Lsm树学习笔记
一、前言
lsm树(log-Structured-Merge-Tree 日志结构合并树)被用作HBase、LevelDB、RocksDB的底层数据结构。是Google的BigTable论文中提到的一种文件组织数据结构。现在比较火的newsql数据库像tidb就是基于rocksdb。
本篇记录一下学习lsm的一些笔记,主要包含lsm树在存储和索引上的一些特性,与常见索引结构的比较,不包含并发控,事务处理和错误处理。
二、日志结构数据库
1、考虑通过两个bash函数实现一个简单的键值数据库mydb,
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
2、db_set会将key和value存储在数据库中,db_get会将key对应的值返回。
[root@VM-0-11-centos tmp]# db_set key001 value0001
[root@VM-0-11-centos tmp]# db_set key002 value0002
[root@VM-0-11-centos tmp]# db_set key999 value999
[root@VM-0-11-centos tmp]#
[root@VM-0-11-centos tmp]# db_get key999
value999
[root@VM-0-11-centos tmp]#
3、底层的存储很简单为一个文本文件,每行包含一条逗号分隔的键值对。
- db_set函数往文件末尾追加记录,旧值不会被覆盖。
- db_get函数通过grep查找文件中最后一次出现的位置。
dbset在一些场景拥有非常好的性能,许多数据库内部的 日志(log) 就是 仅追加(append-only) 的方式写入。mydb可以简单理解成:日志结构(log-structured) 的存储引擎类型。
[root@VM-0-11-centos tmp]# cat database
key001,value0001
key002,value0002
key999,value999
4、这个数据库有什么问题,当数据增长到一定数量,db_get查询函数的性能会非常糟糕,因为需要从头到尾扫描整个文件,也就是时间复杂度是0(N)。
为了高效查找,我们需要引入一种数据结构索引(index)。索引是一种额外的结构帮助我们更快的检索到我们需要的记录。但是维护索引需要产生额外的开销。
三、哈希索引
2.1 构建索引
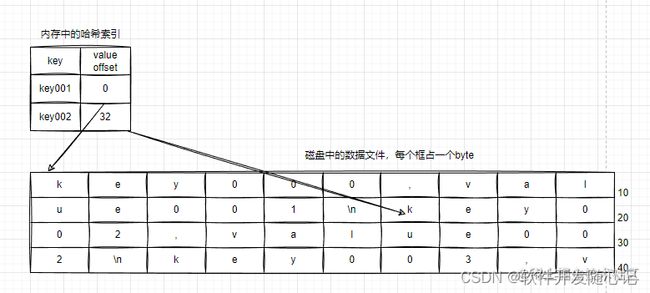
如果要为上面的键值数据库构建索引,哈希索引是一个明显不错的选择。在大多数编程语言中都可以找到散列映射(hash map) 如Java中的HashMap。所以我们现在用内存中的数据结构哈希映射来为mydb构建索引。
索引策略是:保留一个内存中的哈希结构,其中key是mydb的key,value是记录在database文件中的偏移位置offset。
- 1、当新记录插入时,同时更新内存中的索引。
- 2、当通过key查找记录时,先通过索引哈希映射检索到记录在文件中的位置,然后通过偏移量访问文件。
- 3、删除记录通过插入逻辑删除记录。
2.2 日志压缩
还是以mydb为例子,当对同一个文件一直写入会出现最终用完磁盘空间,我们可以把日志文件分成特定大小的段(Segment)。
- 当日志文件增长到特定大小的时候,关闭文件,同时开启新文件的写入。
- 对已经关闭的段文件进行压缩合并,有多个版本的记录保留最新的版本。合并的段写入一个新的文件。
- 段被写入后是不可修改的 (Immutable),冻结和压缩操作可以在后台线程进行。
- 由于合并是写入新文件,压缩过程中,旧文件还是可以提供服务,压缩完成后将读取请求转成新段,然后简单的删除旧文件。
- 日志合并过程中,放弃合并删除键之前的任何值。

现在每个段文件都会拥有自己哈希索引,将键映射到文件偏移量。现在db_get操作需要先查找最近段的值,如果没有,检查第二新的段,以此类推。
2.3 局限
- 哈希表必须要能装入内存。
- 范围查找效率不高。
四、LSM树和SSTable
到现在,mydb的日志文件段是一系列的键值对,这些键值对按照写入的顺序存储,日志中后面的值优先于前面的值。文件中的键值对本身没有顺序。
如果对要求日志段的键值对是有顺序的,就得到了lsm树主要的概念 排序字符串表(Sorted String Table)
,SSTable还要求每个键在同一个段文件只出现一次。
3.1 SSTable的合并
- 由于不同的段文件都是有序的,通过有序链表的多路归并可以合并得到新文件,并且遍历都是顺序读取文件。
- 当不同的段中存在相同的key时,取最近的一个段文件值,其余所有段文件的相同key都可以丢弃。一个输入段中的所有值必须比另一个段中的所有值更新
3.2 SSTable的索引
- 不用再为了查找而保存所有key的索引。假如我正在内存中查找key100的值,我不用知道key100在文件中的具体偏移,我只用知道key001的偏移和key500的偏移,由于排序的特性,我只用跳到key001的文件位置去扫描到key500。直到我找到key100或者key100不存在。
- 只需要一个内存中的稀疏索引就可以满足检索要求,比如每隔几千字节就添加一个键到内存索引中。
- 请求无论如果都要扫描请求范围内的多个键值对,可以对多一个文件段中的记录分组到块(block) 中,并且在写入磁盘时进行压缩。
3.3 如何得到SSTable
- 写入时先写入内存中的平衡数据结构(红黑树,跳表),这个内存结构被称作内存表(memtable) 。
- 当内存表达到一个阈值时,将其作为SSTable文件(ImmuableTable)写入磁盘,此时文件已经是有序的了。然后继续维护新的内存实例。
- 在在后台运行合并和压缩过程以组合段文件并丢弃覆盖或删除的值。

3.4 SSTable查询
先查内存表,再查最近的磁盘文件段,以此类推。
3.5 SStable构建lsm树
基于这种合并和压缩排序文件原理的存储引擎通常被称为LSM存储引擎。其实就是memtable + SSTable + 日志合并操作得到的一个逻辑视图。
3.6 lsm树优化
- 当查找数据库中不存在的key时,lsm树可能会很慢,因为需要遍历每一个SSTable文件。因此可以使用Bloom过滤器在SSTable上快速判断key是否存在。BigTable也是这么做的。
- 不同的策略来确定SSTables如何被压缩和合并的顺序和时间。最常见的选择是大小分层压实。 LevelDB和RocksDB使用平坦压缩(LevelDB因此得名),HBase使用大小分层,Cassandra同时支持。
- 写放大优化,例如tree1是tree0的10倍,如果写入tree1触发了tree1,tree0合并,则带来了10倍的写放大。这种一般从合并策略方面去优化。大value也容易导致每一层能存储的key变少,从而更容易触发合并,k、v分离可以起到优化效果。
五、比较B树和Lsm树
补充概念
- b树面向页面(page-oriented) 的存储引擎
- 在数据库的生命周期中写入数据库导致对磁盘的多次写入 —— 被称为写放大(write amplification) 。需要特别注意的是固态硬盘,固态硬盘的闪存寿命在覆写有限次数后就会耗尽。
| B树 | Lsm树 |
|---|---|
| B树索引需要两次写入,预写日志和树页面本身 | - |
| 由于采取就地更新策略,写入操作可能涉及多个页面更新 | 较低的写放大,顺序写入,SSTable更紧凑 |
| 页面被分割或者拆分时候,会有空间浪费 | 压缩比b树更好,更多的小文件,较低的存储开销 |
| 读写行为相对有可预测性 | 压缩过程会干扰读写操作, |
| 由于磁盘io总量固定,随着文件越来越大,压缩操作可能会占据越来越多的磁盘io。如果写入吞吐很高,写入会跟不上压缩速度,需要监控。 | |
| 每个键在索引上只有一个,对于事务支持比较合适 | 由于一个键在多个文件存在,所以在行键加锁实现事务比较困难 |
六、参考
1、设计数据密集型应用
2、大数据经典论文解读
笔者水平有限,不当之处大家拍砖
robben.hu