人工智能AI 生成的艺术:从文本到图像
自从第一幅洞穴壁画出现以来,艺术一直是人类文化的主要内容。
这是我们表达自己和讲故事的一种方式。
近年来,人工智能(AI)取得了进展,人们一直在探索其在包括艺术在内的各个领域的可能应用。然而,对艺术的理解和欣赏被广泛认为完全是人类的能力。
在本文中,我们将探讨将 AI 引入循环中如何不仅可以促进数字艺术和艺术史领域的进步,还可以激发我们对艺术本身未来的看法。
以下是我们将介绍的内容:
人工智能生成艺术简史
人工智能算法如何能够创造艺术
与 AI 生成的艺术相关的挑战
最佳 AI 艺术生成器和 AI 艺术品的示例
人工智能生成艺术简史
首先,让我们把事情弄清楚一点。“人工智能与艺术”一般可以从两个方面来理解:
- 人工智能在分析现有艺术的过程中
- 人工智能在创造新艺术的过程中
我们专注于第二类,人工智能代理是产生新艺术创作的人。让我们看看人工智能生成艺术的演变。

AI 生成艺术的历史可以追溯到计算机图形学和计算机发明的早期。
在 1950 年代和 1960 年代,计算机图形被用来生成简单的图案和形状。这些早期的 AI 生成艺术示例是使用基本算法创建的,以创建在计算机屏幕上呈现的图案。
例如,德国数学家和科学家弗里德·纳克(Frieder Nake)在 1967 年创建了一个名为“矩阵乘法”的作品集,其中包含 12 张图像,您可以在下面看到其中一张。

弗里德·纳克(Frieder Nake)的《无题》(1967)
Nake产生一个方阵并用数字填充它,然后将其依次相乘,并将得到的新矩阵转换为预定间隔的图像。
每个数字都被分配了一个具有特定形式和颜色的视觉符号。然后根据矩阵的值将这些符号放置在栅格中。Nake 在他这一时期的工作中经常使用随机数生成,并且很可能,他的乘法过程是部分自动化的。
在 1970 年代和 1980 年代,人工智能生成的艺术开始在计算机辅助设计 (CAD) 中得到更广泛的应用。
CAD 软件允许设计师在计算机上创建和操作 3D 形状。这允许创建更复杂和逼真的图像。例如,1973 年,艺术家哈罗德·科恩(Harold Cohen)开发了一套算法,统称为 AARON,它允许计算机以徒手画的不规则性进行绘图。
AARON 被编程为绘制特定对象,科恩发现他的一些指令生成了他以前从未想象过的形式。他发现他已经设置了允许机器做出类似艺术决定的命令。
最初,AARON 创作了抽象画,在 1980 年代和 1990 年代发展为更复杂的艺术,包括(按时间顺序)岩石、植物和人类的绘画。一个这样的例子如下所示。

由 AARON 制作的绘画,由 Harold Cohen 开发.
在 1990 年代,人工智能生成的艺术开始不仅仅用于视觉效果。艺术家们开始使用人工智能算法来生成音乐并创作新形式的诗歌。AI 生成的艺术也开始用于机器人领域。机器人被编程来创作绘画和雕塑。
今天,人工智能生成的艺术被用于各个领域,包括广告、建筑、时尚和电影。人工智能算法用于创建逼真的图像和动画。人工智能生成的艺术也被用来创造新的音乐和诗歌形式。
最近用于艺术创作的人工智能的一个有趣例子是“人工自然历史”(2020 年),这是一个正在进行的项目,通过作者索菲亚·克雷斯波(Sofia Crespo)所称的“自然历史书从来不是。”
克雷斯波基本上形成了一系列扭曲的生物,这些生物具有想象中的特征,需要全新的生物分类。这种艺术与大自然提供的无尽多样性相得益彰,而我们对此仍然知之甚少。人工自然历史中 AI 生成的样本示例如下所示。

人工智能生成的人工自然历史标本
人工智能如何用于创作艺术,包括算法和神经网络的使用
人工智能用于创作艺术的方式有很多种。
- AI 算法可以根据一组参数生成图像或视频,或者通过组合和更改现有图像来创建新图像。神经网络可用于创建模仿特定艺术家风格的图像或视频,或创建与特定艺术类型相似的图像或视频。
- 使用其他现有艺术风格生成新艺术作品的首选技术是通过生成对抗网络。当使用深度神经网络完成时,将艺术作品的风格转移到另一种艺术的方法称为神经风格转移 (NST)。
- NST 背后的主要思想是在 2015年首次在本文中提出,为了获得输入图像风格的表示,使用最初设计用于捕获纹理信息的特征空间。
- 这个特征空间建立在网络每一层的过滤器响应之上。它由特征图空间范围内不同滤波器响应之间的相关性组成。通过包含多个层的特征相关性,作者获得了输入图像的静止、多尺度表示,该表示捕获了其纹理信息,但没有捕获全局排列。

作者通过实验发现,CNN 中内容和风格的表示是可分离的。也就是说,两种表示都可以独立操作以产生新的、感知上有意义的图像。这一发现一直是人工智能生成艺术中使用的神经风格转移文献中提出的所有连续方法的基础。
除了神经风格迁移,还有其他算法可以创造人工智能艺术——
使用人工智能创造新艺术的最具革命性的算法之一是 OpenAI 的 DALL·E 2。DALL·E 2 仅使用用户给出的文本提示生成图像。在后面的部分中,我们将更详细地讨论 DALL·E 2 的架构和功能。
GAN
本文于 2014 年提出的生成对抗网络 (GAN)通常由两个相互对抗的神经网络组成,以使它们都成为更好的学习者。
假设我们必须生成新图像来扩充用于图像分类的数据集。这两个网络之一称为生成器,即输出新图像的深度网络。另一个网络称为鉴别器,它的工作是对作为输入的图像是由生成器创建的原始图像还是假图像进行分类。
在连续的迭代中,生成器试图更接近地模仿原始图像来欺骗鉴别器,而鉴别器则试图更好地区分真实图像和假图像。这种对抗性游戏(极小极大问题)训练了两个网络。一旦训练循环完成,生成器就可以输出逼真的图像(与原始图像几乎无法区分),判别器已经成为一个很好的分类器模型。
GAN 的一些流行应用是生成:
字体
- 也可以使用 GAN 生成新的引人入胜(且一致)的字体,就像本文中提出的那样。

人脸
- 用于插图、电影人物等,减轻隐私顾虑。该网站显示了实际上并不存在的人脸图像,因为这些图像是使用StyleGAN2模型创建的。一个例子如下所示。

卡通/动漫人物
- GAN 也被用于生成卡通和动漫角色。这使作者能够获得关于人物绘画的新想法,甚至无需为他们的剧集绘制每一帧(视频序列)就可以创建场景。

草图(Sketch)
- 使用 GAN 生成草图有几个优点,例如使用多模态数据增强模型以进行风格转移、超分辨率等。它们也可以用作创建更复杂艺术的基础结构。

使用SkeGAN 模型生成的草图
AI 生成艺术的好处和挑战
现在,让我们看看使用人工智能创作艺术的利弊,并解决几个令人费解的问题。
AI 生成艺术的一些好处包括:
- 生成真实或超真实数据
使用 AI 生成的视频图像可用于电影,尤其是在现实生活中无法呈现的超自然场景。
- 有些艺术可能是人类无法创造的
人工智能跳出框框“思考”以生成前所未有的样本,其中一些样本甚至可能很难或不可能让人类思考。这种艺术甚至可以成为更重要项目的灵感来源,即它们可以帮助人们获得新想法。
- 不断发展
人工智能产生的艺术与人工智能模型的发展以及提供给此类模型进行训练的数据的演变一起不断发展。这允许新颖的想法在不停滞在饱和点的情况下流动。
人工智能生成的艺术面临的一些挑战包括:
- 缺乏人情味
尽管人工智能创造出的逼真图像很容易欺骗任何人,但它缺乏制作艺术作品背后的人类情感和艺术背后的故事。这可能是许多人接受 AI 生成的艺术的一大障碍。
- 艺术可能是重复的或无聊的
没有支持,人工智能不会产生新的艺术。我们给它提供我们已经拥有的数据来训练它。因此,在某种程度上,它产生的所有艺术都是衍生的(但它衍生自如此多的来源,以至于它在技术上成为新艺术)。因此,只训练过一次且训练过程从未使用新可用数据更新的模型可能会产生可能无趣的重复艺术。然而,像零样本学习或自我监督学习这样的新技术可以用新的可用数据训练现有模型,而无需从头开始重新训练模型。
- 对最终产品缺乏控制
我们无法控制创作过程,因为一旦我们训练模型,它就会根据训练后的权重输出产品。我们无法在此过程中手动对其进行微调。
- 道德问题
我们可能无法控制成品的发行、版权、使用或滥用。此外,人工智能生成的艺术可用于创建逼真的图像或视频,使人们相信某些不真实的东西。因此,其广泛的可访问性是福音还是诅咒是有争议的。
在谈论 AI 生成的艺术时,有两个主要问题让人们感到困惑:
- 你能卖 AI 生成的艺术品吗?
是的,您可以出售他们的 AI 模型生成的艺术品。AI 生成的艺术是增长最快的不可替代代币 (NFT) 之一。因此,任何人都可以使用 AI 创作艺术品并将其作为 NFT 在各种市场上出售。有几个流行销售 AI 生成艺术的例子。
例如,2018 年 10 月,一个名为“Edmond de Belamy”的艺术团体“Obvious”以 432,000 美元的价格售出了下图。虽然是 AI 模型创建了肖像,但这笔钱是由人类赚取的,即艺术团体是归功于这幅画。本文研究了应该因 AI 算法生成的艺术而获得赞誉的实体。

如果 AI 生成的 NFT 是您的一杯茶,您可能想看看AImade.art — AI 生成的 NFT 艺术品的集合。
- 人工智能生成的艺术应该受版权保护吗?
这是一个棘手的问题,因为每个人对此都有不同的看法。一些国家已经为人工智能生成的艺术启用了版权保护,而另一些国家则不同意。
一方面,该论点认为该算法是做这项工作的人,因此它可以很容易地被其他人复制,从而使版权主张无效。
另一方面,相同的人工智能算法将根据艺术家提供的训练数据产生不同的艺术。
因此,这个问题还没有“正确”的答案。尽管如此,到目前为止,人工智能生成的艺术是免费的。
最佳 AI 生成艺术和生成器示例
在本节中,我们将仔细研究一些用于 AI 生成艺术的可用工具,并展示它们如何工作的示例。
其中许多工具都是开源的,因此您可以训练您的模型或使用现有的模型(有些可以免费使用有限次数)来使用 AI 创建您的艺术。
图像/图纸
最新的 AI 生成的艺术方法已经在图像数据上进行了实验——逼真的图像和绘图。在本节中,我们将讨论一些目前可用于图像生成的最流行的 AI 模型。
从和 2
DALL·E 2 是最近开创性的深度学习算法,可以根据使用自然语言(文本)提供的描述生成原始、逼真的图像和艺术。
它由 OpenAI 于 2021 年 1 月创建并发布。它是 2020 年 12 月发布的原始 DALL·E 算法的改进版本。DALL·E 2 还可以编辑现有图像并创建所提供图像的变体,同时保留其区分度特征。
本文提出的 DALL·E 2 模型结合了两种值得注意的方法来解决文本条件图像生成问题——
CLIP模型是图像的成功表示学习器,而扩散模型是生成建模框架,在图像和视频生成任务中取得了最先进的性能。
DALL·E 2 包含一个扩散解码器,用于反转 CLIP 图像编码器。该模型的逆变器是非确定性的,可以生成与给定图像嵌入相对应的多个图像。
编码器及其近似逆(解码器)的存在允许超出文本到图像转换的能力。DALL·E 2 模型的高级架构如下所示。
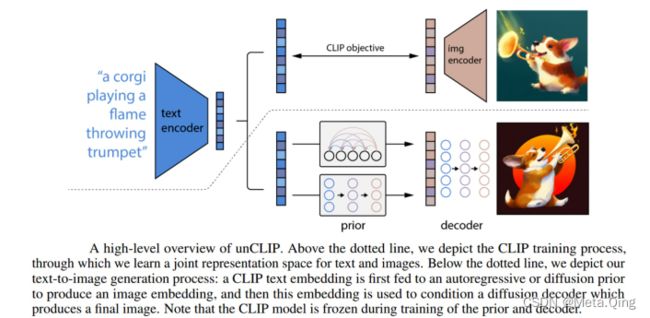
使用 CLIP 潜在空间的一个显着优势是能够通过在任何编码文本向量的方向上移动来对图像进行语义修改,而在 GAN 潜在空间中发现这些方向需要运气和勤奋的手动检查。

资料来源:论文
DALL·E 2 的一些潜在实际应用包括:
- 创建照片般逼真的 3D 渲染
- 为广告或产品设计生成图像
- 创建新的艺术或可视化
让我们看一些 DALL·E 2 使用文字说明的 AI 生成艺术示例:

左边是“古色古香的花店店面照片,有柔和的绿色和干净的白色门面,敞开的门和大窗户”,右边是“穿着贝雷帽和黑色高领毛衣的柴犬”
以下是 DALL·E 2 使用自然文本字幕生成的艺术作品示例:

左边:“用人类灵魂制作咖啡的浓缩咖啡机”,来源:Paper
右边:“土星上穿着宇航员服的海豚”,来源:Paper
DALL·E 2 还可以通过反转其图像嵌入的插值在输入图像之间进行插值。DALL·E 2 通过使用球面插值在两个图像的 CLIP 嵌入之间旋转,产生中间 CLIP 表示并使用扩散模型进行解码来做到这一点。
中间变体自然地融合了两个输入图像的内容和风格。这种插值图像的示例如下所示。


与其他图像表示模型相比,使用 CLIP 嵌入的一个关键优势在于它将图像和文本嵌入到相同的潜在空间中,从而允许我们应用语言引导的图像操作。
为了修改图像以反映新的文本描述,DALL·E 2 首先获得其 CLIP 文本嵌入和描述当前图像的标题的 CLIP 文本嵌入。然后通过获取它们的差异并对其进行归一化来计算文本差异向量。
这方面的例子如下所示。

更多 DALL·E 2 的艺术作品示例可在模特的专用Instagram 页面上找到。您还可以与 DALL·E 2 的小弟弟DALL·E Mini一起玩,从您自己的文本中创建 AI 生成的艺术。
如果 DALL·E 2 引起你的兴趣足以让你怀疑它是否可以取代人类,请观看此视频:
稳定扩散
Stable Diffusion 是一种革命性的文本到图像模型,与 DALL·E 2 模型非常相似,但有一个非常显着的区别——它是开源的(与 DALL·E 2 不同)——即可以使用和重新分发原始源代码免费,其他人可以从源代码中获取灵感来制作自己的模型。
该框架由机器视觉和学习小组、Stability AI和Runway合作开发。Stable Diffusion 的完整实现在GitHub 上提供,任何具有 python 基础知识的人都可以执行代码(运行代码的完整说明由作者慷慨提供)并免费生成自己的图像。
潜在扩散模型
稳定扩散建立在机器视觉与学习小组于 2022 年提出的潜在扩散模型(LDM)之上,该模型专为高分辨率图像合成而构建。作者使用 LDM 的目的是首先找到一个感知等效但计算上更合适的空间,在该空间中训练扩散模型以进行高分辨率图像合成。LDM 框架的概述如下所示。
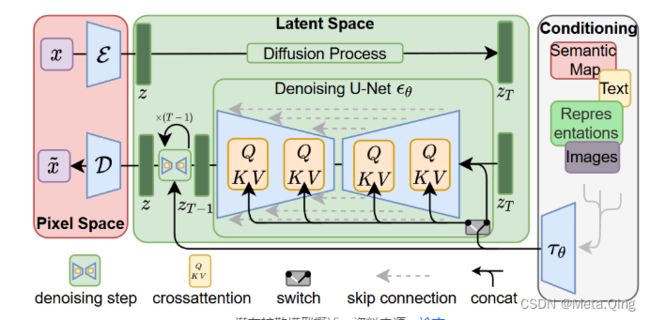
这种方法的一个显着优势是我们只需要训练一次通用自动编码阶段,因此可以将其重用于多个扩散模型的训练或探索可能完全不同的任务。这使得能够有效探索用于各种图像到图像和文本到图像任务的大量扩散模型。对于文本到图像的任务,作者设计了一种架构,将转换器连接到扩散模型的 UNet 主干,并启用任意类型的基于令牌的调节机制。
稳定的扩散架构
稳定扩散框架在来自LAION-5B 数据库子集的 512x512 图像上训练潜在扩散模型。它使用冻结的CLIP ViT-L/14文本编码器根据文本提示和 UNet 自动编码器调整模型。稳定扩散本质上是一种 LDM,它以 CLIP ViT-L/14 文本编码器的非池化文本嵌入为条件。
DreamStudio| 梦想工作室
DreamStudio是稳定扩散的官方团队界面和 API。借助 DreamStudio,用户无需任何 Python 知识即可使用 Stable Diffusion。在 DreamStudio 界面中输入文本提示会在几秒钟内生成图像。只需使用电子邮件地址注册,DreamStudio 即可免费使用 50 次。
下面显示了通过 DreamStudio 软件使用稳定扩散模型从文本提示生成的图像示例。



图片
Imagen 是 Google Brain 最近开发的文本到图像扩散模型。Imagen 包括一个T5-XXL编码器,用于将输入文本映射到一系列嵌入和一个 64×64 图像扩散模型,然后是两个超分辨率扩散模型,用于生成放大的 256×256 和 1024×1024 图像。
所有扩散模型都以文本嵌入序列为条件,并使用无分类器指导。Imagen 依靠新的采样技术来允许使用较大的引导权重,而不会在先前的工作中观察到样本质量下降,从而产生比以前可能具有更高保真度和更好的图像文本对齐的图像。Imagen 模型的概述如下所示。
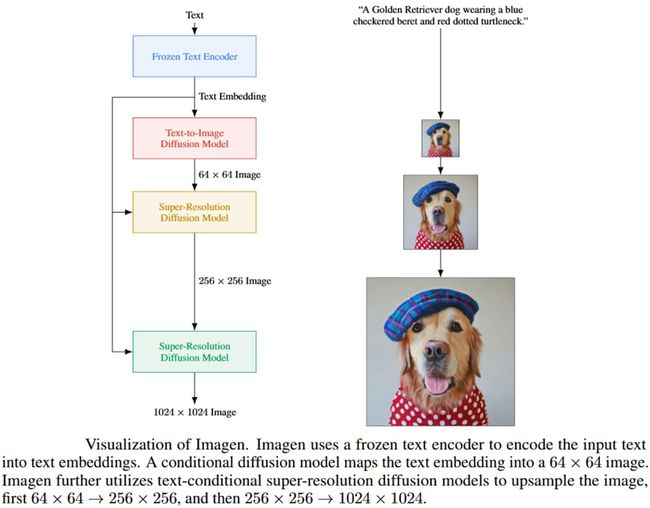
资料来源:论文
Imagen 生成的一些图像示例如下所示。

左起 1) “竹制安卓吉祥物”。源2)“一束光从天花板进入房间。光束照亮了画架。在画架上,有一幅伦勃朗的浣熊画。” 来源3)“一只狗好奇地照镜子,看到一只猫。” 资源
WOMBO梦想
WOMBO Dream 是一款人工智能艺术作品应用程序,您可以在其中输入文字提示并选择艺术风格以生成新的艺术形象。
它建立在两个 AI 模型——VQGAN和CLIP之上。VQGAN 是一种深度学习模型,用于生成看起来与其他图像相似的图像(神经风格迁移)。CLIP 是一个经过训练的深度模型,用于确定自然文本描述和图像之间的相似性。
CLIP 向 VQGAN 提供有关如何最好地将图像与文本提示匹配的反馈。VQGAN 会相应地调整图像并将其传递回 CLIP 以检查它与文本的匹配程度。这个迭代过程重复了几次,最终的图像作为结果输出。
WOMBO Dream 应用程序在迭代中给出文本提示的输出示例如下所示。

DeepDream |
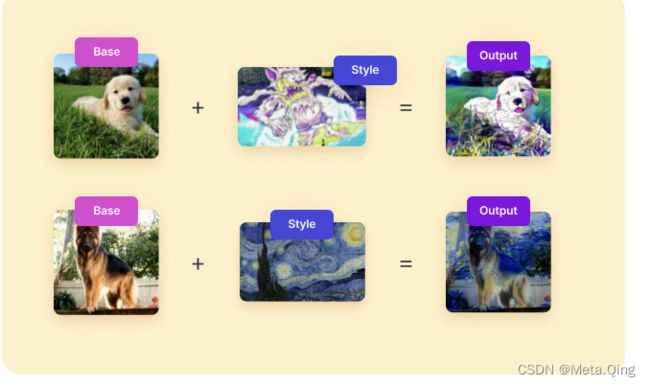
DeepDream Generator 是 Google 的另一个项目,它像我们迄今为止看到的所有其他生成器一样接收输入图像,并使用不同的风格输出梦幻般的迷幻图像,描绘出我们“梦想”的奇异事物。这是神经风格迁移的又一个例子。
使用 DeepDream 生成器(已公开用于生成图像)生成的图像示例如下所示。
更广泛的艺术
Artbreeder 是一个基于 AI 的协作网站,允许用户生成和修改他们的肖像和风景图像。
用户可以组合多个图像以轻松创建新图像。其核心有两个基于 GAN 的模型——StyleGAN和BigGAN模型。
Artbreeder 的功能示例如下所示:

音乐与声音
AI 生成艺术的能力不仅限于绘画——
点唱机
深度生成模型现在可以产生高保真音乐。例如,OpenAI 的 Jukebox是一个模型,它可以在原始音频域中生成带有歌声的音乐,具有跨越数分钟的长距离连贯性。
Jukebox 使用分层VQ-VAE架构将音频压缩到离散空间中,其损失函数旨在在增加压缩级别时保留最大量的音乐信息。Jukebox 模型的概述如下所示。
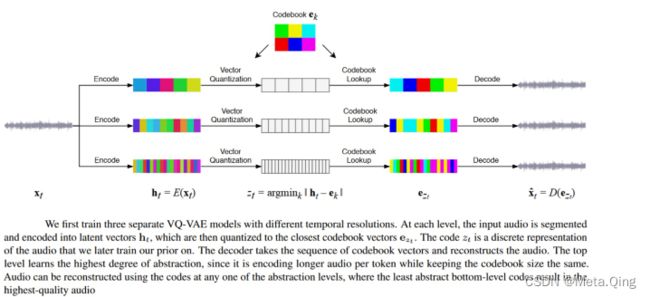
他是
AIVA 应用程序允许用户使用 AI 创作音乐。有几首著名的 AI 歌曲,例如Bored With This Desire To Get Ripped、Deliverance Rides等等。其中一些人工智能生成的歌曲甚至有著名歌手的声音(尽管他们从未真正演唱过)。
运动与舞蹈
舞蹈编排是一项特别困难的工作,因为“描述”舞蹈并不简单。它高度依赖于风格、情感和技术。
编排是有目的地安排动作序列。基本构建块是 3D 空间中的位置变化。捕获舞蹈数据是通过使用人体姿势估计技术完成的,该技术将捕获数据的维度减少了几倍,从而允许 AI 模型以较少的计算负担对其进行训练。
然而,人工智能甚至能够生成编舞片段,其中一个早期的例子是2016 年开发的 chor-rnn模型。chor-rnn 的核心是一个深度循环神经网络,它在原始动作捕捉数据上进行训练,可以生成新的独舞者的舞蹈序列。
最近的文献中提出了许多新技术,包括 AI 生成的 3D 编排。
电影
为电影编写脚本可以被视为自然语言处理 (NLP) 任务。AI 甚至可以编写整个剧本。例如,2016 年,奥斯卡·夏普执导的科幻短片《太阳之泉》的剧本完全由 AI 编写。
最具革命性的 NLP 模型之一是生成式预训练 Transformer-3 (GPT-3) 架构。它是一个 1750 亿参数的自回归语言模型,可以生成具有出色连贯性的类人文本。
GPT-3 已被广泛用于编写剧本、诗歌等。在本文中,研究人员创建了一个可以自动生成电影预告片的 AI 模型。他们的模型可以为任何没有重大剧透的电影制作合适的、引人入胜的预告片(视频)。
故事
与图像非常相似,可以使用我们拥有的 AI 模型生成整个故事,方法是提供描述主题的提示以及您希望 AI 模型编写的故事的一些高级信息。
例如,Tristrum Tuttle 有一个训练有素的 GPT-3 模型,用于编写故事以及使用提示的标题:“写一个简短的虚构故事的开头,讲述一个害怕人工智能但随后与机器人交朋友的孩子。”
概括
在过去的几十年里,人工智能作为艺术家的潜力已经显着增加——从创造超现实的图像到写电影。生成模型被广泛用于完成这些任务,当提供足够的训练数据时,可以生成新数据。
然而,人们对 AI 生成的艺术创作(除了伦理问题)存在担忧,例如缺乏将艺术家与其艺术联系起来的个性化。因此,尽管人工智能生成的艺术以高价出售,但人们还是有点担心会失去由真人创作的传统艺术。另一方面,随着脑电图(EEG)技术的发展,通过捕捉艺术家的思想(即捕捉大脑信号),个性甚至可以应用于人工智能生成的艺术。
AI 生成艺术的未来仍然很模糊,但我们现在拥有的 AI 技术确实能够创建可以欺骗我们人类的图像、视频或文本。因此,人工智能艺术的可能性既令人兴奋又令人恐惧。