Flink / Scala - DataStream Broadcast State 模式示例详解
一.引言
上一篇文章 Flink / Scala - DataSet 应用 Broadcast Variables 介绍了 DataSet 场景下 Broadcast 的使用,本文将介绍 DataStream 中的 Broadcast 应用场景,与 DataSet 类似,Broadcast 的值是所有 task 公用的,Broadcast State 是为 DataStreaming 所有 task 定制的可实时修改的公用值。
二.代码常规介绍
DataStream output = dataStream
.connect(BroadcastStream)
.process(
// KeyedBroadcastProcessFunction 中的类型参数表示:
// 1. key stream 中的 key 类型
// 2. 非广播流中的元素类型
// 3. 广播流中的元素类型
// 4. 结果的类型,在这里是 string
new KeyedBroadcastProcessFunction() {
// 模式匹配逻辑
}
); 常规使用中我们都包含一个数据流 DataStream,其中包含我们需要处理的数据,如果处理逻辑会随着一个状态值的改变而改变,这是可以引入第二个数据流成为广播流 BroadcastStream,通过调用 DataStream 的 connect 方法,并将 BroadcastStream 参数传入即可获得一个 BroadcastConnectedStream,这时数据同时包含数据流和状态流,需要重写 process 函数处理两个流的数据,根据 DataStream 是否是 Keyd-Stream,Process 方法分为:
· keyed 流,那就是 KeyedBroadcastProcessFunction 类型
· non-keyed 流,那就是 BroadcastProcessFunction 类型
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 负责处理非广播流中的元素。 两个子类型定义如下:
public abstract class BroadcastProcessFunction extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector out) throws Exception;
}
public abstract class KeyedBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception;
} 需要注意的是 processBroadcastElement() 负责处理广播流的元素,而 processElement() 负责处理另一个流的元素。两个方法的第二个参数(Context)不同,均有以下方法:
得到广播流的存储状态:ctx.getBroadcastState(MapStateDescriptor
查询元素的时间戳:ctx.timestamp()
查询目前的 Watermark:ctx.currentWatermark()
目前的处理时间 (processing time):ctx.currentProcessingTime()
产生旁路输出:ctx.output(OutputTag
三.应用实例
上面说的比较官方,下面通过一个简单的例子理解一下 BroadCast Value 和 BroadCast Stream 的用处,上面提到了 BroadCast Stream 作为一个状态流控制 DataStream 的数据输出,下面实现以下功能:
DataStream: 定期生成 num - 100+num 的 100 个数字,每次生成周期初始化 num + 100
BroadCastStream:不定期传入状态控制输出状态,分为 odd-单数 even-双数
Sink:根据 odd 和 even 的状态,print 输出 100 个数字中的单数或者双数
1.DataStream
5s 中生成 num - (num+100) 的数字,下一批数据比上一批增加 100,这里继承 RichSourceFunction 自定义 Source 来源然后通过 addSource 实现,完整的 DataStream Source 生成方法参考: Flink / Scala - DataSource 之 DataStream 获取数据总结。
// 每5s生成一批数据 数据流
case class InputData(num: Int)
class SourceFromCollection extends RichSourceFunction[InputData] {
private var isRunning = true
var start = 0
override def run(ctx: SourceFunction.SourceContext[InputData]): Unit = {
while ( {
isRunning
}) {
(start to (start + 100)).foreach(num => {
ctx.collect(InputData(num))
})
start += 100
TimeUnit.SECONDS.sleep(5)
}
}
override def cancel(): Unit = {
isRunning = false
}
}
val keyedStream = env.addSource(new SourceFromCollection()).setParallelism(1).keyBy(_.num)上述流根据 num- num+100 的数字生成 InputData 类,并通过 keyBy 生成 Keyd-Stream。
2.BroadCastStream
BroadCastStream 广播流即本例中的状态流,这里通过 File 传递状态值并解析,同样是继承 RichFunction 实现自定义的 Source,每 1s 从对应文件读取,获取是否有新的状态传入。
// MapStateDescriptor odd: 奇数 even: 偶数
case class FilterState(state: String)
// 每s监控一次文件,并读取最新的状态
class SourceFromFile extends RichSourceFunction[String] {
private var isRunning = true
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
val bufferedReader = new BufferedReader(new FileReader("./data.txt"))
while ( {
isRunning
}) {
val line = bufferedReader.readLine
if (!StringUtils.isBlank(line)) {
ctx.collect(line)
}
TimeUnit.SECONDS.sleep(1)
}
}
override def cancel(): Unit = {
isRunning = false
}
}
val ruleStateDescriptor = new MapStateDescriptor("RulesBroadcastState", classOf[String], classOf[FilterState])
// 广播流,广播规则并且创建 BroadCast
val ruleStream = env.addSource(new SourceFromFile).setParallelism(1).map(new RichMapFunction[String, FilterState]() {
override def map(in: String): FilterState = {
FilterState(in)
}
}).broadcast(ruleStateDescriptor)
stateDescriptor 负责声明广播状态的类型,这里定义为 MapStateDescriptor ,后续通过 String 类型的 key 即可获取对应的 FilterState,从而决定 DataStream 中的数据如何 sink。
3.合并 DataStream 与 BroadCastStream
DataStream.connect(BroadCastStream),由于原始 DataStream 为 keyd-stream,所以使用 keyedBroadcastProcessFunction,共包含四个参数:
· ks - keyBy 字段的类型,这里根据 InputData.num keyBy,所以是 Int
· IN1 - DataStream 数据流的类型,这里是 InputData
· IN2 - BroadCastStream 广播流的类型,这里是 FilterState
· OUT - Sink 输出端为直接输出 Print String,所以为 String
keyedStream.connect(ruleStream).process(new KeyedBroadcastProcessFunction[Int, InputData, FilterState, String] {
// 与之前的 Descriptor 相同
val ruleStateDescriptor = new MapStateDescriptor("RulesBroadcastState", classOf[String], classOf[FilterState])
override def processElement(inputData: InputData, context: KeyedBroadcastProcessFunction[Int, InputData, FilterState, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val filterStateClass = context.getBroadcastState(ruleStateDescriptor).get("broadcastStateKey")
val filterState = if (filterStateClass == null) {
"odd"
} else {
filterStateClass.state
}
// 奇数模式
if (filterState == "odd" && inputData.num % 2 != 0) {
out.collect(inputData.num.toString)
}
// 偶数模式
if (filterState == "even" && inputData.num % 2 == 0) {
out.collect(inputData.num.toString)
}
}
override def processBroadcastElement(filterState: FilterState, context: KeyedBroadcastProcessFunction[Int, InputData, FilterState, String]#Context, collector: Collector[String]): Unit = {
// 从广播中获取规则
val broadCastValue = context.getBroadcastState(ruleStateDescriptor)
broadCastValue.put("broadcastStateKey", filterState)
println(s"Rule Changed: ${filterState.state}")
}
}).setParallelism(1).print()A. ProcessElement
该方法负责输出数据,根据 FilterState 的状态是 odd-单数 还是 even-双数,状态默认为 odd-单数。通过 context.getBroadcastState(StateDescriptor) 方法获取 BroadcastStream 中的 FilterState 数据。注意这里的 StateDescriptor 要与上面初始化的 StateDescriptor 保持一致。
B. ProcessBroadcastElement
该方法负责处理 Broadcast 数据流并更新至 context,从而其他 task 节点在执行 processElement 方法时获取最新的状态值,这里 put 的 Key 和上述方法 get 的 Key 需要保持一致,否则获取状态值为 null。
4. 测试
为了本地测试方便查看,两个 Stream 的 parallelism 都设置为1。
状态文件 File 为空,此时默认状态为 odd,输出单数:
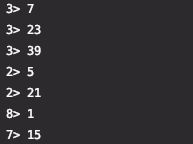
文件内增加一行 even,并 ctrl s 保存,此时 Broadcast 1s 的间隔检测到新状态 even,处理并更细至各 task,各 task 输出偶数:

再次增加一行 odd,此时输出状态改变,重新修改为输出单数:

一个基本的 BroadcastValue 控制 DataStream 的实例就完成了,状态文件夹最终包含两行状态数据:

5.完整代码
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import org.apache.commons.lang3.StringUtils
import java.io.BufferedReader
import java.io.FileReader
import java.util.concurrent.TimeUnit
object BroadCastStateDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 每5s生成一批数据 数据流
case class InputData(num: Int)
class SourceFromCollection extends RichSourceFunction[InputData] {
private var isRunning = true
var start = 0
override def run(ctx: SourceFunction.SourceContext[InputData]): Unit = {
while ( {
isRunning
}) {
(start to (start + 100)).foreach(num => {
ctx.collect(InputData(num))
})
start += 100
TimeUnit.SECONDS.sleep(5)
}
}
override def cancel(): Unit = {
isRunning = false
}
}
val keyedStream = env.addSource(new SourceFromCollection()).setParallelism(1).keyBy(_.num)
// 每s监控一次文件,并读取最新的状态
class SourceFromFile extends RichSourceFunction[String] {
private var isRunning = true
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
val bufferedReader = new BufferedReader(new FileReader("/Users/xudong11/flink/src/main/scala/com.weibo.ug.push.flink/DataStreamingDemo/data.txt"))
while ( {
isRunning
}) {
val line = bufferedReader.readLine
if (!StringUtils.isBlank(line)) {
ctx.collect(line)
}
TimeUnit.SECONDS.sleep(1)
}
}
override def cancel(): Unit = {
isRunning = false
}
}
// MapStateDescriptor odd: 奇数 even: 偶数
case class FilterState(state: String)
val ruleStateDescriptor = new MapStateDescriptor("RulesBroadcastState", classOf[String], classOf[FilterState])
// 广播流,广播规则并且创建 BroadCast
val ruleStream = env.addSource(new SourceFromFile).setParallelism(1).map(new RichMapFunction[String, FilterState]() {
override def map(in: String): FilterState = {
FilterState(in)
}
}).broadcast(ruleStateDescriptor)
// 连接两个流
keyedStream.connect(ruleStream).process(new KeyedBroadcastProcessFunction[Int, InputData, FilterState, String] {
// 与之前的 Descriptor 相同
val ruleStateDescriptor = new MapStateDescriptor("RulesBroadcastState", classOf[String], classOf[FilterState])
override def processElement(inputData: InputData, context: KeyedBroadcastProcessFunction[Int, InputData, FilterState, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val filterStateClass = context.getBroadcastState(ruleStateDescriptor).get("broadcastStateKey")
val filterState = if (filterStateClass == null) {
"odd"
} else {
filterStateClass.state
}
// 奇数模式
if (filterState == "odd" && inputData.num % 2 != 0) {
out.collect(inputData.num.toString)
}
// 偶数模式
if (filterState == "even" && inputData.num % 2 == 0) {
out.collect(inputData.num.toString)
}
}
override def processBroadcastElement(filterState: FilterState, context: KeyedBroadcastProcessFunction[Int, InputData, FilterState, String]#Context, collector: Collector[String]): Unit = {
// 从广播中获取规则
val broadCastValue = context.getBroadcastState(ruleStateDescriptor)
broadCastValue.put("broadcastStateKey", filterState)
println(s"Rule Changed: ${filterState.state}")
}
}).setParallelism(1).print()
env.execute()
}
}
四.总结
1.实现步骤
Broadcast Value 通过 DataStream connect BroadCastStream 连接实现,期间注意两个 ProcessFunction 的重写与对应 StateDescriptor 的定制即可。
2.数据一致性
其次需要注意两个 processFunction 的参数 ctx,在 processElement 中 ctr 是 readOnly,因为一致性的原因,这里只允许 task 读取最新的 State 但不能修改;相反的 processBroadcastElement 方法中的 context 允许修改其中 value 状态的值,注意这里的逻辑要保持全局的一致性(增加随机数随机修改状态值可视作是不保持全局唯一性的操作),否则会造成状态不同从而导致 task 端输出不一致。
3.CheckPoint
所有的 task 均会对 broadcast state 进行 checkpoint:虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时所有 task 均会对 broadcast state 做 checkpoint。 这个设计是为了防止在作业恢复后读文件造成的文件热点即 hotspot 。当然这种方式会造成 checkpoint 一定程度的写放大,放大倍数为 p(=并行度)。Flink 会保证在恢复状态 / 改变并发的时候数据没有重复且没有缺失。 在作业恢复时,如果与之前具有相同或更小的并发度,所有的 task 读取之前已经 checkpoint 过的 state。在增大并发的情况下,task 会读取本身的 state,多出来的并发(p_new - p_old)会使用轮询调度算法读取之前 task 的 state。
4.State Backend
broadcast state 在运行时保存在内存中,需要保证内存充足。这一特性同样适用于所有其他 Operator State,因此不使用 RocksDB state backend。