OpenCV学习笔记(十六)——支持向量机(SVM)
支持向量机(Support Vector Machine,SVM)是一种二分类模型,目标是寻找一个标准(称为超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大)。当数据集较小时,使用支持向量机进行分类非常有效。支持向量机是最好的现成分类器之一,这里所谓的“现成”是指分类器不加修改即可直接使用。
OpenCV学习笔记(十六)
-
-
- 1. 理论基础
-
- 1.1 分类
- 1.2 分类器
- 1.3 将不可分变为可分
- 1.4 概念总结
- 2. 案例介绍
-
1. 理论基础
下面只是简单介绍一下SVM,具体关于SVM的原理可以参考这篇文章:机器学习算法(一)SVM
1.1 分类
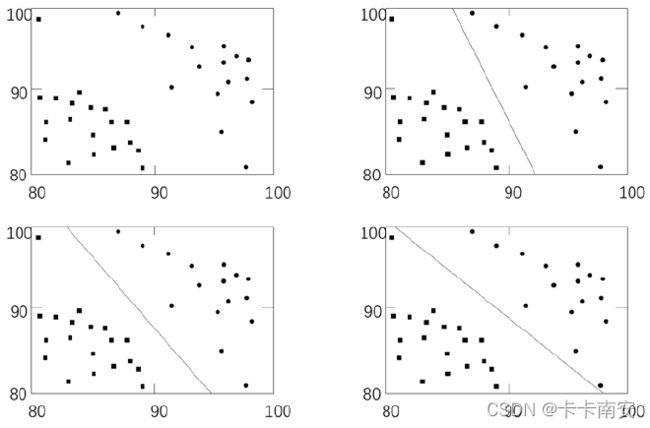
某 IT 企业在2017 年通过笔试、面试的形式招聘了一批员工。2018 年,企业针对这批员工在过去一年的实际表现进行了测评,将他们的实际表现分别确定为A 级(优秀)和B 级(良好)。这批员工的笔试成绩、面试成绩和等级如图21-1 所示,图中横坐标是笔试成绩,纵坐标是面试成绩,位于右上角的圆点表示测评成绩是A 级,位于左下角的小方块表示测评成绩是B级。

当然,公司肯定希望招聘到的员工都是A 类(表现为A 级)的。关键是如何根据笔试和面试成绩确定哪些员工可能是未来的A 类员工呢?或者说,如何根据笔试和面试成绩确保招聘的员工是潜在的优秀员工?偷懒的做法是将笔试和面试的成绩标准都定得较高,但这样做可能会漏掉某些优秀的员工。所以,要合理地确定笔试和面试的成绩标准,确保能够准确高效地招到A 类员工。例如,在图中,分别使用直线对笔试和面试成绩进行了3 种不同形式的划分,将成绩位于直线左下方的员工划分为B 类,将成绩位于右上方的员工划分为A 类。
1.2 分类器
在上图中用于划分不同类别的直线,就是分类器。在构造分类器时,非常重要的一项工作就是找到最优分类器。
那么,上图中的三个分类器,哪一个更好呢?从直观上,我们可以发现图中右上角的分类器和右下角的分类器都偏向了某一个分类(即与其中一个分类的间距更小),而左下角的分类器实现了“均分”。而左下角的分类器,尽量让两个分类离自己一样远,这样就为每个分类都预留了等量的扩展空间,即使有新的靠近边界的点进来,也能够按照位置划分到对应的分类内。
以上述划分为例,说明如何找到支持向量机:在已有数据中,找到离分类器最近的点,确保它们离分类器尽可能地远。
这里,离分类器最近的点到分类器的距离称为间隔(margin)。我们希望间隔尽可能地大,这样分类器在处理数据时,就会更准确。例如,在图中,左下角分类器的间隔最大。

离分类器最近的那些点叫作支持向量(support vector)。正是这些支持向量,决定了分类器所在的位置。
1.3 将不可分变为可分
支持向量机在处理数据时,如果在低维空间内无法完成分类,就会自动将数据映射到高维空间,使其变为(线性)可分的。简单地讲,就是对当前数据进行函数映射操作。
如图 所示,在分类时,通过函数f 的映射,让左图中本来不能用线性分类器分类的数据变为右图中线性可分的数据。当然,在实际操作中,也可能将数据由低维空间向高维空间转换。
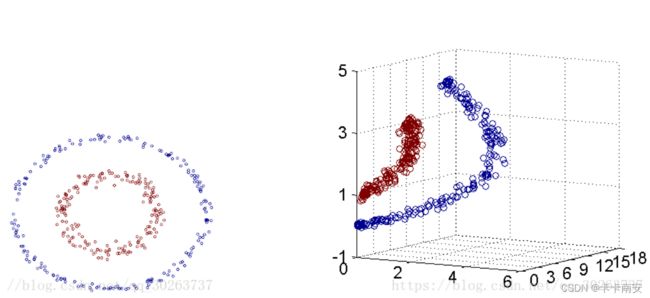
大家也许会担心,数据由低维空间转换到高维空间后运算量会呈几何级增加,但实际上,支持向量机能够通过核函数有效地降低计算复杂度。

1.4 概念总结
尽管上面分析的是二维数据,但实际上支持向量机可以处理任何维度的数据。在不同的维度下,支持向量机都会尽可能寻找类似于二维空间中的直线的线性分类器。例如,在二维空间,支持向量机会寻找一条能够划分当前数据的直线;在三维空间,支持向量机会寻找一个能够划分当前数据的平面(plane);在更高维的空间,支持向量机会尝试寻找一个能够划分当前数据的超平面(hyperplane)。
一般情况下,把能够可以被一条直线(更一般的情况,即一个超平面)分割的数据称为线性可分的数据,所以超平面是线性分类器。
“支持向量机”是由“支持向量”和“机器”构成的。
- “支持向量”是离分类器最近的那些点,这些点位于最大“间隔”上。通常情况下,分类仅依靠这些点完成,而与其他点无关。
- “机器”指的是分类器。
综上所述,支持向量机是一种基于关键点的分类算法。
2. 案例介绍
在使用支持向量机模块时,需要先使用函数cv2.ml.SVM_create()生成用于后续训练的空分类器模型。该函数的语法格式为:
svm = cv2.ml.SVM_create( )
获取了空分类器svm 后,针对该模型使用svm.train()函数对训练数据进行训练,其语法格式为:
训练结果= svm.train(训练数据,训练数据排列格式,训练数据的标签)
- 训练数据:表示原始数据,用来训练分类器。例如,前面讲的招聘的例子中,员工的笔试成绩、面试成绩都是原始的训练数据,可以用来训练支持向量机。
- 训练数据排列格式:原始数据的排列形式有按行排列(cv2.ml.ROW_SAMPLE,每一条训练数据占一行)和按列排列(cv2.ml.COL_SAMPLE,每一条训练数据占一列)两种形式,根据数据的实际排列情况选择对应的参数即可。
- 训练数据的标签:原始数据的标签。
- 训练结果:训练结果的返回值。
例如,用于训练的数据为data,其对应的标签为label,每一条数据按行排列,对分类器模型svm 进行训练,所使用的语句为:
返回值 = svm.train(data,cv2.ml.ROW_SAMPLE,label)
完成对分类器的训练后,使用svm.predict()函数即可使用训练好的分类器模型对测试数据进行分类,其语法格式为:
(返回值,返回结果) = svm.predict(测试数据)
以上是支持向量机模块的基本使用方法。在实际使用中,可能会根据需要对其中的参数进行调整。OpenCV 支持对多个参数的自定义,例如:可以通过setType()函数设置类别,通过setKernel()函数设置核类型,通过setC()函数设置支持向量机的参数C(惩罚系数,即对误差的宽容度,默认值为0)。
下面通过一个具体案例介绍如何在Python 中调用OpenCV 的支持向量机模块进行分类操作。
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
#第1步 准备数据
# A等级的笔试、面试分数
a = np.random.randint(95,100, (20, 2)).astype(np.float32)
# B等级的笔试、面试分数
b = np.random.randint(90,95, (20, 2)).astype(np.float32)
#合并数据
data = np.vstack((a,b))
data = np.array(data,dtype='float32')
#第2步 建立分组标签,0代表A等级,1代表B等级
#aLabel对应着a的标签,为类型0-等级A
aLabel=np.zeros((20,1))
#bLabel对应着b的标签,为类型1-等级B
bLabel=np.ones((20,1))
#合并标签
label = np.vstack((aLabel, bLabel))
label = np.array(label,dtype='int32')
#第3步 训练
# ml 机器学习模块 SVM_create() 创建
svm = cv2.ml.SVM_create()
# 属性设置,直接采用默认值即可。
#svm.setType(cv2.ml.SVM_C_SVC) # svm type
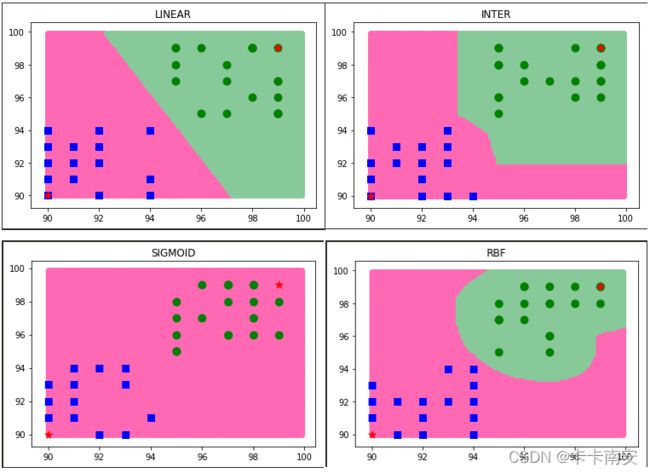
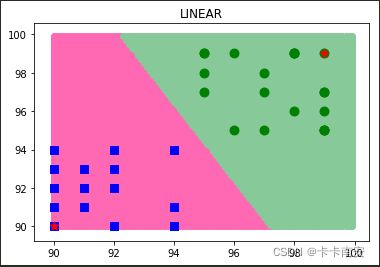
kernels = [cv2.ml.SVM_LINEAR, cv2.ml.SVM_INTER, cv2.ml.SVM_SIGMOID, cv2.ml.SVM_RBF]
svm.setKernel(kernels[0]) # line
#svm.setC(0.01)
# 训练
result = svm.train(data,cv2.ml.ROW_SAMPLE,label)
#第4步 预测
#生成两个随机的(笔试成绩、面试成绩),可以用随机数生成
test = np.vstack([[99,99],[90,90]]) #0-A级 1-B级
test = np.array(test,dtype='float32')
#预测
(p1,p2) = svm.predict(test)
#第5步 观察结果
#可视化
x = np.arange(90,100,0.1)
y = np.arange(90,100,0.1)
class1_x=[]
class1_y=[]
class2_x=[]
class2_y=[]
for i in range(len(x)):
for j in range(len(y)):
m = np.array([[x[i],y[j]]],dtype='float32')
result = svm.predict(m)[1][0,0]
if result == 1:
class1_x.append(x[i])
class1_y.append(y[j])
else:
class2_x.append(x[i])
class2_y.append(y[j])
plt.scatter(np.asarray(class1_x),np.asarray(class1_y),color = 'hotpink')
plt.scatter(np.asarray(class2_x),np.asarray(class2_y),color = '#88c999')
plt.scatter(a[:,0], a[:,1], 80, 'g', 'o')
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
plt.show()
#打印原始测试数据test,预测结果
print(test)
print(p2)
运行后输出以下结果:
[[99. 99.]
[90. 90.]]
[[0.]
[1.]]
使用不同的核函数得到的结果如下所示: