拓端tecdat:PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
全文链接:http://tecdat.cn/?p=24431
原文出处:拓端数据部落公众号
配置神经网络很困难,因为没有关于如何去做的好的理论。
您必须系统地从动态和客观结果的角度探索不同的参数配置,以尝试了解给定预测建模问题的情况。
在本教程中,您将了解如何探索如何针对时间序列预测问题配置 LSTM 网络参数。
相关视频:LSTM神经网络架构和工作原理及其在Python中的预测应用
LSTM神经网络架构和原理及其在Python中的预测应用
完成本教程后,您将了解:
- 如何调整和解释训练时期数的结果。
- 如何调整和解释训练批次大小的结果。
- 如何调整和解释神经元数量的结果。
如何使用 Keras 调整 LSTM 超参数以进行时间序列预测
教程概述
本教程分为 6 个部分;他们是:
- 洗发水销售数据集
- 实验测试
- 调整时期数
- 调整批次大小
- 调整神经元的数量
- 结果总结
环境
本教程假设您已安装 Python SciPy 环境。您可以在此示例中使用 Python 2 或 3。
本教程假设您已经安装了 Keras v2.0 或更高版本以及 TensorFlow 。
本教程还假设您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
洗发水销售数据集
该数据集描述了 3 年期间每月洗发水的销售量。
单位是销售计数,有 36 个观察值。
下面的示例加载并创建已加载数据集的图。
#加载并绘制数据集
# 加载数据集
def paser(x):
return dattme.strptme('190'+x, '%Y-%m')
seres = read_csv('sale.csv', header=0, pare_dats=[0])
# 总结前几行
print(seres.head())
# 绘制线图
seres.plot()
运行示例将数据集加载为 Pandas 序列并输出前 5 行。

然后创建该序列的线图,显示出明显的增加趋势。

洗发水销售数据集的线图
接下来,我们将看看实验中使用的 LSTM 配置和测试工具。
实验测试
本节介绍本教程中使用的测试工具。
数据拆分
我们将把洗发水销售数据集分成两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩余的一年数据将用于测试集。
将使用训练数据集开发模型并对测试数据集进行预测。
测试数据集上的持久性预测实现了每月洗发水销量 136.761 的误差。这在测试集上提供了可接受的较低性能界限。
模型评估
使用滚动预测场景。
测试数据集的每个时间步将一次走一个。模型将用于对时间步长进行预测,然后将采用测试集中的实际预期值,并将其提供给模型用于下一个时间步长的预测。
这模拟了一个真实世界的场景,其中每个月都会有新的洗发水销售观察结果,并用于下个月的预测。
这将通过训练和测试数据集的结构进行模拟。我们将以一次性方法进行所有预测。
将收集对测试数据集的所有预测,并计算误差以总结模型的技能。将使用均方根误差 (RMSE),因为它会惩罚大误差并产生与预测数据(即每月洗发水销售量)相同单位的分数。
数据准备
在我们将 LSTM 模型拟合到数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三个数据转换。
- 转换时间序列数据,使其平稳。具体来说,滞后=1 差分以消除数据中的增加趋势。
- 将时间序列转换为监督学习问题。具体来说,将数据组织成输入和输出模式,其中前一个时间步的观察被用作预测当前时间步的观察的输入
- 将观测值转换为特定的量纲。具体来说,将数据重新缩放到 -1 和 1 之间的值以满足 LSTM 模型的默认双曲正切激活函数。
在计算和误差之前,这些变换在预测中被返回到原始比例。
实验运行
每个实验方案将被运行10次。
这样做的原因是,LSTM网络的随机初始条件在每次训练一个给定的配置时,会导致非常不同的结果。
一个诊断方法将被用来研究模型配置。这就是将创建模型技能随时间变化的线图(训练迭代称为epochs),并对其进行研究,以深入了解一个给定的配置是如何执行的,以及如何调整它以获得更好的性能。
在每个历时结束时,模型将在训练和测试数据集上进行评估,并保存RMSE分数。
每个场景结束时的训练和测试RMSE分数将被打印出来,以显示进度。
训练和测试的RMSE分数系列在运行结束后被绘制成线图。训练得分用蓝色表示,测试得分用橙色表示。
让我们深入了解一下结果。
调整时期
我们将查看调整的第一个 LSTM 参数是训练时期的数量。
该模型将使用一个批次 4 和单个神经元。我们将探索针对不同训练时期数训练此配置的效果。
500 时期epoch 的诊断
代码注释得相当好,应该很容易理解。
#能够在服务器上保存图像
matplotlib.use('Agg')
# 用于加载数据集的日期时间解析函数
def paser(x):
return dateime.strptme('190'+x, '%Y-%m')
# 将一个序列设定为一个监督学习问题
colmns.appnd(df)
df = concat(colns, axis=1)
# 创建一个差分序列
diffene(dtaset, ieral=1):
# 将训练和测试数据扩展到[-1, 1]。
scae(train, test):
scler = salr.fit(train)
# 转换训练集
train = trin.rhape(tain.hpe[0], tran.shpe[1])
# 变换测试
tst_caed = scler.trnfom(test)
# 预测值的逆向缩放
inve_scle(saer, X, yhat):
# 在数据集上评估模型,以转换后的单位返回RMSE
evaluate(mdel, rw_data, scald_dataet, caler)
# 分开
X, y = scald_daaset[:,0:-1], saleddaaset[:,-1)
# 重塑
reshaed = X.reshpe(len(X), 1, 1)
# 预测数据集
predict(rshped, bth_ize=tchsize)
# 在预测中反转数据变换
for i in rage(len(outut)):
yat = output[i,0]
# 反转比例
yhat = inrtscle(saer, X[i], yhat)
# 反转差分
yhat = yhat + raaa[i]。
# 存储预测
pdiis.ppd(yhat)
# 报告性能
rmse = srt(mensuederror pricions) )
# 对训练数据进行LSTM网络拟合
fitlstm(tran, tet, raw, caler bath_sie, n_eoch, erns):
# 准备模型
model = Sequential()
moel.ad(LSTM(neons, bh_phpe, stateful)
# 拟合模型
for i in range(nb_epoch):
fit(X, y, epocs=1, bathsze, verose=0, shufle=False)
# 在训练数据上评估模型
mse.apend(evalaion(mdel, rawtain, trai, scler, 0, bcize))
# 在测试数据上评估模型
rmse.append(evalh_size))
# 运行诊断性实验
run():
# 载入数据集
read_csv('sale.csv'
# 将数据转化为平稳的
diffe(raues, 1)
# 将数据转化为有监督的学习
supd = timespevied(diues, 1)
suplues = supd.vales
# 将数据分成训练集和测试集
train, test = supues[0:-12], suplues[-12:] 。
# 改变数据的尺度
scar, traaled, tescaled = scale(tain, tst)
# 拟合和评估模型
traed = trainld[2:, :]
# 配置
reas = 10
nbch = 4
nphs = 500
nnens = 1
# 运行诊断性测试
for i in range(ret):
fit(train, tes, rawues, scler, nbth, necs, neons)
注意:考虑到算法或评估程序的随机性,或数值精度的差异。考虑多次运行该示例并比较平均结果。
运行实验会在 10 次实验运行结束时输出训练和测试集的 RMSE。

还创建了每个训练时期之后训练集和测试集上的一系列 RMSE 分数的线图。

500 个时期的诊断结果
结果清楚地表明,几乎所有实验运行的 RMSE 在训练时期都有下降趋势。
它表明模型正在学习问题并且具有一定的预测能力。事实上,所有最终测试分数都低于在这个问题上实现 136.761 的 RMSE 的简单持久性模型(朴素预测)的误差。
结果表明,更多的训练时期将产生更熟练的模型。
让我们尝试将 epoch 数从 500 加倍到 1000。
1000个时期的诊断
在本节中,我们使用相同的实验设置并拟合模型超过 1000 个训练时期。
具体来说, 在 run() 函数中将 n_epochs 参数设置为 1000。
nepohs = 1000注意: 考虑到算法或评估程序的随机性,或数值精度的差异。考虑多次运行该示例并比较平均结果。
运行该示例会输出最后一个 epoch 中训练集和测试集的 RMSE。

还创建了每个时期的测试和训练 RMSE 分数的线图。

1000 个时期的诊断结果
我们可以看到,模型误差的下降趋势确实在继续,而且似乎在放缓。
训练和测试用例的线条变得更加水平,但仍普遍呈现下降趋势,尽管变化率较低。一些测试错误的例子显示了大约 600 个时期可能出现的拐点,并且可能显示出上升趋势。
我们对测试集上持续改进的平均性能感兴趣,而且这种情况可能会持续下去。
让我们尝试将 epoch 数从 1000 增加一倍到 2000。
2000 时期Epoch 的诊断
在本节中,我们使用相同的实验设置并拟合模型超过 2000 个训练时期。
具体来说, 在run() 函数中将 npoch参数设置为 2000 。
nepoch = 2000注意:考虑到算法或评估程序的随机性,或数值精度的差异。考虑多次运行该示例并比较平均结果。
运行该示例会输出最后一个 epoch 中训练集和测试集的 RMSE。

还创建了每个时期的测试和训练 RMSE 分数的线图。

2000 时期epoch 的诊断结果
正如人们可能已经猜到的那样,在训练和测试数据集上的额外 1000 个 epoch 中,误差的下降趋势仍在继续。
值得注意的是,大约一半的案例在运行结束之前一直在减少误差,而其余的则显示出增加趋势的迹象。
增长的趋势是过度拟合的标志。这是当模型过度拟合训练数据集时,其代价是测试数据集上的性能下降。它的例子是在训练数据集上的持续改进,以及在测试数据集上的拐点和最差技能之后的改进。在测试数据集上,只有不到一半的运行显示了这种类型的模式的开始。
尽管如此,测试数据集上的最终历时结果还是非常好。我们可以通过更长的训练看到进一步的收益。
让我们尝试将历时数翻倍,从2000到4000。
4000个时期的诊断
在本节中,我们使用相同的实验设置并拟合模型超过 4000 个训练时期。
具体来说, 在run() 函数中将 n_epochs参数设置为 4000 。
nepocs = 4000注意:考虑到算法或评估程序的随机性,或数值精度的差异。考虑多次运行该示例并比较平均结果。
运行该示例会输出最后一个 epoch 中训练集和测试集的 RMSE。

还创建了每个时期的测试和训练 RMSE 分数的线图。

4000 epoch 的诊断结果
即使超过 4000 个 epoch,也有提高性能的总体趋势。存在一种严重过拟合的情况,即测试误差急剧上升。
同样,大多数运行以“良好”(比持久性更好)的最终测试错误结束。
结果总结
上面的诊断运行有助于探索模型的动态行为,但缺乏客观和可比较的平均性能。
我们可以通过重复相同的实验并计算和比较每个配置的汇总统计来解决这个问题。在这种情况下,完成了 30 次运行,时间值为 500、1000、2000、4000 和 6000。
这个想法是使用大量运行的汇总统计来比较配置,并确切地查看哪些配置的平均性能可能更好。
下面列出了完整的代码示例。
# 运行一个重复实验
epernt(rpeas, sris, ochs):
# 将数据转化为平稳的
dif_vues = diferne(ravaues, 1)
# 将数据转换为有监督的学习
to_spersed(dif_vles, 1)
# 将数据分成训练集和测试集
train, test = spervsed[0:-2], suervues[-12:] 。
# 改变数据的尺度
scale(train, test)
# 运行实验
for r in range(reeats):
# 拟合模型
size = 4
trtried = traled[2:, :]
ltmol = lstm(tamd, bachsie, eohs, 1)
# 预测整个训练数据集,以建立预测的状态
trainmd[:, 0].resape(lentran_tmmed), 1, 1)
predict(tain_rsaped, ah_size=ath_ize)
# 预测测试数据集
te_sapd = tstscaled[:,0:-1)
predict(testped, btze=btc_sze)
for i in range(len(outut)):
yhat = output[i,0]
X = te_saled[i, 0:-1] 。
# 反转比例
yhat = invere(aler, X, yhat)
# 反转差分
yht = invsefece(raw_aues, yat, len+1-i)
# 报告性能
sqrt(men_sqred_eror(a_vals[-12:], pedins) )
# 改变训练历时
echs = [500, 1000, 2000, 4000, 6000] 。
for e in eochs:
exiet(rpats, sries, e)
# 总结结果
boxlot()
运行代码首先输出 5 个配置中每一个的汇总统计信息。值得注意的是,这包括来自每个结果群体的 RMSE 分数的平均值和标准差。
平均值给出了配置的平均预期性能的概念,而标准差给出了方差的概念。最小和最大 RMSE 分数还给出了可能期望的最佳和最坏情况示例的范围。
仅查看平均 RMSE 分数,结果表明配置为 1000 的 epoch 可能更好。结果还表明,可能需要对 1000 至 2000 之间的值进行进一步分析。

分布也显示在箱线图上。这有助于了解分布如何直接比较。
红线显示中位数,方框显示第 25 个和第 75 个百分位数,或中位数 50% 的数据。这种比较还表明,将 epochs 设置为 1000 的选择优于测试的替代方案。它还表明,可以在 2000 或 4000 次迭代时获得最佳性能,但代价是平均性能更差。

总结 Epoch 结果的箱线图
接下来,我们将看看批次大小的影响。
调整批次大小
批次大小控制更新网络权重的频率。
重要的是,在 Keras 中,批量大小必须是测试和训练数据集大小的一个因素。
在上一节探讨训练 epoch 数的部分中,批大小固定为 4,它分为测试数据集(大小为 12)和测试数据集(大小为 20)。
在本节中,我们将探讨改变批大小的影响。我们将训练 epoch 的数量保持在 1000。
诊断 1000 个时期和批次大小为 4
作为提醒,上一节在第二次实验中评估了批量大小为4,历时数为1000的实验。

1000 个时期的诊断结果
诊断 1000 个时期和批次大小为 2
在本节中,我们着眼于将批大小从 4 减半至 2。
这个改动是 对run() 函数中的 n_batch参数进行的 ;例如:
n_batch = 2运行该示例显示了与批大小为 4 相同的总体性能趋势,可能在最后一个时期具有更高的 RMSE。
运行可能会显示出更早稳定 RMES 的行为,而不是似乎继续下降趋势。
下面列出了每次运行最终的 RSME 分数。


还创建了每个时期的测试和训练 RMSE 分数的线图。

1000 个时期和批次大小为 2 的诊断结果
让我们再次尝试使用批量大小。
诊断 1000 个时期和批次大小为 1
这是在每个训练模式之后更新网络。可以与批量学习形成对比,其中权重仅在每个 epoch 结束时更新。
我们可以 在run() 函数中更改 n_batch参数 ;例如:
n_batch = 1同样,运行该示例会输出每次运行的最后一期的 RMSE 分数。

还创建了一个每个历时的测试和训练RMSE分数的线图。
该图表明,随着时间的推移,测试RMSE有更多的变化,也许训练RMSE比大批量的测试RMSE稳定得更快。测试RMSE的变异性增加是意料之中的,因为每次更新对网络所做的改变都会带来很少的反馈。
该图还表明,如果配置被赋予更多的训练历时,也许RMSE的下降趋势会继续下去。

1000 个时期和批次大小为 1 的诊断结果
结果总结
与训练时期一样,我们可以客观地比较网络在给定不同批次大小的情况下的性能。
每个配置运行 30 次,并根据最终结果计算汇总统计信息。
# 运行一个重复的实验
# 将数据转换为平稳的
raw_vues = sres.values
df_vaues = difence(rvalues, 1)
# 将数据转换为监督学习
suesr_lus = surior.values
# 将数据分成训练集和测试集
# 变换数据的尺度
tra_cled,testscld = scale(tain, tet)
# 运行实验
# 拟合模型
tran_timed = tan_saled[2:, :]
lstmmdl = lstm(tainrmd, ach_e, 1000, 1)
# 预测整个训练数据集以建立预测状态
preit(trairehae,bach_ie=bat_size)
# 预测测试数据集
preict(tst_rehapeatc_ze=bathsize)
X = tes_cd[i, 0:-1]
# 反转缩放
yht = ivetcale(aler, X, yhat)
# 反转差分
yat = invese_dfence(awvalus, yat, le(tetsald)+1-i)
# 报告表现
rmse = sqrt(mean_urerror)
# 加载数据集
# 实验
# 改变训练批次
批次 = [1, 2, 4]
boxplot()
仅从平均性能来看,结果表明批量大小为 1 时 RMSE 较低。 正如上一节所述,这可能会随着更多的训练时期而得到进一步改善。

还创建了数据的箱线图,以帮助以图形方式比较分布。该图将中值性能显示为一条红线,其中批次大小为 4 显示最大的差异和最低的中值 RMSE。
调整神经网络是平均性能和该性能的可变性的权衡,理想结果具有低平均误差和低可变性,这意味着它通常是好的和可重复的。

总结批次大小结果的箱线图
调整神经元的数量
在本节中,我们将研究改变网络中神经元数量的影响。
神经元的数量影响网络的学习能力。一般来说,更多的神经元能够以更长的训练时间为代价从问题中学习更多的结构。更多的学习能力也会产生潜在的过度拟合训练数据的问题。
我们将使用 4 和 1000 个训练时期的批量大小。
1000 个时期和 1 个神经元的诊断
我们将从 1 个神经元开始。
提醒一下,这是从 epochs 实验中测试的第二个配置。

1000 个时期的诊断结果
1000 个时期和 2 个神经元的诊断
我们可以将神经元的数量从 1 增加到 2。这有望提高网络的学习能力。
我们可以通过更改run() 函数中的n_neurons 变量 来做到这一点 。
n_neurons = 2运行此配置会输出每次运行的最后一个时期的 RMSE 分数。
结果表明,总体表现不错,但不是很好。

还创建了每个时期的测试和训练 RMSE 分数的线图。
这更能说明问题。它显示了测试RMSE的快速下降,大约在500-750个时期中,一个拐点显示了测试RMSE的上升,几乎所有的运行都是如此。同时,训练数据集显示持续下降到最后一期。
这些都是训练数据集过拟合的迹象。
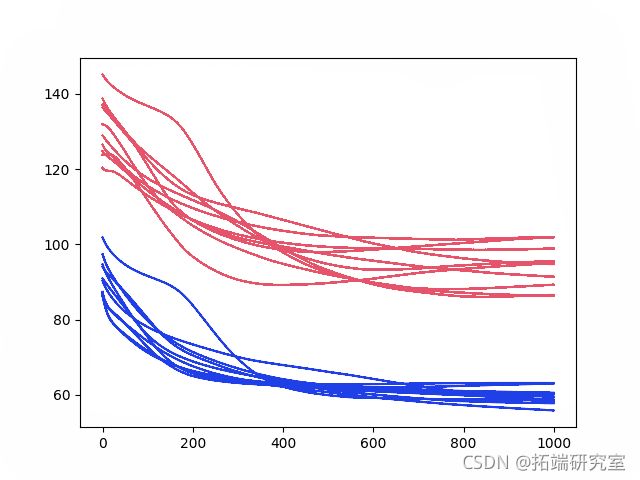
1000 个时期和 2 个神经元的诊断结果
让我们看看这种趋势是否会随着更多的神经元而继续。
1000 个时期和 3 个神经元的诊断
本节着眼于将神经元数量增加到 3 的相同配置。
n_neurons = 3运行此配置会输出每次运行的最后一个时期的 RMSE 分数。
结果与上一节类似;我们看不到 2 或 3 个神经元的最终 epoch 测试分数之间的一般差异。3 个神经元的最终训练分数似乎确实较低,这可能表明过度拟合加速。
训练数据集中的拐点似乎比 2 个神经元实验发生得更早,可能在 300-400 期。
这些神经元数量的增加可能受益于减缓学习速度的额外变化。例如使用正则化方法,如 dropout,减少批量大小,减少训练时期的数量。

还创建了每个时期的测试和训练 RMSE 分数的线图。

1000 个时期和 3 个神经元的诊断结果
结果总结
同样,我们可以客观地比较增加神经元数量同时保持所有其他网络配置的影响。
在本节中,我们将每个实验重复 30 次,并将平均测试 RMSE 性能与 1 到 5 的神经元数量进行比较。
# 运行一个重复的实验
# 将数据转换为平稳的
ra_lus = sees.values
difvles = difece(rwvlus, 1)
# 将数据转换为监督学习
sups_ales = supvor.values
# 将数据分成训练集和测试集
# 变换数据的尺度
trainsld,tet_scld = scale(tain, est)
# 运行实验
err_scres = list()
# 拟合模型
trntied = tr_aed[2:, :]
lsmel = lstm(tritid, bahze, 1000, eons)
# 预测整个训练数据集以建立预测状态
trrehap = ti_rimed[:, 0].rehae(len(train_trimmed), 1, 1)
prdict(trahpe,bahe=achze)
# 预测测试数据集
tet_sape = tetsaled[:,0:-1]
tetrehae = tesespe.reshape(len(tst_ehape), 1, 1)
prect(tes_rhpe,bath_ize=btchsze)
X = ts_cld[i, 0:-1]
# 反转缩放
yhat = ivertle(scaer, X, yhat)
# 反转差分
yht = inversefrce(rw_values, hat, len(tet_saed)+1-i)
# 报告表现
rmse = sqrt(men_sureero(aw_vue[-12:], preiions))
# 加载数据集
# 实验
# 改变神经元
神经元 = [1, 2, 3, 4, 5]
boxplot()
运行实验会输出每个配置的摘要统计信息。
仅从平均性能来看,结果表明具有 1 个神经元的网络配置在 1000 个 epoch 中具有最佳性能,批量大小为 4。

盒须图显示了中值测试集性能的明显趋势,其中神经元的增加导致测试 RMSE 的相应增加。

总结神经元结果的盒须图
所有结果的总结
在本教程中,我们在洗发水销售数据集上完成了相当多的 LSTM 实验。
一般来说,似乎有状态的 LSTM 配置了 1 个神经元,批量大小为 4,并且训练了 1000 个 epochs 可能是一个很好的配置。
结果还表明,也许这种批量大小为 1 并且适合更多 epoch 的配置可能值得进一步探索。
调整神经网络是一项艰巨的实证工作,事实证明 LSTM 也不例外。
本教程展示了配置行为随时间的诊断研究以及测试 RMSE 的客观研究的好处。
扩展
本节列出了对本教程中执行的实验进行扩展的一些想法。
如果您探索其中任何一个,请在评论中报告您的结果;我很想看看你想出了什么。
- dropout。使用正则化方法(例如循环 LSTM 连接上的 dropout)减慢学习速度。
- 层。通过在每层添加更多层和不同数量的神经元来探索额外的分层学习能力。
- 正则化。探索如何使用权重正则化(例如 L1 和 L2)来减缓网络在某些配置上的学习和过度拟合。
- 优化算法。例如经典梯度下降,以查看加速或减慢学习的特定配置是否会带来好处。
- 损失函数。
- 特点和时间步长。探索使用滞后观察作为输入特征和特征的输入时间步长,看看它们作为输入的存在是否可以提高模型的学习和/或预测能力。
- 更大的批量。探索大于 4 的批量大小,可能需要进一步处理训练和测试数据集的大小。
概括
在本教程中,您了解了如何系统地研究 LSTM 网络的配置以进行时间序列预测。
具体来说,你学到了:
- 如何设计用于评估模型配置的系统测试工具。
- 如何随着时间的推移使用模型诊断以及客观预测误差来解释模型行为。
- 如何探索和解释训练时期数、批量大小和神经元数量的影响。
您对调整 LSTM 或本教程有任何疑问吗?
在下面的评论中提出您的问题,我们会尽力回答。

最受欢迎的见解
1.用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
2.Python中利用长短期记忆模型LSTM进行时间序列预测分析 – 预测电力消耗数据
3.python在Keras中使用LSTM解决序列问题
4.Python中用PyTorch机器学习分类预测银行客户流失模型
5.R语言多元Copula GARCH 模型时间序列预测
6.在r语言中使用GAM(广义相加模型)进行电力负荷时间序列分析
7.R语言中ARMA,ARIMA(Box-Jenkins),SARIMA和ARIMAX模型用于预测时间序列数
8.R语言估计时变VAR模型时间序列的实证研究分析案例
9.用广义加性模型GAM进行时间序列分析