kafka的外在表现很像消息系统,允许发布和订阅消息流,但是它和传统的消息系统有很大的差异:
- 首先,kafka是个现代分布式系统,以集群的方式运行,可以自由伸缩
- 其次,kafka可以按照要求存储数据,保存多久都可以
- 第三,流式处理将数据处理的层次提示到了新高度,消息系统只会传递数据。kafka的流式处理能力可以让我们用很少的代码就能动态的处理派生流和数据集。所以,kafka不仅仅是个消息中间件
kafka不仅仅是个消息中间件,同时它是个流平台,这个平台上可以发布和订阅数据流(kafka的流,有一个单独的包stream的处理),并把它们保存起来,进行处理,这个就是kafka作者的设计理念。
不装了大神了,上面说的这些都是这位大牛的手写kafka笔记里的,看完之后万分膜拜,所以今天小编也想分享出来给大伙瞧瞧,话不多说,上目录(内容有点多,先来看下,大概了解一下)。
注意:如果需要这份下载完整的手写笔记可【直接点击此处】

01 kafka入门
1.1 什么是kafka
1.2 kafka中的基本概念
- 1.2.1 消息和批次
- 1.2.2 主题和分区
- 1.2.3 生产者和消费者、偏移量、消费者群组
- 1.2.4 Broker和集群
- 1.2.5 保留消息


02 为什么选择kafka
2.1 优点
2.2 常见场景
- 2.2.1 活动跟踪
- 2.2.2 传递消息
- 2.2.3 收集指标和日志
- 2.2.4 提交日志
- 2.2.5 流处理

03 kafka的安装、管理和配置
3.1 安装
- 3.1.1 预备环境
- 3.1.2 下载和安装kafka
- 3.1.3 运行
- 3.1.4 kafka基本的操作和管理
3.2 Broker配置
3.3 硬件配置对kafka性能的影响
- 3.3.1 磁盘吞吐量/磁盘容量
- 3.3.2 内存
- 3.3.3 网络
- 3.3.4 CPU
- 3.3.5 总结


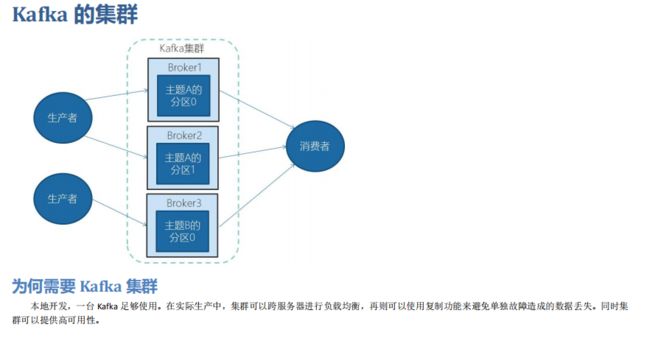
04 kafka的集群
4.1 为何需要kafka集群
4.2 如何估算kafka集群中Broker的数量
4.3 Broker如何加入kafka集群
05 第一个kafka程序
5.1 创建我们的主题
5.2 生产者发送消息
- 5.2.1 必选属性(bootstrap.servers、key.serializer、value.serializer)
5.3 消费者接受消息
- 5.3.1 必选参数(group.id)
5.4 演示示例

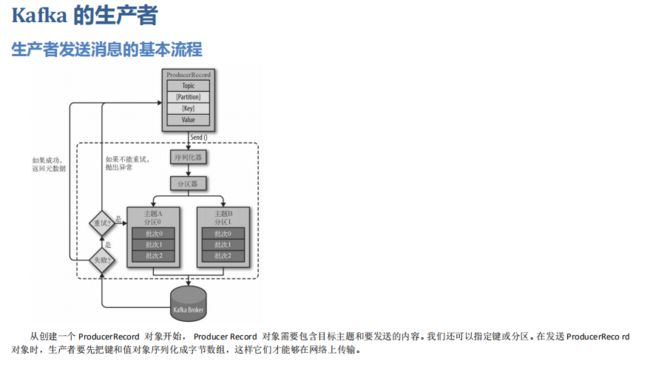
06 kafka的生产者
6.1 生产者发送消息的基本流程
6.2 使用kafka生产者
- 6.2.1 三种发送方式(发送并忘记、同步发送、异步发送)
- 6.2.2 多线程下的生产者
- 6.2.3 更多发送配置(acks、buffer.mempry、max.block.ms、retries、batch.size、linger.ms、compression.type、client.id、、、顺序保证)
6.3 序列化
- 6.3.1 自定义序列化需要考虑的问题
6.4 分区
6.4.1 自定义分区器
07 kafka的消费者
7.1 消费者的入门
- 7.1.1 消费者群组
- 7.1.2 消费者配置
7.2 消费者中的基础概念
- 7.2.1 消费者群组
- 7.2.2 订阅
- 7.2.3 轮询
- 7.2.4 提交和偏移量
7.3 消费者中的核心概念
7.4 kafka中的消费安全
7.5 消费者提交偏移量导致的问题
- 7.5.1 自动提交
- 7.5.2 手动提交(同步)
- 7.5.3 异步提交
- 7.5.4 同步和异步组合
- 7.5.5 特定提交
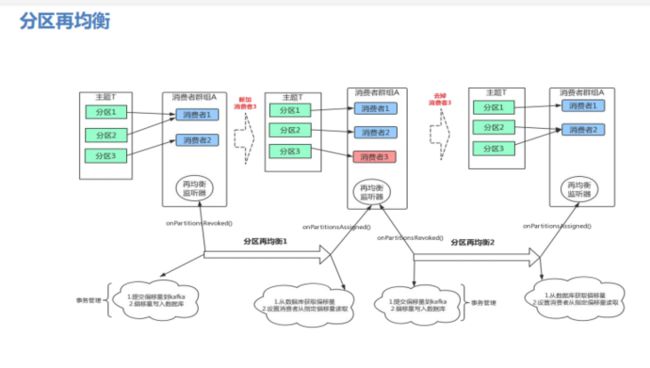
7.6 分区再均衡
7.7 优雅1退出
7.8 反序列化
7.9 独立消费者

08 深入理解kafka
8.1 集群的成员关系
8.2 什么是控制器
8.3 复制-kafka的核心
- 8.3.1 replication-factor
- 8.3.2 副本类型
- 8.3.3 工作机制
8.4 处理请求的内部机制
- 8.4.1 生产请求
- 8.4.2 获取请求
- 8.4.3 ISR
8.5 物理存储机制
- 8.5.1 分区分配
- 8.5.2 文件管理
- 8.5.3 文件格式
- 8.5.4 索引
- 8.5.5 超时数据的清理机制


09 可靠的数据传递
9.1 kafka提供的可靠性保证和架构上的权衡
9.2 复制
9.3 Broker配置对可靠性的影响
- 9.3.1 复制系数
- 9.3.2 不完全的首领选举
- 9.3.3 最少同步副本
9.4 可靠系统里的生产者
- 9.4.1 发送确认
- 9.4.2 配置生产者的重试参数
- 9.4.3 额外的错误处理
9.5 可靠系统里的消费者
- 9.5.1 消费者的可靠性配置
- 9.5.2 显式提交偏移量

10 kafka和Spring的整合
10.1 与Spring集成
- 10.1.1 pom文件
- 10.1.2 统一配置
- 10.1.3 生产者端
- 10.1.4 消费者端
11 SpringBoot和kafka的整合

12 kafka实战之削峰填谷
13 数据管道和流式处理(了解即可)
13.1 数据管道基本概念
13.2 流式处理基本概念

上面都是在说大牛的手写“Kafka笔记”,下面来谈谈kafka面试
关于kafka面试这一块,前阵子有收集一份面试真题(从基础[17]-进阶[15]-高阶[12],总共44道题)
1.Kafka的用途有哪些?使用场景如何?
2.Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
3.Kafka中的HW、LEO、LSO、LW等分别代表什么?
4.Kafka中是怎么体现消息顺序性的?
5.Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
6.Kafka生产者客户端的整体结构是什么样子的?
7.Kafka生产者客户端中使用了几个线程来处理?分别是什么?
8.Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
9.“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
10.有哪些情形会造成重复消费?
11.哪些情景下会造成消息漏消费?
12.KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
13.简述消费者与消费组之间的关系
14.当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
15.topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
16.topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
17.创建topic时如何选择合适的分区数?
1.Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么?
2.优先副本是什么?它有什么特殊的作用?
3.Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
4.简述Kafka的日志目录结构
5.Kafka中有哪些索引文件?
6.如果我指定了一个offset,Kafka怎么查找到对应的消息?
7.如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
8.聊一聊你对Kafka的Log Retention的理解
9.聊一聊你对Kafka的Log Compaction的理解
10.聊一聊你对Kafka底层存储的理解
11.聊一聊Kafka的延时操作的原理
12聊一聊Kafka控制器的作用
13.Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
14.消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
15.Kafka中的幂等是怎么实现的?
1.Kafka中的事务是怎么实现的?
2.失效副本是指什么?有哪些应对措施?
3.多副本下,各个副本中的HW和LEO的演变过程
4.Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
5.为什么Kafka不支持读写分离?
6.Kafka中的延迟队列怎么实现
7.Kafka中怎么实现死信队列和重试队列?
8.Kafka中怎么做消息审计?
9.Kafka中怎么做消息轨迹?
10.怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
11.Kafka有哪些指标需要着重关注?
12.Kafka的哪些设计让它有如此高的性能?
答案在这里啦!!整理起来好多呀,有30页....

关于kafka,今天就撩骚到这儿啦,有关上面的大牛手写“Kafka笔记”(PDF)以及面试进阶(word)都可直接来小编这里领取【直接点击此处】