【深度学习】图解 9 种PyTorch中常用的学习率调整策略
learning rate scheduling 学习率调整策略
01 LAMBDA LR
将每个参数组的学习率设置为初始lr乘以给定函数。当last_epoch=-1时,将初始lr设置为初始值。
torch.optim.lr_scheduler.LambdaLR(optimizer,
lr_lambda,
last_epoch=-1,
verbose=False,)参数
lr_lambda(函数或列表):一个函数,给定一个整数形参epoch计算乘法因子,或一个这样的函数列表,optimizer.param_groups中的每组一个。last_epoch(int):最后一个epoch的索引。默认值:1。verbose(bool):如果为True,则在每次更新时向标准输出输出一条消息。默认值:False。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lambda1 = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ", round(0.65 ** i,3)," , Learning Rate = ",round(optimizer.param_groups[0]["lr"],3))
scheduler.step()
plt.plot(range(10),lrs)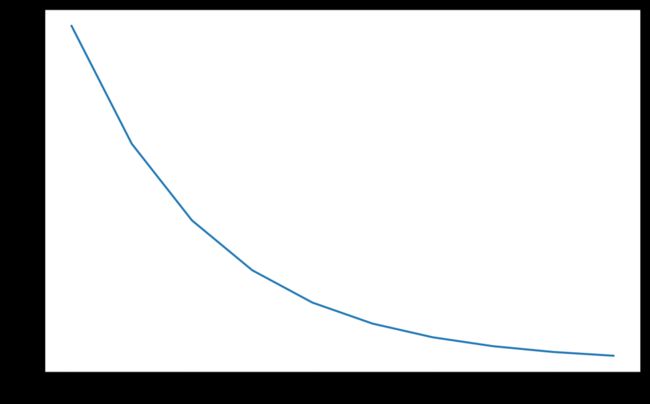
02 MultiplicativeLR
将每个参数组的学习率乘以指定函数中给定的因子。当last_epoch=-1时,将初始lr设置为初始值。
torch.optim.lr_scheduler.MultiplicativeLR(optimizer,
lr_lambda,
last_epoch=-1,
verbose=False,)参数同上。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lmbda = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda=lmbda)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.95," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)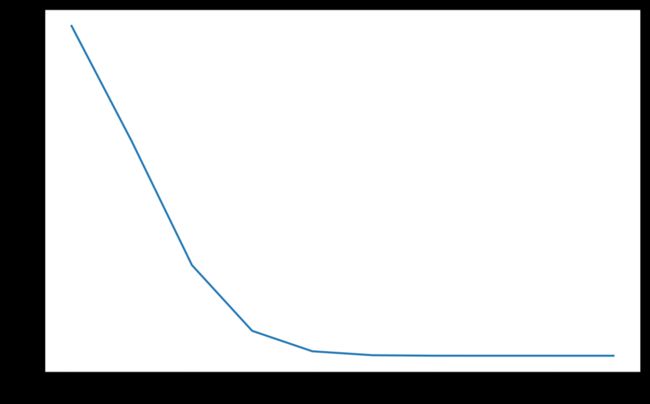
03 StepLR
每一个步长时期,每个参数组的学习速率以伽马衰减。请注意,这种衰减可能与这个调度程序外部对学习速率的其他改变同时发生。
402 Payment Required
torch.optim.lr_scheduler.StepLR(optimizer, step_size,
gamma=0.1, last_epoch=-1,
verbose=False)等间隔调整学习率,每次调整为 lr*gamma,调整间隔为step_size。
参数
step_size(int):学习率调整步长,每经过step_size,学习率更新一次。gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1 if i!=0 and i%2!=0 else 1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)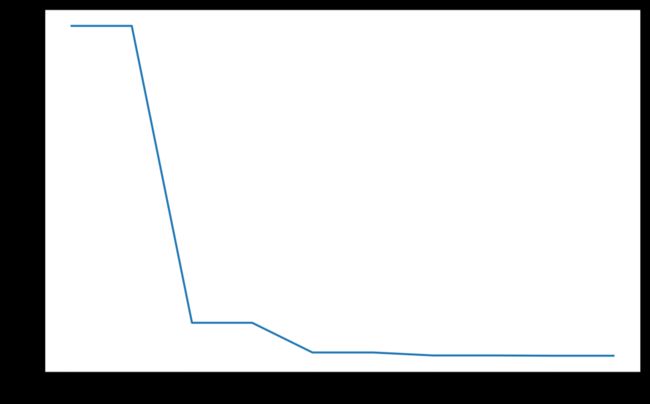
04 MultiStepLR
当前epoch数满足设定值时,调整学习率。这个方法适合后期调试使用,观察loss曲线,为每个实验制定学习率调整时期[1]。
参数:
milestones(list):一个包含epoch索引的list,列表中的每个索引代表调整学习率的epoch。list中的值必须是递增的。如 [20, 50, 100] 表示在epoch为20, 50,100时调整学习率。gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6,8,9], gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1 if i in [6,8,9] else 1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)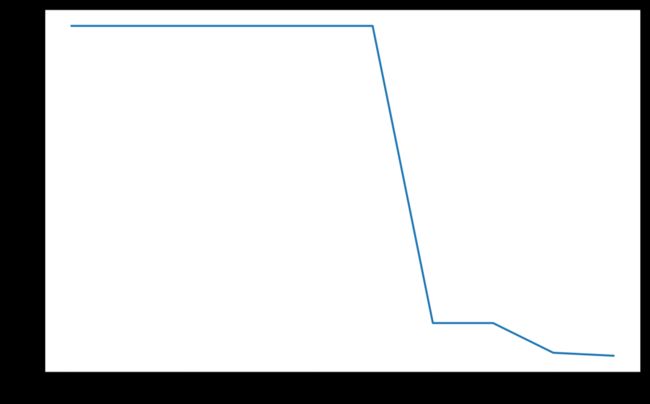
05 ExponentialLR
按指数衰减调整学习率。每一个epoch以伽马衰减每个参数组的学习速率。
torch.optim.lr_scheduler.ExponentialLR(optimizer,
gamma,
last_epoch=-1,
verbose=False,)参数:
gamma(float):学习率调整倍数。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",0.1," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
06 CosineAnnealingLR
模拟余弦退火曲线调整学习率。
使用余弦退火计划设置每个参数组的学习速率。
注意,因为调度是递归定义的,所以学习速率可以在这个调度程序之外被其他操作符同时修改。如果学习速率由该调度器单独设置,则每一步的学习速率为:
402 Payment Required
该方法已在SGDR被提出:带温重启的随机梯度下降中提出。请注意,这只实现了SGDR的余弦退火部分,而不是重启。
https://arxiv.org/abs/1608.03983
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)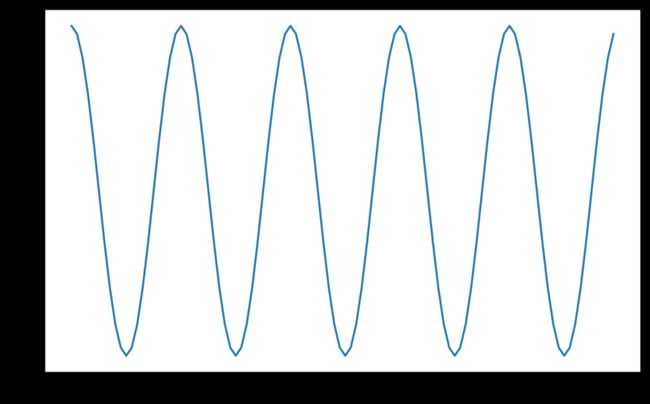
07 CyclicLR
Cyclical Learning Rates for Training Neural Networks 学习率周期性变化。
参数
base_lr(float or list):循环中学习率的下边界。max_lr(floatorlist):循环中学习率的上边界。tep_size_up(int):学习率上升的步数。step_size_down(int):学习率下降的步数。mode(str):{triangular, triangular2, exp_range}中的一个。默认: 'triangular'。gamma(float):在mode='exp_range'时,gamma**(cycle iterations), 默认:1.0。scale_fn:自定义的scaling policy,通过只包含有1个参数的lambda函数定义。0 <= scale_fn(x) <= 1 for all x >= 0.默认:None。如果定义了scale_fn, 则忽略 mode参数last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
CyclicLR - triangular
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
CyclicLR - triangular2
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular2")
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
CyclicLR - exp_range
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001,
max_lr=0.1,step_size_up=5,
mode="exp_range",gamma=0.85)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)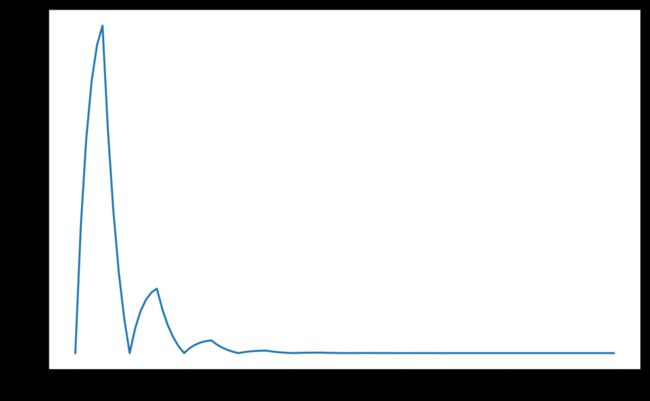
08 OneCycleLR
CLR(如上图所示)不是单调地降低训练过程中的学习率,而是让学习率在设定好地最大值与最小值之间往复变化,文中提出CLR能够work的原因在于两点:
CLR里面增大学习率的过程可以帮助损失函数值逃离鞍点;
最优的学习率会在设定好的最大值与最小值之间,最优学习率附近的值在整个训练过程中会被一直使用到。stepsize一般设置为
402 Payment Required
的2-10倍,一个cycle包括2个stepsize;base_lr一般设置为max_lr的1/3或者1/4。一般当学习率回到base_lr时使训练结束。
在CLR的基础上,"1cycle"是在整个训练过程中只有一个cycle,学习率首先从初始值上升至max_lr,之后从max_lr下降至低于初始值的大小。和CosineAnnealingLR不同,OneCycleLR一般每个batch后调用一次
根据 "1cycle学习速率策略" 设置各参数组的学习速率。1cycle策略将学习率从初始学习率调整到最大学习率,然后从最大学习率调整到远低于初始学习率的最小学习率。这种策略最初是在论文《Convergence: Very Fast Training of Neural Networks Using Large Learning Rates.超收敛:使用大学习速率的神经网络的快速训练》中描述的。
"1cycle学习速率策略" 在每批学习后会改变学习速率。Step应该在一个批处理被用于培训之后调用。
torch.optim.lr_scheduler.OneCycleLR(
optimizer, # 优化器
max_lr, # 学习率最大值
total_steps=None, epochs=None, steps_per_epoch=None, # 总step次数
pct_start=0.3, anneal_strategy='cos', # 学习率上升的部分step数量的占比
cycle_momentum=True, base_momentum=0.85, max_momentum=0.95,
div_factor=25.0, # 初始学习率 = max_lr / div_factor
final_div_factor=10000.0, # 最终学习率 = 初始学习率 / final_div_factor
three_phase=False, last_epoch=-1, verbose=False)需要设置的参数
max_lr:最大学习率
total_steps:迭代次数
div_factor:初始学习率= max_lr / div_factor
final_div_factor:最终学习率= 初始学习率 / final_div_factor
OneCycleLR - cos
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim. \
lr_scheduler.OneCycleLR(
optimizer, max_lr=0.1,
steps_per_epoch=10,
epochs=10)
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)
OneCycleLR - linear
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim. \
lr_scheduler.OneCycleLR(
optimizer, max_lr=0.1,
steps_per_epoch=10,
epochs=10,
anneal_strategy='linear')
lrs = []
for i in range(100):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
# print("Factor = ",i," , Learning Rate = ",optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(lrs)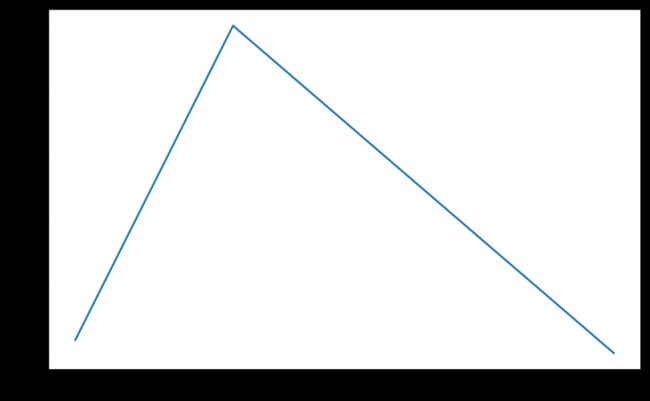
09 CosineAnnealingWarmRestarts
Warm restart的模拟退火学习率调整曲线 使用余弦退火计划设置每个参数组的学习速率,并在 Ti epoch 后重启。
参数
T_0(int):第一次restart时epoch的数值。T_mult(int):每次restart后,学习率restart周期增加因子。。eta_min(float):最小的学习率,默认值为0。last_epoch(int):上一个epoch数,这个变量用于指示学习率是否需要调整。当last_epoch符合设定的间隔时就会调整学习率。当设置为-1时,学习率设置为初始值。
T_0=10, T_mult=1, eta_min=0.001,
import torch
import matplotlib.pyplot as plt
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
lr_sched = torch.optim. \
lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10,
T_mult=1,
eta_min=0.001,
last_epoch=-1)
lrs = []
for i in range(100):
lr_sched.step()
lrs.append(
optimizer.param_groups[0]["lr"]
)
plt.plot(lrs)
T_0=10, T_mult=2, eta_min=0.01,
import torch
import matplotlib.pyplot as plt
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
lr_sched = torch.optim. \
lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=10, T_mult=2,
eta_min=0.01,
last_epoch=-1)
lrs = []
for i in range(300):
lr_sched.step()
lrs.append(
optimizer.param_groups[0]["lr"]
)
plt.plot(lrs)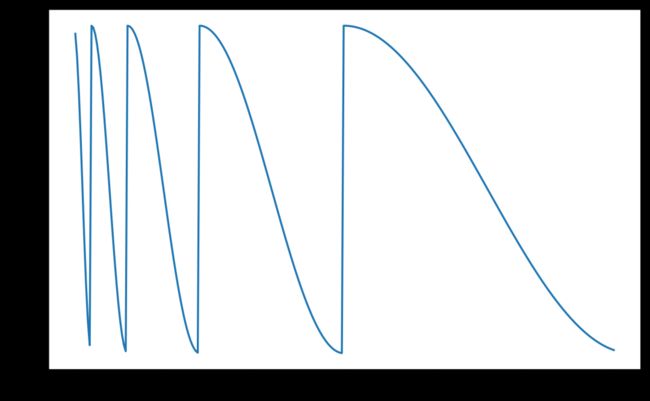
参考资料
[1]
pytorch: https://pytorch.org/docs/stable/optim.html
[2]参考: https://www.kaggle.com/code/isbhargav/guide-to-pytorch-learning-rate-scheduling/notebook
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑
AI基础下载机器学习交流qq群955171419,加入微信群请扫码: