联邦学习综述(一)——联邦学习的背景、定义及价值
文章目录
- 第一章:联邦学习背景
-
- 1.1 现状
- 1.2 挑战
- 1.3 联邦学习解决方案
- 1.4 联邦学习
- 第二章:定义及价值
-
- 2.1 概述
- 2.2 定义
- 2.3 公共价值
- 2.4 商业价值
- 2.5 联邦学习与现有研究的关系
第一章:联邦学习背景
1.1 现状
AlphaGo的巨大成功使得人们自然而然地希望像这种大数据驱动的人工智能会在各行各业得以实现。但是真实的情况却让人非常失望:除了有限的几个行业,更多领域存在着数据有限且质量较差的问题,不足以支撑人工智能技术的实现.更多的应用领域有的只是小数据,或者质量很差的数据.这种"人工智能到处可用”的错误的认知会导致很严重的商业后果.
例如在医疗领域需要非常多的标注数据,而医生的时间却非常宝贵,不能像其他的一些计算机视觉应用一样,可以由大众普通人来完成数据标注.所以在医疗这样的专业领域,这种标注的数据非常有限.有人估计,把医疗数据放在第三方公司标注,需要动用1万人用长达10年的时间才能收集到有效的数据.这就说明,在这些领域,即使动用很多人来做标注,数据也不够。这就是我们面临的现实。
同时数据源之间存在着难以打破的壁垒,一般情况下人工智能的所需要的数据会涉及多个领域,例如在基于人工智能的产品推荐服务中,产品销售方拥有产品的数据、用户购买商品的数据,但是没有用户购买能力和支付习惯的数据.在大多数行业中,数据是以孤岛的形式存在的数据孤岛(data silos),由于行业竞争、隐私安全、行政手续复杂等问题即使是在同一个公司的不同部门之间实现数据整合也面临着重重阻力,在现实中想要将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的.
1.2 挑战
随着大数据的进一步发展,重视数据隐私和安全已经成为了世界性的趋势.每一次公众数据的泄露都会引起媒体和公众的极大关注,例如最近 Facebook的数据泄露事件就引起了大范围的抗议行动.同时各国都在加强对数据安全和隐私的保护,欧盟 2018 年正式施行的法案《通用数据保护条例》(GeneralData Protection Regulation,GDPR)表明,对用户数据隐私和安全管理的日趋严格将是世界趋势.这给人工智能领域带来了前所未有的挑战,研究界和企业界目前的情况是收集数据的一方通常不是使用数据的一方,如 A 方收集数据,转移到 B方清洗,再转移到C方建模,最后将模型卖给 D方使用.这种数据在实体间转移,交换和交易的形式违反了GDPR,并可能遭到法案严厉的惩罚.同样,中国在2017年起实施的《中华人民共和国网络安全法》叫和《中华人民共和国民法总则》中也指出网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务。这些法规的建立在不同程度上对人工智能传统的数据处理模式提出了新的挑战.在这个问题上,人工智能的学界和企业界,目前并无较好的解决方案来应对这些挑战。
1.3 联邦学习解决方案
要解决大数据的困境,仅仅靠传统的方法已经出现瓶颈.两个公司简单的交换数据在很多法规包括 GDPR是不允许的.用户是原始数据的拥有者,在用户没有批准的情况下,公司间不能交换数据.其次,数据建模使用的目的,在用户认可前不可以改变.所以,过去的许多数据交换的尝试,例如数据交易所的数据交换,也需要巨大的改变才能合规.同时,商业公司所拥有的数据往往有巨大的潜在价值.两个公司甚至公司间的部门都要考虑利益的交换,在这个前提下,往往这些部门不会把数据与其他部门做简单的聚合。这将导致即使在同一个公司内,数据也往往以孤岛形式出现。
如何在满足数据隐私、安全和监管要求的前提下,设计一个机器学习框架,让人工智能系统能够更加高效、准确地共同使用各自的数据,是当前人工智能发展的一个重要课题。我们倡议把研究的重点转移到如何解决数据孤岛的问题。我们提出一个满足隐私保护和数据安全的一个可行的解决方案,叫做联邦学习(Federalted learning)
1.4 联邦学习
- 各方数据都保留在本地,不泄露隐私也不违反法规
- 多个参与者联合数据建立虚拟的公有模型,并且共同获益的体系
- 在联邦学习的体系下,各个参与者的身份和地位平等
- 联邦学习的建模效果和将整个数据放在一处建模的效果相同,或相差不大(在各个数据的用户对齐(
user alignment)或特征对齐(feature alignment)的条件下) - 迁移学习是在用户或特征不对齐的情况下,也可以在数据间通过交换加密参数达到知识迁移的效果
联邦学习使多个参与方在保护数据隐私、满足合法合规要求的前提下继续进行机器学习,解决数据孤岛问题。
第二章:定义及价值
2.1 概述
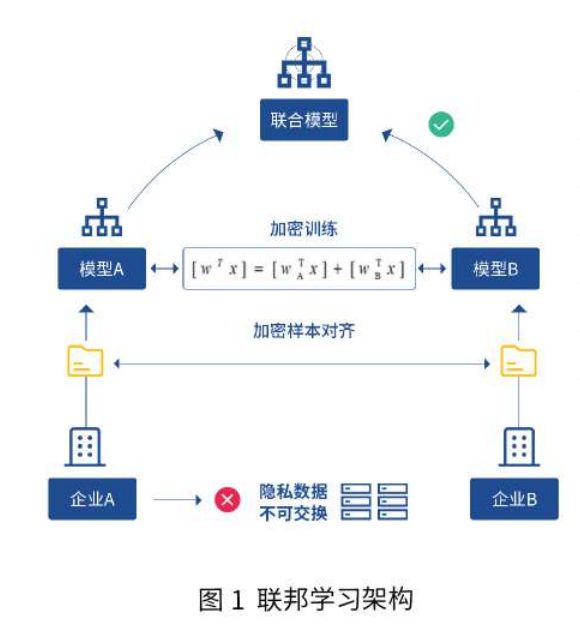
什么是联邦学习呢?举例来说,假设有两个不同的企业A和B,它们拥有不同的数据.比如,企业A有用户特征数据;企业 B 有产品特征数据和标注数据.这两个企业按照上述 GDPR 准则是不能粗暴地把双方数据加以合并的,因为数据的原始提供者,即他们各自的用户并没有机会来同意这样做.假设双方各自建立一个任务模型,每个任务可以是分类或预测,而这些任务也已经在获得数据时有各自用户的认可.那现在的问题是如何在A和B 各端建立高质量的模型.但是,由于数据不完整(例如企业A缺少标签数据,企业 B 缺少特征数据),或者数据不充分(数据量不足以建立好的模型),那么,在各端的模型有可能无法建立或效果并不理想.
联邦学习是要解决这个问题:它希望做到各个企业的自有数据不出本地,而联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型.这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样.但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规.这样,建好的模型在各自的区域仅为本地的目标服务.在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了"共同富裕”的策略。这就是为什么这个体系叫做"联邦学习”。
2.2 定义
在进行机器学习的过程中,各参与方可借助其他方数据进行联合建模.各方无需共享数据资源,即数据不出本地的情况下,进行数据联合训练,建立共享的机器学习模型.
约束条件:
|V_FED-V_SUM|<δ
式中:
V_FED——联邦学习模型效果
V_SUM ——传统方法模型效果
δ ——有界正数
2.3 公共价值
联邦学习作为未来 Al发展的底层技术,它依靠安全可信的数据保护措施下连接数据孤岛的模式,将不断推动全球 Al 技术的创新与飞跃。随着联邦学习在更大范围和更多行业场景的渗透及应用,它在更高层面上对各类人群、组织、行业和社会都将产生巨大影响,联邦学习的公共价值主要体现在以下几个方面∶
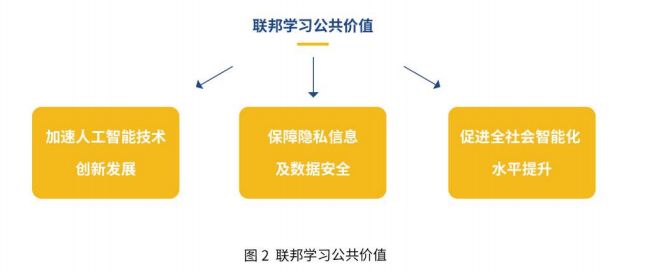
- 加速人工智能技术创新发展
人工智能技术当前已形成汇聚了全球技术、资金、人才和影响力等多元资源的产业生态,而作为 Al 建模底层不可或缺的核心技术,联邦学习将真正助力大数据实现价值,在数据不出本地的环境下带动 Al 各领域在各行业的深度融合,使得人工智能技术能够扫清数据障碍,不断迭代成长和创新。 - 保障隐私信息及数据安全
联邦学习可做到个体的自有数据不出本地,联邦系统通过加密机制下的参数交换方式,在不违反数据隐私保护法规的情况下,建立一个虚拟的共有模型。建立虚拟模型时,数据本身不移动,也不会泄露用户隐私或影响数据规范,充分保障了个体隐私信息及数据安全。 - 促进全社会智能化水平提升
基于联邦学习的 Al 技术将更安全地融入社会基础设施和生活中,它不仅能辅助人类的工作及生活,也逐步改变人类的认知模式,从而推动社会经济及发展。
2.4 商业价值
联邦学习技术是一种“合作共赢”的模式,对商业利益而言极具价值。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。这就是为什么这个体系叫做“联邦学习”。从商业角度而言,联邦学习的主要价值有∶
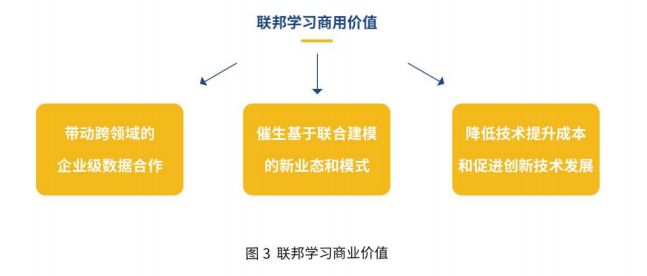
- 带动跨领域的企业级数据合作,智能策略辅助市场布局及竞争力提升
联邦学习作为Al发展的底层技术,能够帮助到企业参与到新的全球化、泛行业化的协作网络和联邦生态中,通过跨领域的企业界数据合作,更有效地训练模型辅助自身市场布局、策略优化,从而提升竞争力。联邦学习能在技术层面帮助企业更好地确立自身合作与竞争策略,以此形成联邦中的独有生态,从而更好推动企业良性发展。 - 催生基于联合建模的新业态和模式
通过联邦生态及联邦学习在其他领域的应用拓展,将不断影响和改变合作中提供方、需求方的关系,重定义各方合作者的身份、服务方式和盈利方式,催生出基于联合建模的全新业态及模式。 - 降低技术提升成本和促进创新技术发展
联邦学习技术成体系可复用的解决方案能够有效降低技术应用的门槛,扩大技术应用的范围和广度,这使得广大泛Al行业企业机构能够为不同客户提供更加丰富的产品及服务,同时去除数据安全隐忧的Al大环境将有助于创新型技术的进一步飞跃,在提升效率和获得成长的同时,实现自身发展。
2.5 联邦学习与现有研究的关系
作为一种全新的技术,联邦学习在借鉴一些成熟技术的同时也具备了一定的独创性。下面我们就从多个角度来阐释联邦学习和其他相关概念之间的关系。
-
联邦学习与差分隐私理论的区别
联邦学习的特点使其可以被用来保护用户数据的隐私,但是它和大数据、数据挖掘领域中常用的隐私保护理论如差分隐私保护理论(Differential Privacy)、k 匿名(k-Anonymity)和Ι 多样化(I-Diversity)等方法还是有较大的差别的。首先联邦学习与传统隐私保护方法的原理不同,联邦学习通过加密机制下的参数交换方式保护用户数据隐私,加密手段包括同态加密等。与Differential Privacy不同,其数据和模型本身不会进行传输,因此在数据层面上不存在泄露的可能,也不违反更严格的数据保护法案如GDPR等。而差分隐私理论、k 匿名和I多样化等方法是通过在数据里加噪音,或者采用概括化的方法模糊某些敏感属性,直到第三方不能区分个体为止,从而以较高的概率使数据无法被还原,以此来保护用户隐私。但是,从本质上来说这些方法还是进行了原始数据的传输,存在着潜在被攻击的可能性,并且在GDPR等更严格的数据保护法案下这种数据隐私的保护方式可能不再适用。与之对应的,联邦学习是对用户数据隐私保护更为有力的手段。 -
联邦学习与分布式机器学习的区别
横向联邦学习中多方联合训练的方式与分布式机器学习(Distributed Machine Learning)有部分相似的地方。分布式机器学习涵盖了多个方面,包括把机器学习中的训练数据分布式存储、计算任务分布式运行、模型结果分布式发布等,参数服务器(Parameter Server) IP)是分布式机器学习中一个典型的例子。参数服务器作为加速机器学习模型训练过程的一种工具,它将数据存储在分布式的工作节点上,通过一个中心式的调度节点调配数据分布和分配计算资源,以便更高效的获得最终的训练模型。而对于联邦学习而言,首先在于横向联邦学习中的工作节点代表的是模型训练的数据拥有方,其对本地的数据具有完全的自治权限,可以自主决定何时加入联邦学习进行建模,相对地在参数服务器中,中心节点始终占据着主导地位,因此联邦学习面对的是一个更复杂的学习环境;其次,联邦学习则强调模型训练过程中对数据拥有方的数据隐私保护,是一种应对数据隐私保护的有效措施,能够更好地应对未来愈加严格的数据隐私和数据安全监管环境。 -
联邦学习与联邦数据库的关系
联邦数据库系统(Federated Database System)是将多个不同的单元数据库进行集成,并对集成后的整体进行管理的系统。它的提出是为了实现对多个独立的数据库进行相互操作。联邦数据库系统对单元数据库往往采用分布式存储的方式,并且在实际中各个单元数据库中的数据是异构的,因此,它和联邦学习在数据的类型与存储方式上有很多相似之处。但是,联邦数据库系统在各个单元数据库交互的过程中不涉及任何隐私保护机制,所有单元数据库对管理系统都是完全可见的。此外,联邦数据库系统的工作重心在包括插入、删除、查找、合并等各种数据库基本操作上面,而联邦学习的目的是在保护数据隐私的前提下对各个数据建立一个联合模型,使数据中蕴含的各种模式与规律更好地为我们服务。 -
联邦学习与区块链的关系
区块链是一个基于密码学安全的分布式账本,其方便验证,不可篡改。区块链 2.0是一个去中心化的应用,通过使用开源的代码及分布式的存储和运行,保证极高的透明度和安全性,使数据不会被篡改。区块链的典型应用包括比特币(BTC)、以太坊(ETH)等。区块链与联邦学习都是一种去中心化的网络,区块链是一种完全P2P (peer to peer)的网络结构,在联邦学习中,第三方会承担汇聚模型、管理等功能。联邦学习与区块链中,均涉及到密码学、加密算法等基础技术。根据技术的不同,区块链技术使用的加密算法包括哈希算法,非对称加密等;联邦学习中使用同态加密等。从数据角度上看,区块链上通过加密的方式在各个节点上记录了完整的数据,而联邦学习中,各方的数据均仅保留在本地。从奖励机制上看,区块链中,不同节点之间通过竞争记账来获得奖励;在联邦学习中,多个参与方通过共同学习,提高模型训练结果,依据每一方的贡献来分配奖励。 -
联邦学习与多方安全计算的关系
在联邦学习中,用户的隐私与安全是重中之重。为了保护用户隐私,防止联邦学习应用被恶意方攻击,多方安全计算技术可以在联邦学习中被应用,成为联邦学习技术框架中的一部分。学术界已经展开利用多方安全计算来增强联邦学习的安全性的研究。McMahan指出,联邦学习可以通过差分隐私,多方安全计算,或它们的结合等技术来提供更强的安全保障。Bonawitz指出,联邦学习中,可以利用多方安全计算以安全的方式计算来自用户设备的模型参数更新的总和。Truex中提出了一种利用差分隐私和多方安全计算来保护隐私的联邦学习方法。Liu提出将加性同态加密(AHE)应用于神经网络的多方计算。微众银行提出的开源联邦学习框架FATE中包含了多方安全计算的相关算子,方便应用方对多方安全计算进行高效的开发。