无监督学习-K均值聚类
目录
1. 聚类算法
1.1 聚类(Clustering)的定义
1.2 分类 vs. 聚类
1.3 外部准则
1.4 聚类的要求
1.5 偏平聚类 vs. 层次聚类
2. K-Means算法
2.1 扁平算法
2.2 K-均值聚类算法
2.3 实例
2.4 K-均值聚类算法步骤
2.5 实战
2.6 K-均值算法的决定性因素
3. 层次聚类算法
3.2 层次聚类算法分类
3.3 层次凝聚算法(HAC)
3.4 关键问题:如何定义簇相似度
3.5 实战--簇间相似度
3.6 实战
1. 聚类算法
1.1 聚类(Clustering)的定义
有一天老板给你一堆数据,然后他说,你给我分出几类来
聚类目的在将相似的事物归类。聚类分析又称为“同质分组”或者“无监督的分类指把一组数据分成不同的“簇”,每簇中的数据相似而不同簇间的数据则距离较远。
●簇内文档之间应该彼此相似
●簇间文档之间差异大
无监督意味着没有已标注好的数据集
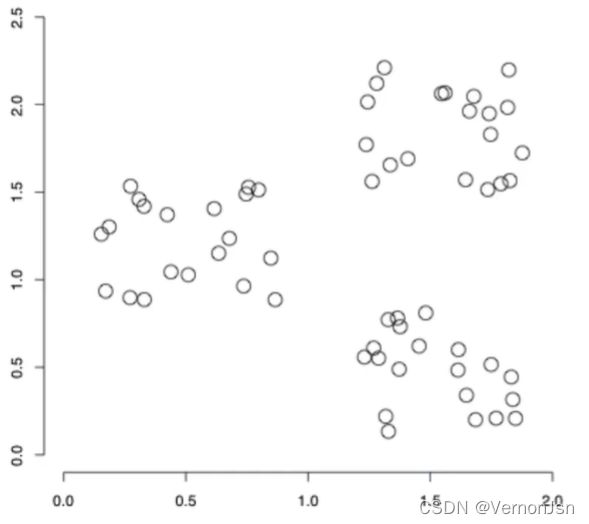 提出一个算法来寻找该例中的簇结构
提出一个算法来寻找该例中的簇结构
1.2 分类 vs. 聚类
■分类:有监督的学习.
■聚类:无监督的学习
■分类:类别事先人工定义好,并且是学习算法的输入的一部分
■聚类:簇在没有人工输入的情况下从数据中推理而得
但是,很多因素会影响聚类的输出结果:簇的个数、相似度计算方法、文档的表示方式,等等
1.3 外部准则
- 基于已有标注的标准数据集来进行聚类评价
- 目标:聚类结果和给定分类结果一致(当然,聚类中我们并不知道最后每个簇的标签,而只是关注如何将文档分到不同的组中)
- 一个评价指标:纯度(purity)
计算纯度公式: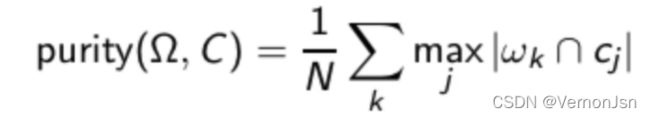
![]() 是簇的集合
是簇的集合
![]() 是类别的集合
是类别的集合
对每个簇![]() :找到一个类别
:找到一个类别![]() ,该类别包含
,该类别包含![]() 中的元素最多,为
中的元素最多,为![]() 个,也就是说
个,也就是说![]() 的元素最多分布在
的元素最多分布在![]() 中
中
将所有![]() 求和,然后除以所有的文档数目
求和,然后除以所有的文档数目
计算纯度的例子:
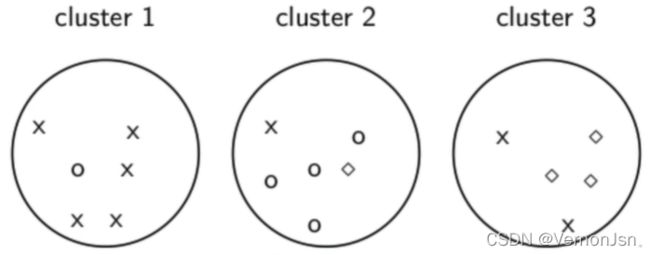
为计算纯度:
maxj| w1∩cj|= 5 (class x, cluster 1); ( 6个里面有5个叉叉)
maxj |w2∩cj | =4 (class O, cluster 2);
maxj |w3∩cj|= 3 (class![]() , cluster 3)
, cluster 3)
纯度为:(1/17) X (5+ 4+ 3)≈0.71.
1.4 聚类的要求
一般目标:将相关文档放到- -个簇中,将不相关文档放到不同簇中如何对.上述目标进行形式化?
●簇的数目应该合适,以便与聚类的数据集相吻合
●一开始,我们假设给定簇的数目为K。
聚类的其它目标
●避免非常小和非常大的簇
●定义的簇对用户来说很容易理解
1.5 偏平聚类 vs. 层次聚类
扁平算法
●通过一开始将全部或部分文档随机划分为不同的组通过迭代方式不断修正
●代表算法: K-均值聚类算法
层次算法.
●构建具有层次结构的簇
●自底向上(Bottom-up)的算法称为凝聚式(agglomerative)算法
●自顶向下(Top-down)的算法称为分裂式(divisive)算法
2. K-Means算法
2.1 扁平算法
➢扁平算法步骤
●扁平算法将N篇文档划分成K个簇
●给定一个文档集合及聚类结果簇的个数K
●寻找一个划分将这个文档集合分成K个簇,该结果满足某个最优划分准则
➢全局优化:穷举所有的划分结果,从中选择最优的那个划分结果
●无法处理
➢高效的启发式方法: K-均值聚类算法
K平均聚类发明于1956年,该算法最常见的形式是采用被称为劳埃德算法(Lloyd algorithm)的迭代式改进探索法。
●劳埃德算法首先把输入点分成k个初始化分组,可以是随机的或者使用一些启发式数据。
●然后计算每组的中心点,根据中心点的位置把对象分到离它最近的中心,重新确定分组。
●继续重复不断地计算中心并重新分组。
●直到收敛,即对象不再改变分组( 中心点位置不再改变)。
2.2 K-均值聚类算法
➢或许是最著名的聚类算法
➢算法十分简单,但是在很多情况下效果不错
➢是文档聚类的默认或基准算法
K是什么? k是聚类算法当中类的个数。means是什么? means是均值算法。总而言之,Kmeans是用均值算法把数据分成K个类的算法!
- K-均值聚类算法中的每个簇都定义为其质心向量
- 划分准则:使得所有文档到其所在簇的质心向量的平方和最小
- 质心向量的定义:
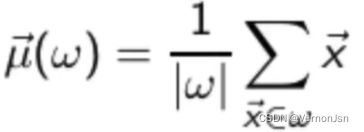 其中w代表-个簇
其中w代表-个簇
通过下列两步来实现目标优化:
●重分配(reassignment): 将每篇文档分配给离它最近的簇
●重计算(recomputation):重新计算每个簇的质心向量
2.3 实例
首先我们要把一下数据分成两类:
(1)我们随机选取两个种子(K-2)



(2)将文档分配给离它最近的质心向量(第一次)====>(3)分配后的簇(第一次)

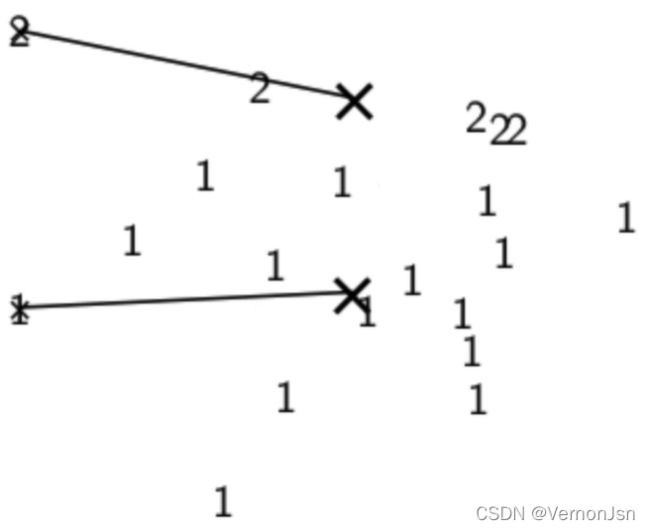
(4)重新计算质心向量;(5)将文档分配给离它最近的质心向量(第二次);(6)重新分配的结果;
(7)重新计算质心向量;(8)再重新分配(第三次);(9)分配结果
(10)重新计算质心向量;(11)再重新分配(第四次);(12)分配结果
(13)重新计算质心向量;(14)再重新分配(第五次);(15)分配结果
(16)重新计算质心向量;(17)再重新分配(第六次);(18)分配结果
(19)重新计算质心向量;(20)再重新分配(第七次);(21)分配结果
(22)重新计算质心向量;(23)质心向量和分配结果最终收敛
2.4 K-均值聚类算法步骤
K-均值聚类算法- -定是收敛的
●但是不知道达到收敛所需要的时间!
●如果不太关心少许文档在不同簇之间来回交叉的话,收敛速度通常会很快(< 10-20次迭代)
●但是,完全的收敛需要多得多的迭代过程
K-means的损失函数是平方误差:
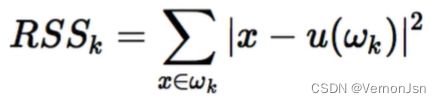
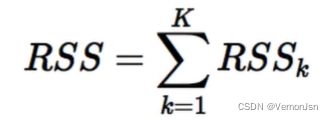
总结:
在已知簇的个数时,可很好地实现数据的聚类分析。
基本思想:
●首先,随机选择k个数据点做为聚类中心
● 然后,计算其它点到这些聚类中心点的距离,通过对簇中距离平均值的计算,不断改变这些聚类中心的位置,直到这些聚类中心不再变化为止。如图所示:
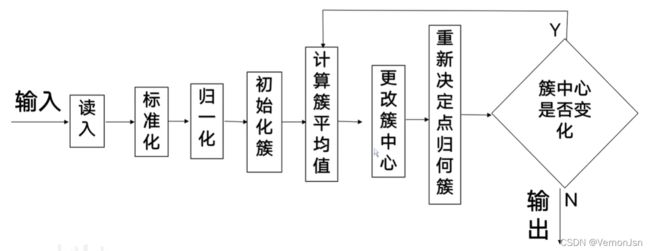
2.5 实战
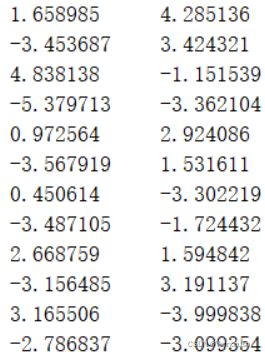
数据存在testSet.txt文件中,部分截图:(两列数据)
分析数据实现代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
#先分析数据
fr=open('testSet.txt')
numberOfLines=len(fr.readlines())#读出总行数
fr.close();
dataset= np.zeros((numberOfLines,2))#定义一个行数+2列的矩阵
fr = open('testSet.txt')
index = 0
for line in fr.readlines():
listFromLine = line.split('\t')#文件以‘\t’进行分割
dataset[index,0] = listFromLine [0]
dataset[index,1] = listFromLine [1]
index += 1
fr.close();
print(dataset)
plt.scatter(dataset[:,0], dataset[:,1])#通过绘图把数据显示出来实现结果:
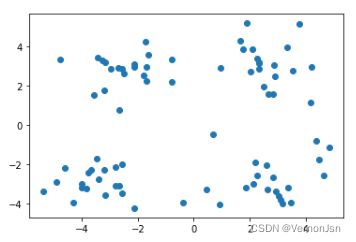
我们可以看出数据存在4中分类结果,然后我们使用K-Means算法去分类
实现代码:
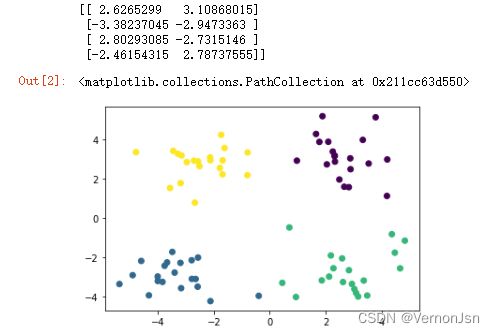
model=KMeans(n_clusters=4)
model.fit(dataset)
print(model.cluster_centers_)#打印聚类中心
plt.scatter(dataset[:,0],dataset[:,1],c=model.labels_)实现结果:
2.6 K-均值算法的决定性因素
1)始中心点
2)输入的数据及K值的选择
3)距离度量
2.6.1 初始化
初始值敏感:初始化4个类别中心,左侧的全体数据仅与第-个类别中心相似。
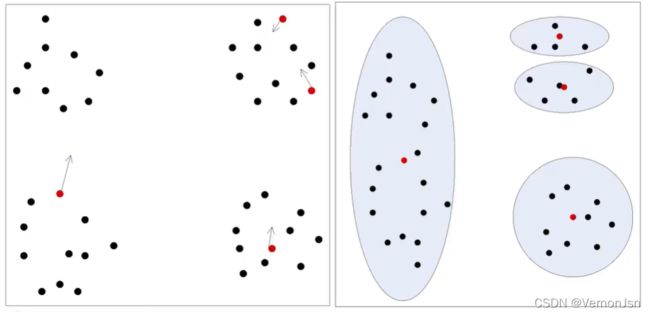
➢种子的随机选择只是K-均值聚类算法的一种初始化方法之一
➢ 随机选择不太鲁棒:可能会获得一个次优的聚类结果
➢一些确定初始质心向量的更好办法:
• 非随机地采用某些启发式方法来选择种子(比如,过滤掉一些离群点,或者寻找具有较好文档空间覆盖度的种子集合)
• 采用层级聚类算法寻找好的种子
•选择 i (比如 i = 10) 次不同的随机种子集合,对每次产生的随机种子集合运行K-均值聚类算法 ,最后选择具有最小RSS值的聚类结果,即多做几次选最好的。
2.6.2 簇个数的确定
• 在很多应用中,簇个数K是事先给定的,比如,可能存在对K的外部限制
• 如果没有外部的限制会怎样?是否存在正确的簇个数?
• 一种办法:定义一个优化准则(簇间距离大,簇内距离小)我们可以将簇间与簇内的距离量化。
连续值的相似度计算:

二值离散型的相似度计算:
1)二值离散型属性只有0和1两个取值。
●其中: 0表示该属性为空,1表示该属性存在。
●例如:描述病人的是否抽烟的属性(smoker),取值为1表示病人抽烟,取值0表示病人不抽烟。
2)假设两个样本Xi和Xj分别表示成如下形式:
■![]()
■![]()
●它们都是p维的特征向量,并且每维特征都是一个二值离散型数值。
计算方式如下:
1)假设二值离散型属性的两个取值具有相同的权重,则可以得到一-个两行两列的可能性矩阵。
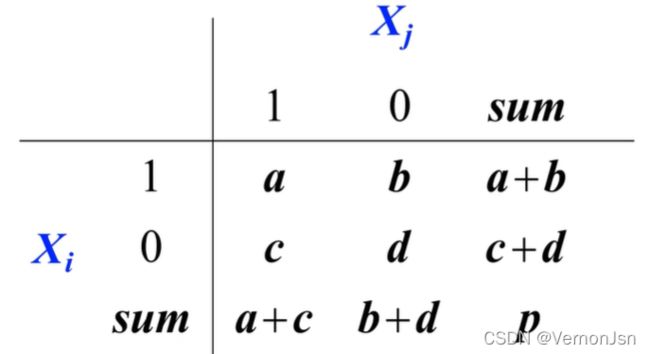
2)如果样本的属性都是对称的二值离散型属性,则样本间的距离可用简单匹配系数(Simple Matching Coefficients, SMC)计算:![]() ,通俗来说就是不相同除以相同
,通俗来说就是不相同除以相同
●其中:对称的二值离散型属性是指属性取值为1或者0同等重要。
●例如:性别就是一个对称的二值离散型属性,即:用1表示男性,用0表示女性;或者用0表示男性,用1表示女性是等价的,属性的两个取值没有主次之分。
3)如果样本的属性都是不对称的二值离散型属性,则样本间的距离可用Jaccard系数计算(Jaccard Coefficients, JC):![]()
●其中:不对称的二值离散型属性是指属性取值为1或者0不是同等重要。
●例如:血液的检查结果是不对称的二值离散型属性,阳性结果的重要程度高于阴性结果,因此通常用1来表示阳性结果,而用0来表示阴性结果。
为了更加了解这个计算过程,举个例子:
例:已知两个样本p=[1 00 0000000]和q= [000000100 1],可以得出a=0,b=1,c=2,d=7![]()
![]()
3. 层次聚类算法
层次聚类的目标是生成类似于目录的一个层次结构:
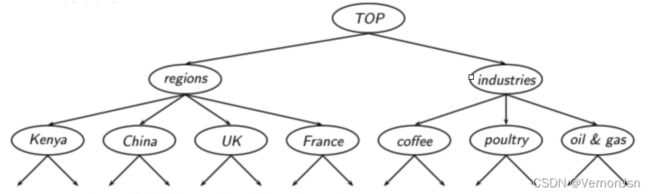
这个层次结构是自动创建的,可以通过自顶向下或自底向上的方法来实现。
3.1 定义
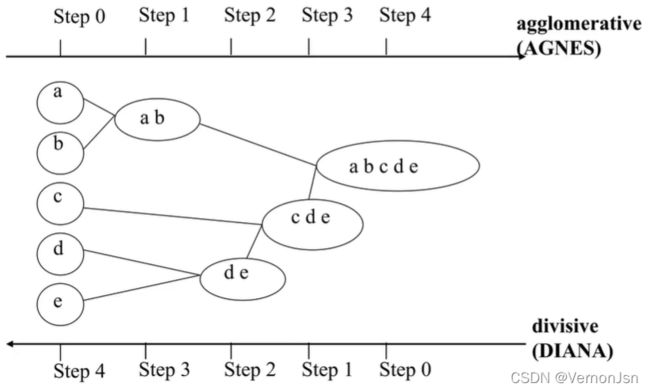
3.2 层次聚类算法分类
对给定的数据集进行层次分解:
●自底向上方法(合并) :开始时,将每个样本作为单独的一个组;然后,依次合并相近的样本或组,直至所有样本或组被合并为一个组或者达到终止条件为止。
代表算法: AGNES算法
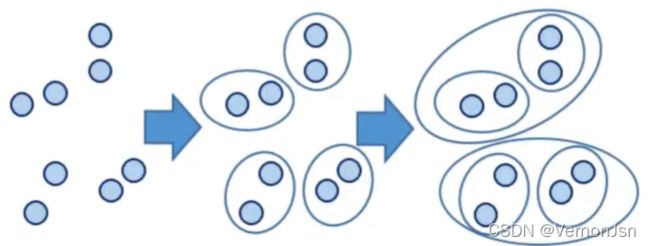
●自顶向下方法(分裂) :开始时,将所有样本置于一个簇中;然后,执行迭代,在迭代的每一步中,一个簇被分裂为多个更小的簇,直至每个样本分别在一-个单独的簇中或者达到终止条件为止。
代表算法: DIANA算法
3.3 层次凝聚算法(HAC)
HAC会生成一棵二叉树形式的类别层次结构,到目前为止,我们的相似度都定义在文档之间,现在我们假设相似度定义在两个簇之间,接下来我们考察不同的簇相似度计算方法。
1)一开始每篇文档作为一个独立的簇
2)然后,将其中最相似的两个簇进行合并
3)重复上一步直至仅剩一个簇
4)整个合并的历史构成一个二叉树
5)一个标准的描述层次聚类合并历史的方法是采用树状图(dendrogram)
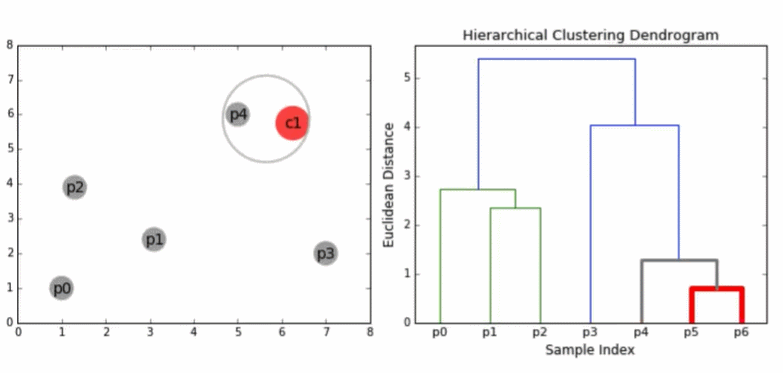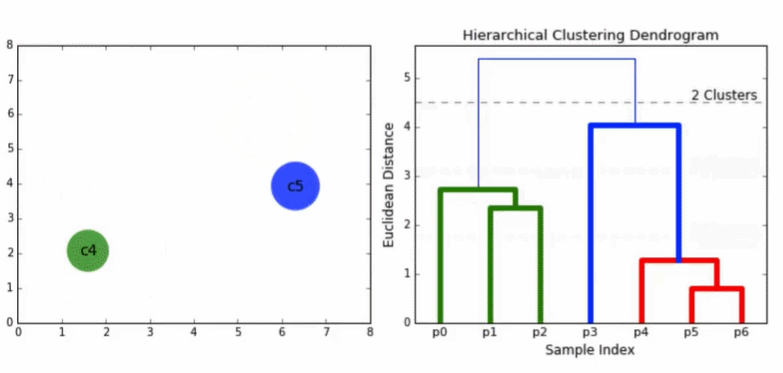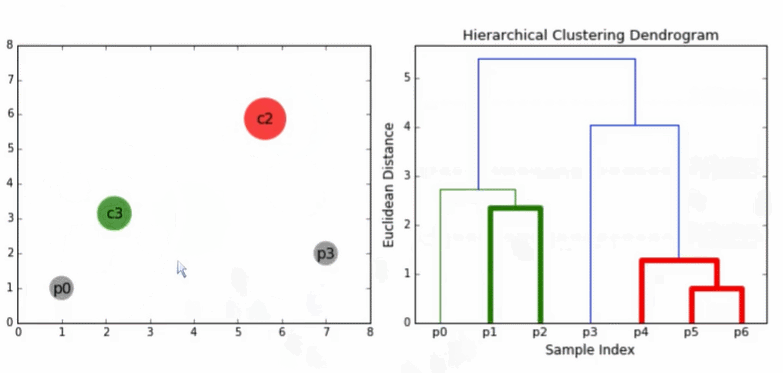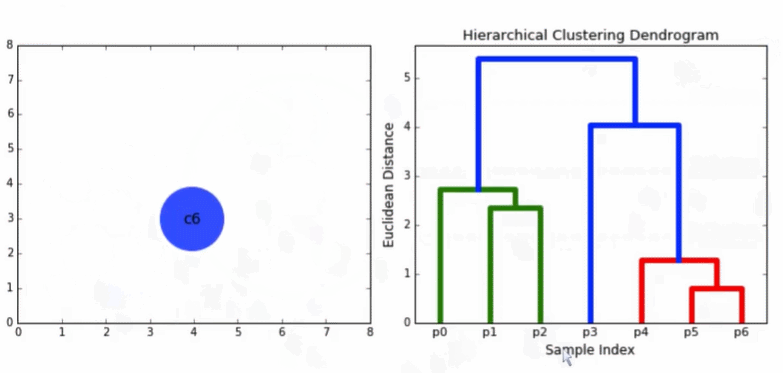
3.4 关键问题:如何定义簇相似度
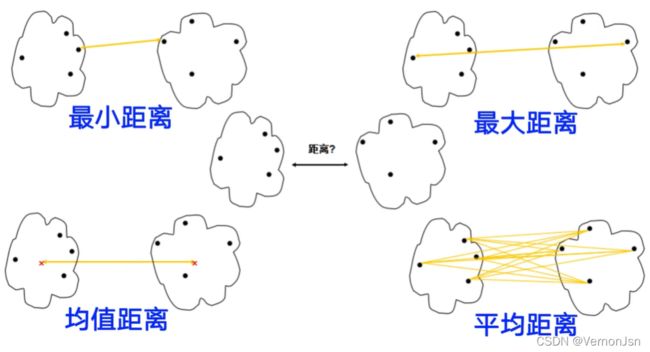
1)单连接(Single-link): 最大相似度
●计算任意两篇文档之间的相似度,取其中的最大值
2)全连接(Complete-link): 最小相似度
●计算任意两篇文档之间的相似度,取其中的最小值
3)质心法:平均的类间相似度
●所有的簇间文档对之间相似度的平均值(不包括同- -个簇内的文档之间的相似度)
●这等价于两个簇质心之间的相似度
4)组平均(Group-average): 平均的类内和类间相似度
所有的簇间文档对之间相似度的平均值(包括同一个簇内的文档之间的相似度)
簇间距离:
3.5 实战--簇间相似度
单链接步骤:最大相似度(最短距离)
●定义样品之间距离,计算样品的两两距离,得一距离阵记为D(0),开始每个样品自成一类, 显然这时Dij =dij。
●找出距离最小元素,设为Dpq,则将Gp和Gq合并成一个新类,记为Gr,即Gr= {Gp,Gq}。
●计算新类与其它类的距离。
●重复第2、3两步,直到所有元素。并成一类为止。如果某一步距离最小的元素不止一个,则对应这些最小元素的类可以同时合并
单连接:最大相似度(最短距离) 全连接:最小相似度,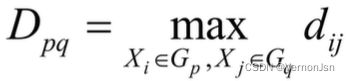
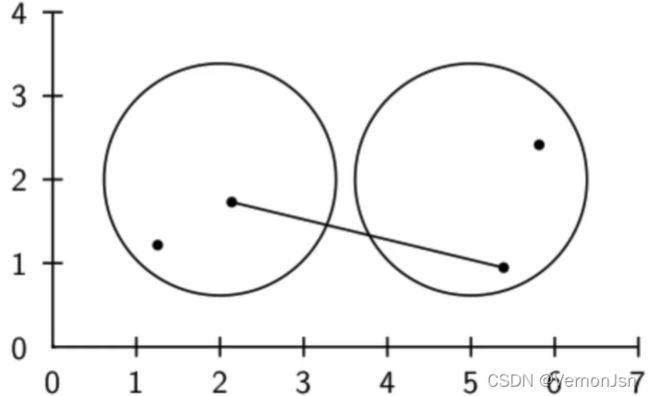
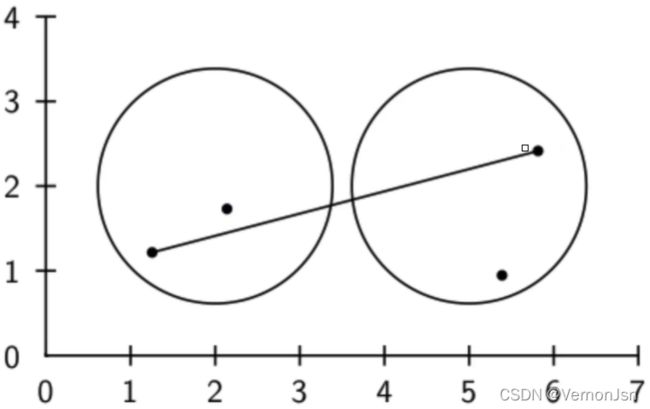
质心法: 组平均法:
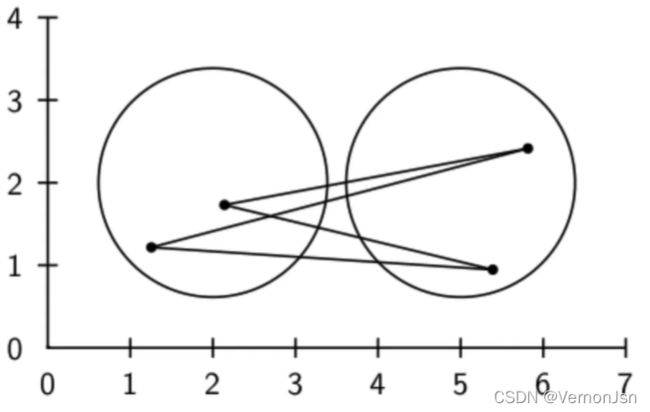
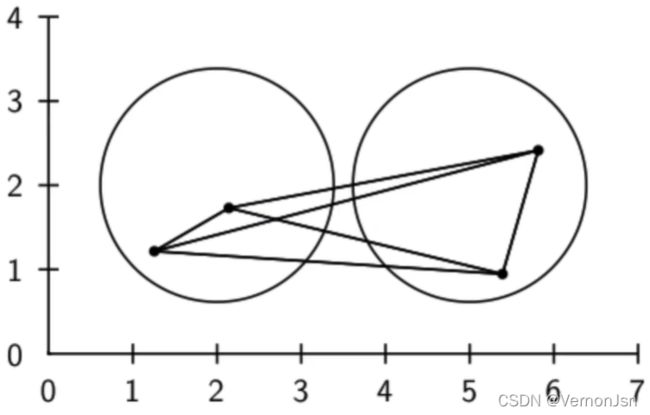
3.6 实战
例子:采用单连接和全连接方法进行聚类
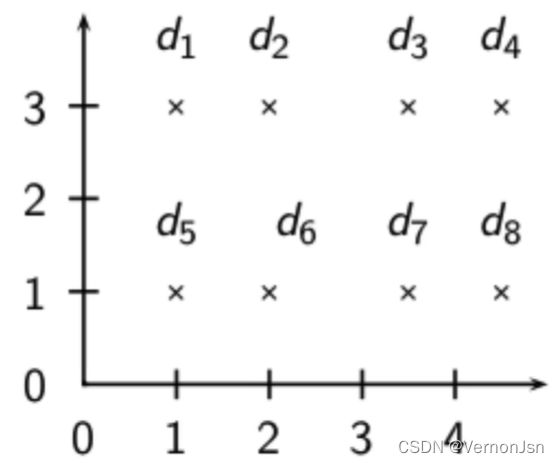
单连接 vs. 全连接
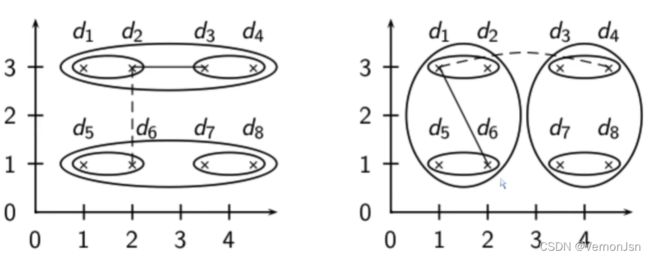
单连接方法的链化(Chaining)现象:
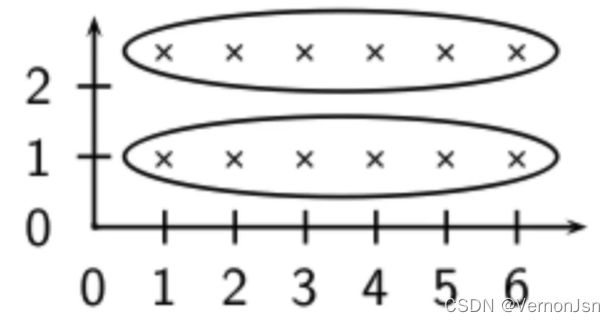
单连接聚类算法往往产生长的、凌乱的簇结构。对大部分应用来说,这些簇结构并不是所期望的。
全连接法:对离群点非常敏感
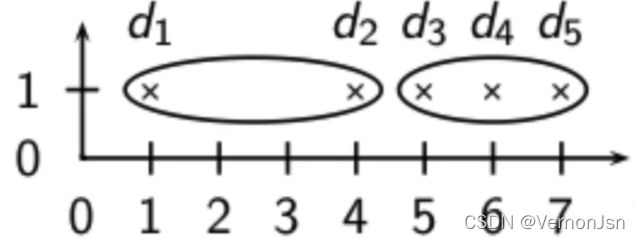
全连接聚类将d2和它的正确邻居分开----这显然不是我们所需要的;出现上述结果的最主要原因是存在离群点d1;这也表明单个离群点的存在会对全连接聚类的结果起负面影响;单连接聚类能够较好地处理这种情况。