Fashion MNIST 服饰图像分类(CNN多层感知器)
Fashion MNIST 服饰图像分类
本案例演示了多层感知器来训练对服饰(例如运动鞋和衬衫)图像进行分类。
1. 背景介绍
Fashion MNIST是一个替代 MNIST 手写数字集的图像数据集。它克隆了 MNIST 的所有外在特征:
1、60000张训练图像和对应Label;
2、10000张测试图像和对应Label;
3、10个类别;
4、每张图像28x28的分辨率;
5、4个GZ文件名称都一样;
对于已有的MNIST训练程序,只要修改下代码中的数据集读取路径,或者残暴的用Fashion-MNIST数据集文件将 MNIST 覆盖,替换就瞬间完成了。
不同的是,Fashion-MNIST不再是抽象符号,而是更加具象化的人类必需品——服装,共10大类:
0 T恤(T-shirt/top)
1 裤子(Trouser)
2 套头衫(Pullover)
3 连衣裙(Dress)
4 外套(Coat)
5 凉鞋(Sandal)
6 衬衫(Shirt)
7 运动鞋(Sneaker)
8 包(Bag)
9 靴子(Ankle boot)
2. 导入数据集
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
print(train_images.shape)
print(test_images.shape)
3. 数据预处理
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure()
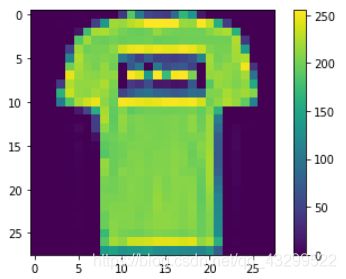
plt.imshow(train_images[1]) # 检查训练集中的第一个图像,你将看到像素值落在0到255的范围内
plt.colorbar()
plt.grid(False)
plt.show()
# 每个图像都映射到一个标签,由于类名不包含在数据集中,因此将它们存储起来以便在绘制图像时使用
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# 我们将这些值缩小到 0 到 1 之间,然后将其馈送到神经网络模型。为此,将图像组件的数据类型从整数转换为浮点数,然后除以 255。
# 务必要以相同的方式对训练集和测试集进行预处理
train_images = train_images / 255.0
test_images = test_images / 255.0
# 为了验证数据的格式是否正确以及我们是否已准备好构建和训练网络,让我们显示训练集中的前25个图像,并在每个图像下方显示类名。
plt.figure(figsize=(8, 8))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

4. 模型构建
4.1. 设置图层
神经网络的基本构造块是层。大部分深度学习都会把简单的层连在一起。大部分层(例如 tf.keras.layers.Dense)都具有在训练期间要学习的参数。
# 该网络中的第一层tf.keras.layers.Flatten将图像的格式从二维数组(28 x 28像素)转换为一维数组(28 * 28 = 784像素))。
# 可以将该层视为图像中像素未堆叠的行,并排列这些行。该层没有要学习的参数,它只改动数据的格式。
# 在像素被展平之后,网络由两个tf.keras.layers.Dense层的序列组成。这些是密集连接或全连接的神经层。
# 第一个Dense层有128个节点(或神经元);第二个(也是最后一个)层是具有 10 个节点的 softmax 层,该层会返回一个具有 10 个概率得分的数组,这些得分的总和为 1。
# 每个节点包含一个得分,表示当前图像属于 10 个类别中某一个的概率。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
4.2. 编译模型
模型还需要再进行几项设置才可以开始训练。这些设置会添加到模型的编译步骤:
- 损失函数:衡量模型在训练期间的准确率。我们希望尽可能缩小该函数,以“引导”模型朝着正确的方向优化。
- 优化器:根据模型看到的数据及其损失函数更新模型的方式。
- 度量标准:用于监控训练和测试步骤。以下示例使用准确率,即图像被正确分类的比例。
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
5. 模型训练
训练神经网络模型需要以下步骤:
- 将训练数据馈送到模型中,在本示例中为 train_images 和 train_labels 数组。
- 模型学习将图像与标签相关联。
- 我们要求模型对测试集进行预测,在本示例中为 test_images 数组。我们会验证预测结果是否与 test_labels 数组中的标签一致。
# 调用 model.fit 方法,使模型与训练数据“拟合”
model.fit(train_images, train_labels, epochs=10)
6. 评估精度
比较模型在测试数据集上的表现情况
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
7. 模型预测
模型经过训练后,我们可以使用它对一些图像进行预测。
predictions = model.predict(test_images)
# 预测结果是一个具有 10 个数字的数组,这些数字说明模型对于图像对应于 10 种不同服饰中每一个服饰的置信度”。
predictions[0]
import numpy as np
# 查看哪个标签的置信度值最大
print(f"predict: {np.argmax(predictions[0])}")
# 检查测试标签以查看该预测是否正确
print(f"label:{test_labels[0]}")
# 我们可以将该预测绘制成图来查看全部 10 个通道
def plot_image(i, predictions_array, true_label, img,):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel('{} {:2.0f}% ({})'.format(class_names[predicted_label],
100 * np.max(predictions_array),
class_names[true_label]), color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color='#777777')
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
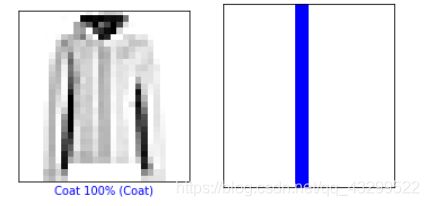
# 查看第6个图像,预测和预测数组
i = 6
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
# 查看第2个图像,预测和预测数组
i = 2
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()

# 我们用它们的预测绘制几张图像。正确的预测标签为蓝色,错误的预测标签为红色。数字表示预测标签的百分比(总计为 100)。
# 请注意,即使置信度非常高,也有可能预测错误。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()

# 最后,使用训练的模型对单个图像进行预测。# Grab an image from the test dataset
img = test_images[0]
print(img.shape)
# tf.keras模型已经过优化,可以一次性对样本批次或样本集进行预测。因此,即使我们使用单个图像,仍需要将其添加到列表中。
img = (np.expand_dims(img,0))
print(img.shape)
# 现在预测此图像的正确标签
predictions_single = model.predict(img) # model.predict返回一组列表,每个列表对应批次数据中的每张图像。
print(predictions_single)
np.argmax(predictions_single[0])