或图像检测等任务。

HaGRID数据集数量特别大,有716GB的大小,包含 552,992 个 FullHD (1920 × 1080) RGB 图像。 此外,如果帧中有第二只手,则某些图像具有 no_gesture 类。 这个额外的类包含 123,589 个样本。 数据分为 92% 的训练集和 8% 的 测试集,其中 509,323 幅图像用于训练,43,669 幅图像用于测试。

2. HaGRID数据集下载(约716GB)
官方下载地址: https://github.com/hukenovs/hagrid
由于数据量特别大,官方已经将手势数据集分成 18 个文件,可从以下链接下载并解压:
- Tranval
| Gesture | Size | Gesture | Size |
|---|---|---|---|
| call | 39.1 GB | peace | 38.6 GB |
| dislike | 38.7 GB | peace_inverted | 38.6 GB |
| fist | 38.0 GB | rock | 38.9 GB |
| four | 40.5 GB | stop | 38.3 GB |
| like | 38.3 GB | stop_inverted | 40.2 GB |
| mute | 39.5 GB | three | 39.4 GB |
| ok | 39.0 GB | three2 | 38.5 GB |
| one | 39.9 GB | two_up | 41.2 GB |
| palm | 39.3 GB | two_up_inverted | 39.2 GB |
train_val annotations: ann_train_val
- Test
| Test | Archives | Size |
|---|---|---|
| images | test | 60.4 GB |
| annotations | ann_test | 3.4 MB |
-
Subsample
Subsample has 100 items per gesture.
| Subsample | Archives | Size |
|---|---|---|
| images | subsample | 2.5 GB |
| annotations | ann_subsample | 153.8 KB |
3.Light-HaGRID数据集下载(约18GB)
原始的HaGRID数据集太大,图片都是高分辨率(1920 × 1080)200W像素,完整下载HaGRID数据集,至少需要716GB的硬盘空间。另外,由于是外网链接,下载可能经常掉线。
考虑到这些问题,鄙人对HaGRID数据集进行精简和缩小分辨率,目前整个数据集已经压缩到18GB左右,可以满足手势识别分类和检测的任务需求,为了有别于原始数据集,该数据集称为Light-HaGRID数据集,即一个比较轻量的手势识别数据集。
(1)Light-HaGRID数据集说明
以下是Light-HaGRID数据集详细说明:
- 共18个手势类别,每个类别约含有7000张图片,总共约123731张图片(12W);
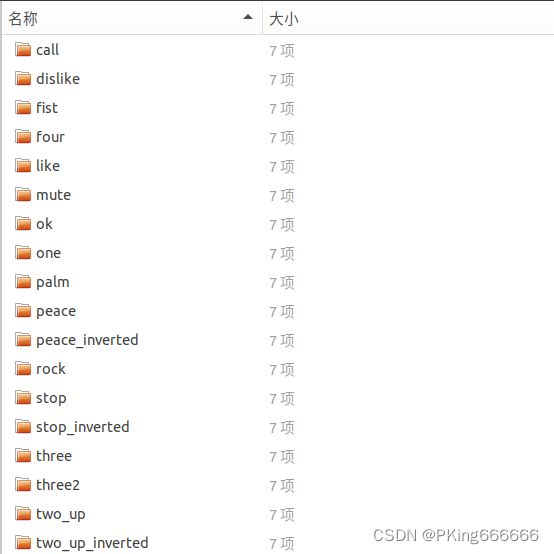
- 某些图片中存在二只手,这些图像手部被标注为 no_gesture 类
- 原始图片都是高分辨率(1920 × 1080)200W像素,已经等比例缩小到20W像素
- 原始标注文件*.json格式,为了方便训练,已经统一转换为VOC的数据格式(*.xml), 数据中Annotations文件夹保存了VOC的XML文件,JPEGImages文件夹是图像数据,这部分数据可直接用于训练目标检测模型。
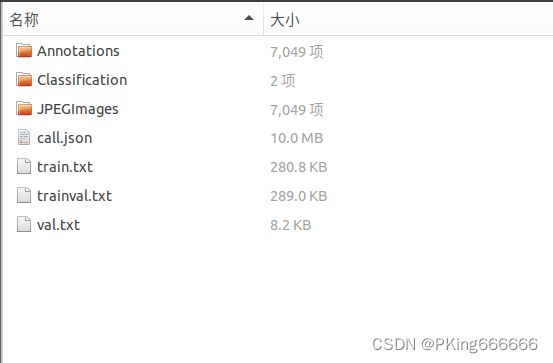
- 为了方便训练手势识别分类模型,Light-HaGRID数据集已经把每个标注框的手部区域都裁剪下来,并保存在Classification文件夹下,这部分数据可以用于训练手势识别分类模型。

-
生成数据集的Python脚本
需要安装: pip install pybaseutils
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : [email protected]
@Date : 2022-08-30 09:45:44
@Brief :
"""
import os
import numpy as np
import cv2
from tqdm import tqdm
from pybaseutils import image_utils, file_utils
from pybaseutils.maker import maker_voc
def save_voc_dataset(bboxes, labels, image_file, image_shape, out_xml_dir):
"""
保存VOC数据集
:param bboxes:
:param labels:
:param image_file:
:param image_shape:
:param out_xml_dir:
:return:
"""
basename = os.path.basename(image_file)
image_id = basename.split(".")[0]
objects = []
for box, name in zip(bboxes, labels):
objects.append({"name": name, "bndbox": box})
xml_path = file_utils.create_dir(out_xml_dir, None, "{}.xml".format(image_id))
maker_voc.write_voc_xml_objects(basename, image_shape, objects, xml_path)
def save_crop_dataset(image, bboxes, labels, image_file, crop_root):
"""
裁剪检测区域
:param image:
:param bboxes:
:param labels:
:param image_file:
:param crop_root:
:return:
"""
basename = os.path.basename(image_file)
image_id = basename.split(".")[0]
crops = image_utils.get_bboxes_image(image, bboxes, size=None)
for i, (img, label) in enumerate(zip(crops, labels)):
file = file_utils.create_dir(crop_root, label, "{}_{:0=3d}.jpg".format(image_id, i))
cv2.imwrite(file, img)
def convert_HaGRID_dataset(data_root, vis=True):
"""
将HaGRID转换为VOC和分类数据集
:param data_root: HaGRID数据集个根目录
:param vis: 是否可视化效果
:return:
"""
sub_list = file_utils.get_sub_paths(data_root)
class_names = []
for sub in sub_list:
anno_file = os.path.join(data_root, sub, "{}.json".format(sub))
annotation = file_utils.read_json_data(anno_file)
image_list = file_utils.get_images_list(os.path.join(data_root, sub, "JPEGImages"))
print("process:{},nums:{}".format(anno_file, len(image_list)))
# 保存VOC格式的xml文件
out_xml_dir = os.path.join(data_root, sub, "Annotations")
# 裁剪并保存标注框区域的图片
out_crop_dir = os.path.join(data_root, sub, "Classification")
for image_file in tqdm(image_list):
basename = os.path.basename(image_file)
image_id = basename.split(".")[0]
image = cv2.imread(image_file)
anno = annotation[image_id]
h, w = image.shape[:2]
# [top left X pos, top left Y pos, width, height]
bboxes = image_utils.rects2bboxes(anno['bboxes'])
bboxes = np.asarray(bboxes) * [w, h, w, h]
labels = anno['labels']
class_names += labels
image_shape = image.shape
assert len(bboxes) == len(labels)
if out_xml_dir:
save_voc_dataset(bboxes, labels, image_file, image_shape, out_xml_dir)
if out_crop_dir:
save_crop_dataset(image, bboxes, labels, image_file, out_crop_dir)
if vis:
image = image_utils.draw_image_bboxes_text(image, bboxes, labels, color=(255, 0, 0))
image_utils.cv_show_image("image", image, use_rgb=False)
class_names = set(class_names)
print(class_names)
if __name__ == "__main__":
data_root = "path/to/gesture/HaGRID/trainval"
convert_HaGRID_dataset(data_root, vis=True)
这是可视化标注框的效果图:
| 样图 | 样图 |
 |
 |
 |
 |
(2)Light-HaGRID数据集下载
Light-HaGRID数据集包含的资源主要有:
- 提供手势动作识别数据集,共18个手势类别,每个类别约含有7000张图片,总共123731张图片(12W+)
- 提供所有图片的json标注格式文件,即原始HaGRID数据集的标注格式
- 提供所有图片的XML标注格式文件,即转换为VOC数据集的格式
- 提供所有手势区域的图片,每个标注框的手部区域都裁剪下来,并保存在Classification文件夹下
- 可用于手势目标检测模型训练
- 可用于手势分类识别模型训练
下载地址:HaGRID手势识别数据集使用说明和下载
4. 基于目标检测的手势识别
Demo视频效果:
《基于YOLOv5的手势识别系统(含手势识别数据集+训练代码)》 https://panjinquan.blog.csdn.net/article/details/126750433
5. 基于目标检测+分类识别的手势识别
正在开发中,敬请期待