Deformable Convolution Networks 代码思路及解析
最近在看一篇CV任务中的Attention机制综述时,觉得其中一篇于2017年发表在CVPR上的Deformable ConvNets很有意思,觉得文章中思路及公式都是清晰明了,在Github上找了份PyTorch代码时,嗯……发现事情并不简单。终于在拜读大佬的deformable convolution可变形卷积(4uiiurz1-pytorch版)源码分析和一篇文章为你讲透双线性插值后,清楚了一二。这里按照自己理解学习的思路写下作为这篇论文的学习总结。

plain convolution operation:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ∗ x ( p 0 + p n ) y(p_{0}) = \sum_{p_{n \in R}}{w(p_{n})*x(p_{0}+p_{n})} y(p0)=∑pn∈Rw(pn)∗x(p0+pn)
deformable convolution operation:
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ∗ x ( p 0 + p n + Δ p n ) y(p_{0}) = \sum_{p_{n \in R}}{w(p_{n})*x(p_{0}+p_{n}+ \Delta p_{n})} y(p0)=∑pn∈Rw(pn)∗x(p0+pn+Δpn)
一:背景
作者认为由于普通卷积中感受野是规则且固定的,这导致模型的几何变换建模能力受限。因此,作者提出可变形卷积模块。在卷积核对应的位置上都添加上可学习的偏移量参数,使得在可变性卷积的感受野不再固定。
二:做法
论文中交代,在CNN中的卷积和特征图都是3D的。可变形卷积模块是在2D的空间域上进行操作,在各通道维度上保持一致。
三:代码思路
y ( p 0 ) = ∑ p n ∈ R w ( p n ) ∗ x ( p 0 + p n + Δ p n ) y(p_{0}) = \sum_{p_{n \in R}}{w(p_{n})*x(p_{0}+p_{n}+ \Delta p_{n})} y(p0)=∑pn∈Rw(pn)∗x(p0+pn+Δpn)
如公式所示,重要的是表示出带有偏置量 x ( p 0 + p n + Δ p n ) x(p_{0}+p_{n}+ \Delta p_{n}) x(p0+pn+Δpn)的特征值。其中, p 0 p_{0} p0代表卷积的中心点坐标, p n p_{n} pn表示邻域位置{(-1,-1),(-1,0),(-1,1),(0,-1)……}, Δ p n \Delta p_{n} Δpn表示偏置量,下文将用 o f f s e t s offsets offsets来代替 Δ p n \Delta p_n Δpn。
1. p 0 + p n + o f f s e t s p_0+p_n+offsets p0+pn+offsets表示包含了坐标偏置量的卷积操作的坐标。

1.1.根据 k e r n e l _ s i z e kernel\_size kernel_size和 s t r i d e stride stride,可以表示出卷积操作的卷积核中心坐标 ( x n , y n ) (x_n, y_n) (xn,yn)。若输出特征图 ( b , c , h , w ) (b, c, h, w) (b,c,h,w),则输入特征图中有 h ∗ w h*w h∗w个卷积核中心 p 0 p_0 p0。
1.2.再根据式中的 p n = { ( − 1 , − 1 ) , ( − 1 , 0 ) , ( − 1 , 1 ) … … } p_{n}=\{(-1,-1),(-1,0),(-1,1)……\} pn={(−1,−1),(−1,0),(−1,1)……},依次表示出每个卷积核的邻域坐标 p n p_n pn。【注意】输出特征图中每个点在2D空间域上,每个点有 x {x} x方向和 y {y} y方向上各一个可学习的偏移量参数,故每个位置上都有2个可学习参数 o f f s e t s offsets offsets。
2. p 0 + p n + o f f s e t s p_0+p_n+offsets p0+pn+offsets中的 o f f s e t s offsets offsets是网络中学习到的参数,是浮点型数,不能直接得到 x ( p 0 + p n + o f f s e t s ) x_(p_0+p_n+offsets) x(p0+pn+offsets)的特征值。而特征图像素间最小间隔是1。所以,文中根据 ( p 0 + p n + o f f s e t s ) (p_0+p_n+offsets) (p0+pn+offsets)坐标所落在的像素所围绕的4个点的坐标及特征值,通过双线性插值方式来计算当前坐标 x ( p 0 + p n + o f f s e t s ) x_(p_0+p_n+offsets) x(p0+pn+offsets)的特征值。
2.1. ( p 0 + p n + o f f s e t s ) . f l o o r ( ) (p_0+p_n+offsets).floor() (p0+pn+offsets).floor()得到左上角坐标, ( p 0 + p n + o f f s e t s ) . f l o o r ( ) + 1 (p_0+p_n+offsets).floor()+1 (p0+pn+offsets).floor()+1得到右下角坐标;再依次计算出左下角及右上角坐标。注意: ( p 0 + p n + o f f s e t s ) (p_0+p_n+offsets) (p0+pn+offsets)在 x x x方向不能超过特征图的 h e i g h t height height, 在 y y y方向不能超过特征图的 w i d t h width width。
2.2. 双线性插值是分别在两个方向计算了共3次单线性插值。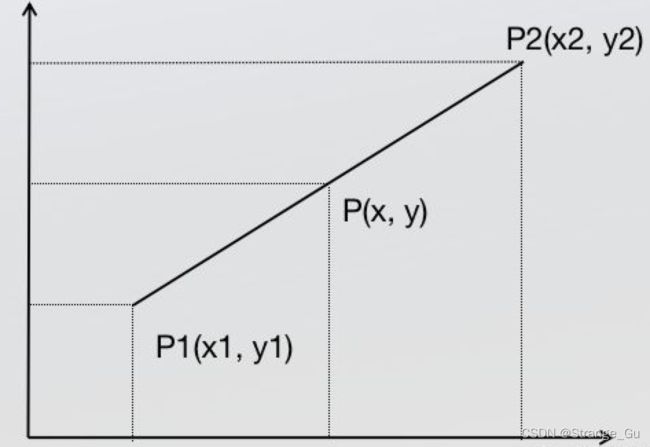
单线性插值:
y = x 2 − x x 2 − x 1 × y 1 + x − x 1 x 2 − x 1 × y 2 y = \frac{x_2-x}{x2-x_1} \times y_1 + \frac{x-x_1}{x_2-x_1} \times y_2 y=x2−x1x2−x×y1+x2−x1x−x1×y2
我们是要求图像上的特征值,假设 y 1 y_1 y1和 y 2 y_2 y2分别代表图像中的特征值,上面的公式就可以写成下式:(分子项呈现一个线性关系,可以理解成距离 p 1 p_1 p1近,则分子要大。)
f ( p ) = x 2 − x x 2 − x 1 × f ( p 1 ) + x − x 1 x 2 − x 1 × f ( p 1 ) f(p) = \frac{x_2-x}{x_2-x_1} \times f(p_1) + \frac{x-x_1}{x_2-x_1} \times f(p_1) f(p)=x2−x1x2−x×f(p1)+x2−x1x−x1×f(p1)
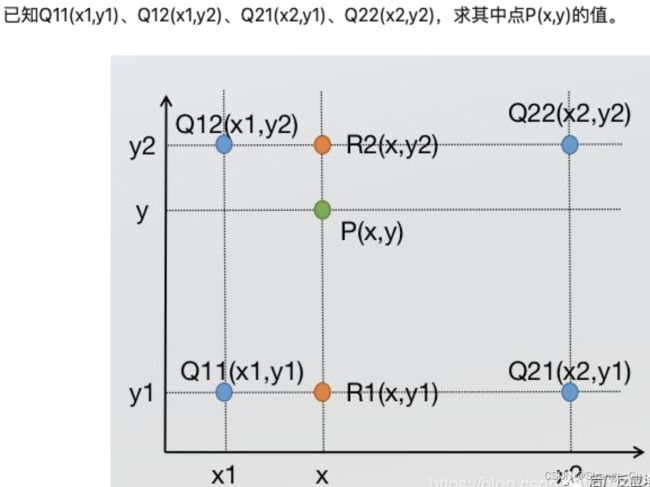
2.2.1. x x x方向上进行2次单线性插值:
f ( R 1 ) = x 2 − x x 2 − x 1 × f ( Q 11 ) + x − x 1 x 2 − x 1 × f ( Q 21 ) f(R_1) = \frac{x_2-x}{x_2-x_1}\times f(Q_{11}) + \frac{x-x_1}{x_2-x_1}\times f(Q_{21}) f(R1)=x2−x1x2−x×f(Q11)+x2−x1x−x1×f(Q21)
f ( R 2 ) = x 2 − x x 2 − x 1 × f ( Q 12 ) + x − x 1 x 2 − x 1 × f ( Q 22 ) f(R_2) = \frac{x_2-x}{x_2-x_1}\times f(Q_{12}) + \frac{x-x_1}{x_2-x_1}\times f(Q_{22}) f(R2)=x2−x1x2−x×f(Q12)+x2−x1x−x1×f(Q22)
2.2.2. y y y方向上进行1次单线性插值:
f ( p ) = y 2 − y y 2 − y 1 × f ( R 1 ) + y − y 1 y 2 − y 1 × f ( R 2 ) f(p) = \frac{y_2-y}{y_2-y_1}\times f(R_1) + \frac{y-y_1}{y_2-y_1}\times f(R_2) f(p)=y2−y1y2−y×f(R1)+y2−y1y−y1×f(R2)
2.2.3.将上面公式进行代入化简,且在图像特征中 x 2 − x 1 = 1 x_2-x_1=1 x2−x1=1和 y 2 − y 1 = 1 y_2-y_1=1 y2−y1=1,故可得最终公式如下:
f ( p ) = ( x 2 − x ) ( y 2 − y ) × f ( Q 11 ) + ( y 2 − y ) ( x − x 1 ) × f ( Q 12 ) + ( y 2 − y ) ( x − x 1 ) × f ( Q 21 ) + ( y − y 1 ) ( x 2 − x 1 ) × f ( Q 22 ) f(p) = (x_2-x)(y_2-y)\times f(Q_{11}) + (y_2-y)(x-x_1)\times f(Q_{12}) + (y_2-y)(x-x_1)\times f(Q_{21}) + (y-y_1)(x_2-x_1)\times f(Q_{22}) f(p)=(x2−x)(y2−y)×f(Q11)+(y2−y)(x−x1)×f(Q12)+(y2−y)(x−x1)×f(Q21)+(y−y1)(x2−x1)×f(Q22)
3. 现在 ( x 1 , y 1 ) , ( x 1 , y 2 ) , ( x 2 , y 1 ) , ( x 2 , y 2 ) (x_1, y_1), (x_1, y_2), (x_2, y_1), (x_2, y_2) (x1,y1),(x1,y2),(x2,y1),(x2,y2)四个坐标已知,接下来需要求出 f ( Q 11 ) , f ( Q 12 ) , f ( Q 21 ) , f ( Q 22 ) f(Q_{11}), f(Q_{12}), f(Q_{21}), f(Q_{22}) f(Q11),f(Q12),f(Q21),f(Q22)的特征值。
3.1 f ( Q 11 ) , f ( Q 12 ) , f ( Q 21 ) , f ( Q 22 ) f(Q_{11}), f(Q_{12}), f(Q_{21}), f(Q_{22}) f(Q11),f(Q12),f(Q21),f(Q22)需要根据特征图 x x x求出对应的特征值。
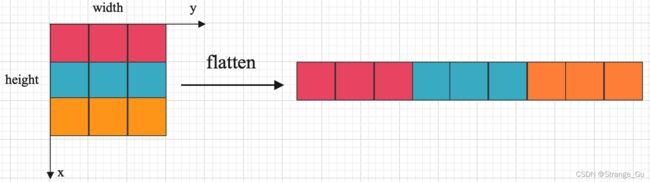
3.1.1. 特征图 x x x中的各个坐标展开1D时:
C o o r d i n a t e = C o o r d i n a t e x × w i d t h + C o o r d i n a t e y Coordinate = Coordinate_x \times width + Coordinate_y Coordinate=Coordinatex×width+Coordinatey
3.1.2. 将坐标依次带入上式中,得到对应展成1D形式的坐标。将1D形式的坐标对应特征图 x x x对应的特征值取出 f ( Q 11 ) , f ( Q 12 ) , f ( Q 21 ) , f ( Q 22 ) f(Q_{11}), f(Q_{12}), f(Q_{21}), f(Q_{22}) f(Q11),f(Q12),f(Q21),f(Q22),最后带入步骤2.2.3.中就可以算出带有偏移量的坐标所对应的特征值。
以上就是代码的实现思路。
四. 代码部分
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
moduleation(bool, optional): If True, Modulated Defromable Convolution(Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
# self.p_conv偏置层,学习公式(2)中的偏移量。
# 2*kernel_size*kernel_size:代表了卷积核中所有元素的偏移坐标,因为同时存在x和y的偏移,故要乘以2。
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
# register_backward_hook是为了方便查看这几层学出来的结果,对网络结构无影响。
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
# self.m_conv权重学习层,是后来提出的第二个版本的卷积也就是公式(3)描述的卷积。
# kernel_size*kernel_size:代表了卷积核中每个元素的权重。
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
# register_backward_hook是为了方便查看这几层学出来的结果,对网络结构无影响。
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
# 生成卷积核的邻域坐标
def _get_p_n(self, N, dtype):
"""
torch.meshgrid():Creates grids of coordinates specified by the 1D inputs in attr:tensors.
功能是生成网格,可以用于生成坐标。
函数输入两个数据类型相同的一维张量,两个输出张量的行数为第一个输入张量的元素个数,
列数为第二个输入张量的元素个数,当两个输入张量数据类型不同或维度不是一维时会报错。
其中第一个输出张量填充第一个输入张量中的元素,各行元素相同;
第二个输出张量填充第二个输入张量中的元素各列元素相同。
"""
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# p_n ===>offsets_x(kernel_size*kernel_size,) concat offsets_y(kernel_size*kernel_size,)
# ===> (2*kernel_size*kernel_size,)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
# (1, 2*kernel_size*kernel_size, 1, 1)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
# 获取卷积核在feature map上所有对应的中心坐标,也就是p0
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
# (b, 2*kernel_size, h, w)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
# 将获取的相对坐标信息与中心坐标相加就获得了卷积核的所有坐标。
# 再加上之前学习得到的offset后,就是加上了偏移量后的坐标信息。
# 即对应论文中公式(2)中的(p0+pn+Δpn)
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# p_n ===> (1, 2*kernel_size*kernel_size, 1, 1)
p_n = self._get_p_n(N, dtype)
# p_0 ===> (1, 2*kernel_size*kernel_size, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
# (1, 2*kernel_size*kernel_size, h, w)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
# b, h, w, 2*kerel_size*kernel_size
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# x ===> (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# 因为x是与h轴方向平行,y是与w轴方向平行。故将2D卷积核投影到1D上,位移公式如下:
# 各个卷积核中心坐标及邻域坐标的索引 offsets_x * w + offsets_y
# (b, h, w, kernel_size*kernel_size)
index = q[..., :N] * padded_w + q[..., N:]
# (b, c, h, w, kernel_size*kernel_size) ===> (b, c, h*w*kernel_size*kernel_size)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
# (b, c, h*w)
# x_offset[0][0][0] = x[0][0][index[0][0][0]]
# index[i][j][k]的值应该是一一对应着输入x的(h*w)的坐标,且在之前将index[i][j][k]的值clamp在[0, h]及[0, w]范围里。
# (b, c, h, w, kernel_size*kernel_size)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
# (b, c, h, w, kernel_size*kernel_size)
b, c, h, w, N = x_offset.size()
# (b, c, h, w*kernel_size)
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
# (b, c, h*kernel_size, w*kernel_size)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
def forward(self, x):
# (b, c, h, w) ===> (b, 2*kernel_size*kernel_size, h, w)
offset = self.p_conv(x)
if self.modulation:
# (b, c, h, w) ===> (b, kernel_size*kernel_size, h, w)
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
# kernel_size*kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2*kernel_size*kernel_size, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2*kernel_size*kernel_size)
p = p.contiguous().permute(0, 2, 3, 1)
# 将p从tensor的前向计算中取出来,并向下取整得到左上角坐标q_lt。
q_lt = p.detach().floor()
# 将p向上再取整,得到右下角坐标q_rb。
q_rb = q_lt + 1
# 学习的偏移量是float类型,需要用双线性插值的方法去推算相应的值。
# 同时防止偏移量太大,超出feature map,故需要torch.clamp来约束。
# Clamps all elements in input into the range [ min, max ].
# torch.clamp(a, min=-0.5, max=0.5)
# p左上角x方向的偏移量不超过h,y方向的偏移量不超过w。
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
# p右下角x方向的偏移量不超过h,y方向的偏移量不超过w。
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
# p左上角的x方向的偏移量和右下角y方向的偏移量组合起来,得到p左下角的值。
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
# p右下角的x方向的偏移量和左上角y方向的偏移量组合起来,得到p右上角的值。
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p。
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# 双线性插值公式里的四个系数。即bilinear kernel。
# 作者代码为了保持整齐,每行的变量计算形式一样,所以计算需要做一点对应变量的对应变化。
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# 计算双线性插值的四个坐标对应的像素值。
# (b, c, h, w, kernel_size*kernel_size)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# 双线性插值的最后计算
# (b, c, h, w, kernel_size*kernel_size)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
# (b, kernel_size*kernel_size, h, w) ===> (b, h, w, kernel_size*kernel_size)
m = m.contiguous().permute(0, 2, 3, 1)
# (b, h, w, kernel_size*kernel_size) ===> (b, 1, h, w, kernel_size*kernel_size)
m = m.unsqueeze(dim=1)
# (b, c, h, w, kernel_size*kernel_size)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
# x_offset: (b, c, h, w, kernel_size*kernel_size)
# x_offset: (b, c, h*kernel_size, w*kernel_size)
x_offset = self._reshape_x_offset(x_offset, ks)
# out: (b, c, h, w)
out = self.conv(x_offset)
return out