卷积神经网络常见模块
深度学习常见模型子模块
- 常见模块
- 1.卷积
-
- 1.1 2D卷积(单通道和多通道)
- 1.2 1x1 卷积
- 1.3 转置卷积(反卷积 Transposed convolution)
- 1.4 分组卷积(Group convolution)
- 1.5 空洞卷积(Dilated convolution)
- 1.6 深度分离卷积(Depthwise convolution)
- 1.7 逐点分离卷积(Pointwise convolution)
- 2.激活函数
-
- 2.1 Sigmoid
- 2.2 Tanh
- 2.3 Softsign
- 2.4 ReLU
- 3.池化
-
- 3.1 最大池化
- 3.2 平均池化
- 4.view
- 5.全连接(FC)
- 6.批量归一化(Batch normlization)
-
- 6.1 对全连接层做批量归一化
- 6.2 对卷积层做批量归一化
- 7.Dropout
- 8.NIN
-
- pytorch实现
- 9.Residual 残差模块
-
- pytorch实现
- 10.bottlenect 瓶颈块
-
- pytorch实现
- 11.Dense 深度块
-
- pytorch实现
- 12.Inception Block
在构建深度学习算法模型时,每个模型都是由不同的子模块一步步搭建完成的,本文总结了,如下几类常见的构建模型的子模块,以及一些模块组合的子模型结构。
如下图所示大部分卷积神经网络算法都是由如下的模块组合构建完成,本文是基于pytorch api实现如下的模块的。
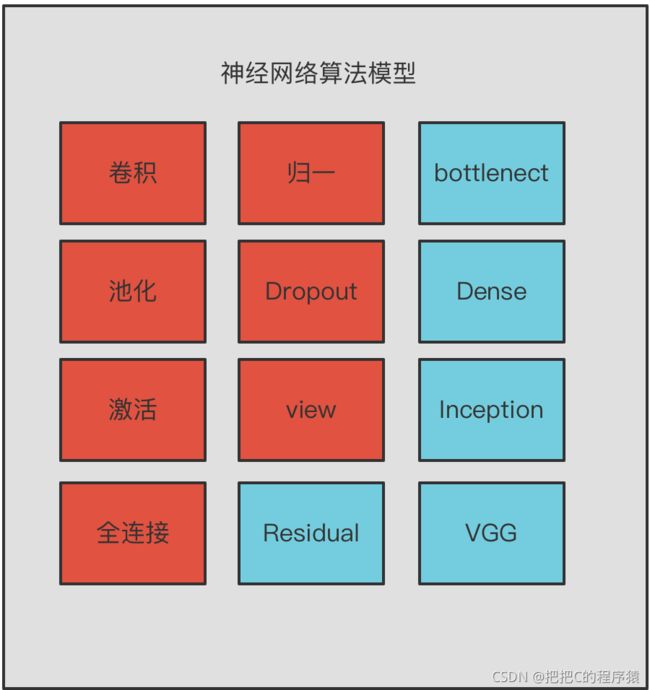
常见模块
1.卷积
卷积,是卷积神经网络中重要组件,不同的卷积结构有着不一样的功能,但本质上都是用于提取特征,比如在传统图像处理中,通过设定不同算子来提取图像的边缘、水平、垂直等固定的特征。
卷积分类:
1.1 2D卷积(单通道和多通道)
单通道

在深度学习中,卷积就是元素级别( element-wise) 的乘法和加法。对于一张仅有 1 个通道的图像,卷积过程如上图所示,过滤函数是一个组成部分为 [ [ 0 , 1 , 2 ] , [ 2 , 2 , 0 ] , [ 0 , 1 , 2 ] ] [[0, 1, 2], [2, 2, 0], [0, 1, 2]] [[0,1,2],[2,2,0],[0,1,2]]的 3 x 3 矩阵,它滑动穿过整个输入。在每一个位置,它都执行了元素级别的乘法和加法,而每个滑过的位置都得出一个数字,最终的输出就是一个 3 x 3 矩阵。(注意:在这个示例中,卷积步长=1;填充=0。我会在下面的算法部分介绍这些概念。)
多通道
通俗来说,单通道的图像就是一张黑白照片,多通道的图像就是一张彩色照片,每个通道对应这些不同颜色值的照片(例如RGB图像对应着三个通道R、G、B)。
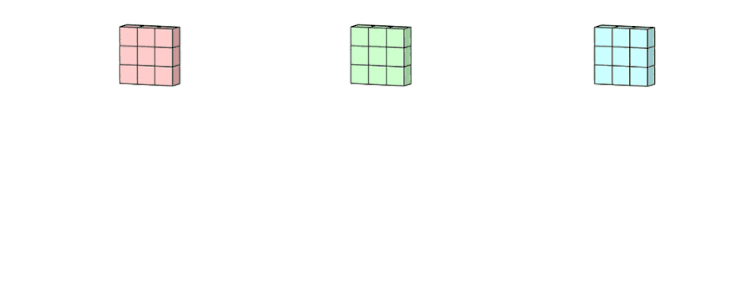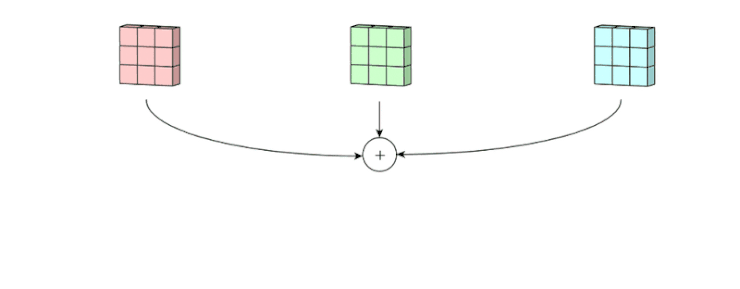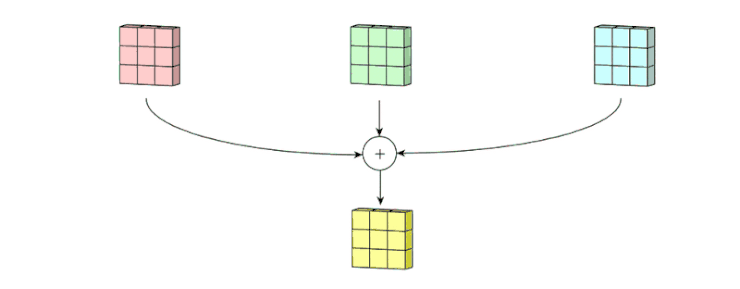
下面让我们一起来看看多通道卷积。生成一个输出通道,就需要将每一个卷积核应用到前一层的输出通道上,这是一个卷积核级别的操作过程。我们对所有的卷积核都重复这个过程以生成多通道,之后,这些通道组合在一起共同形成一个单输出通道。下图可以让大家更清晰地看到这个过程。
这里假设输入层是一个 5 x 5 x 3 矩阵,它有 3 个通道。过滤器则是一个 3 x 3 x 3 矩阵。首先,过滤器中的每个卷积核都应用到输入层的 3 个通道,执行 3 次卷积后得到了尺寸为 3 x 3 的 3 个通道。
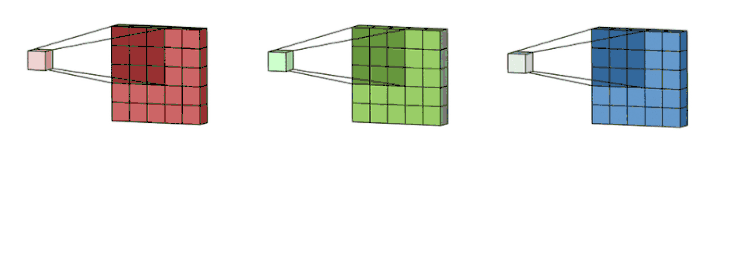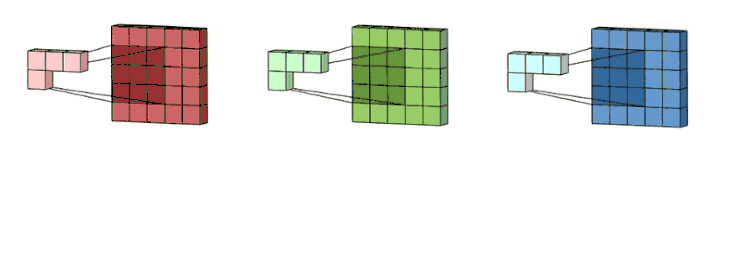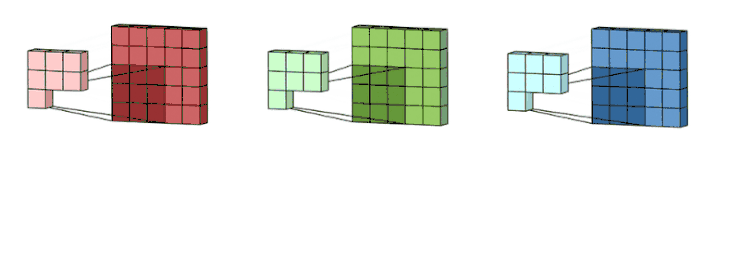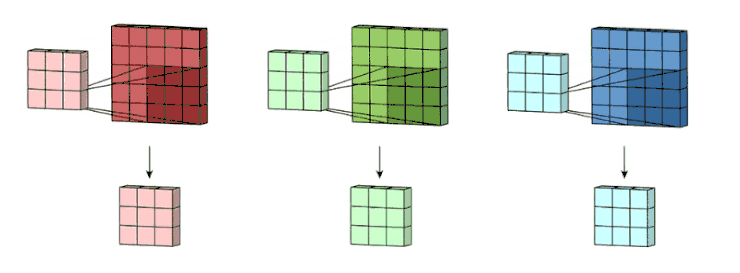
之后,这 3 个通道都合并到一起(元素级别的加法)组成了一个大小为 3 x 3 x 1 的单通道。这个通道是输入层(5 x 5 x 3 矩阵)使用了过滤器(3 x 3 x 3 矩阵)后得到的结果。
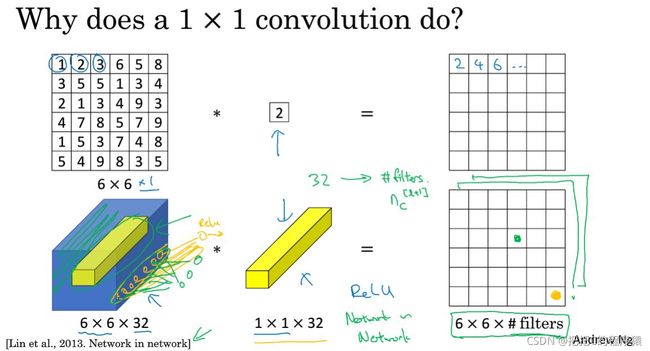
1.2 1x1 卷积
可以把1x1 卷积看作一种降维/升维操作,一种全连接层的处理方式。
实现1x1卷积 有一个必须的条件就是卷积核的通道数和图像的通道数要相同。
如下图上半部分所示,为一个通道为1,1x1卷积,得出的结果就是原始图像的像素值,扩大一倍。
但是如果是通道数大于1的,比如说32通道,就会输出一个6x6x1的矩阵,再往下说,如果有N个这样的卷积核呢,就会输出Nx6x6x1的矩阵,也就是Nx6x6,这样N自然肯定要小于32,这样就是一个减少通道数的降维处理啦。
1.3 转置卷积(反卷积 Transposed convolution)
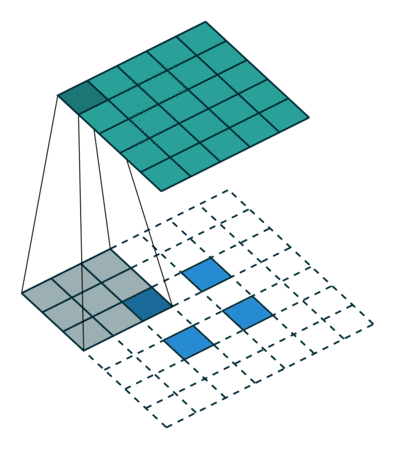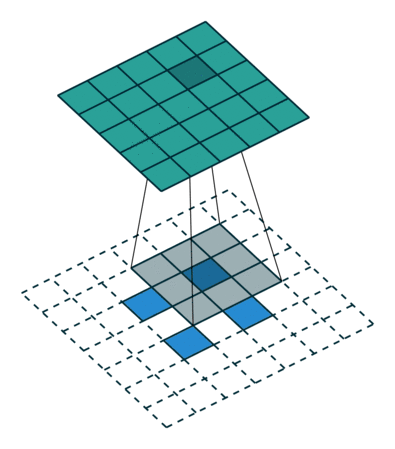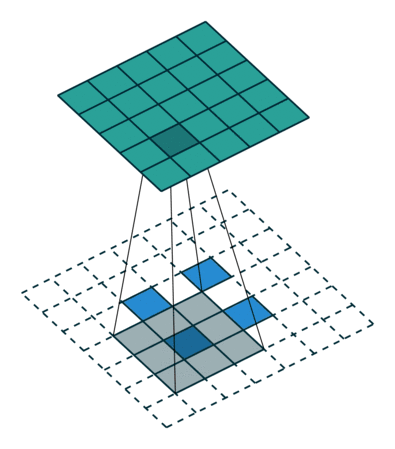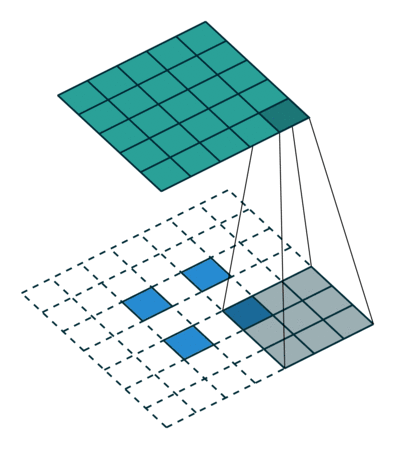
这里可以与正常的卷积做对比,平时我们的卷积都算是下采样,把尺寸大的矩阵变成小的,反卷积顾名思义把小的矩阵尺寸变成大的。
在处理图像应用中有时候我们需要对图像进行上采样,例如生成高分辨率图像。
传统技术上实现,可以通过应用插值方法来实现上采样,神经网络等现代架构则反过来趋向于让网络自己自动学习合适的转换,而不需要人类的干预。我们可以使用转置卷积来实现这一点。
我们可以直接使用卷积来实现转置卷积。例如在下图的案例中,我们 2 x 2 的输入上做转置卷积:其卷积核为 3 x 3,卷积步长为 1,填充padding为 2 x 2 的空格。上采样的输出大小为 4 x 4。

也可以将相同的 2 x 2 输入图像映射出不同的图像大小。下图中,在同一个卷积核为 3 x 3,卷积步长为 1,填充为 2 x 2 空格的 2 x 2 的输入(输入之间插入了一个空格)上做转置卷积,得出的输出大小为 5 x 5。
1.4 分组卷积(Group convolution)
这种卷积方式在卷积运算上没有任何改变,只是将所有的卷积核分成二组,将需要卷积的矩阵按照通道数也划分成二组。如下图所示:
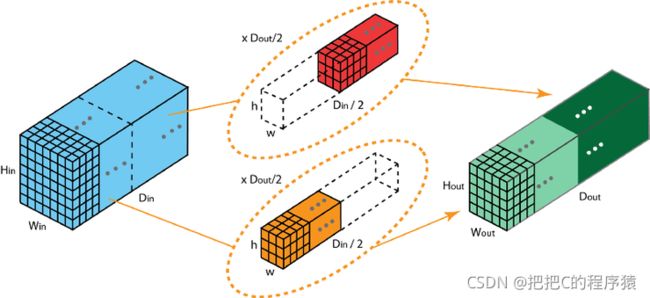
这样卷积的目的,使模型在两个GPU进行训练,实现模型并行化计算。
1.5 空洞卷积(Dilated convolution)
大白话说,空洞卷积通过在卷积核部分之间插入空间让卷积核「膨胀」。这里增加一个参数 l(空洞率)。
这个参数表明了我们想要将卷积核放宽到多大。虽然各实现是不同的,但是在卷积核部分通常插入 l = 1 l=1 l=1 空间。下图显示了当 l = 1 , 2 , 4 l=1,2,4 l=1,2,4 时的卷积核大小。
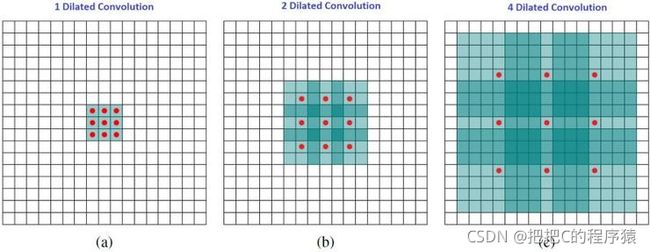
1.6 深度分离卷积(Depthwise convolution)
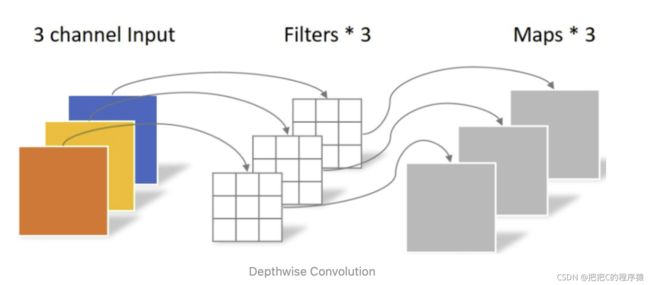
再说深度分离卷积之前,先再认识一下常规的卷积方式,比如:1X1X100X20的卷积核,输出20个通道,此时是100个相同的数同时操作所有通道。
Depthwise Convolution:不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
1.7 逐点分离卷积(Pointwise convolution)
Pointwise Convolution:即采用卷积核大小为1x1来对特征图像逐点进行卷积。
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
深度可分离卷积就是由深度分离卷积和逐点分离卷积组合而成的
2.激活函数
在pytorch中有二种实现激活函数方式
- from torch import nn(nn.ReLU)
- from torch.nn import functional as F (F.relu)
这两种方法实现结果是一样的,只是添加的方式不同。
其中nn.ReLU作为一个层结构,必须添加到nn.Module容器中才能使用,而F.ReLU则作为一个函数调用,看上去作为一个函数调用更方便更简洁。
2.1 Sigmoid
F.sigmoid(x)
S i g m o i d ( x ) = 1 1 + e x p ( − x ) Sigmoid(x)=\frac{1}{1+exp(-x)} Sigmoid(x)=1+exp(−x)1
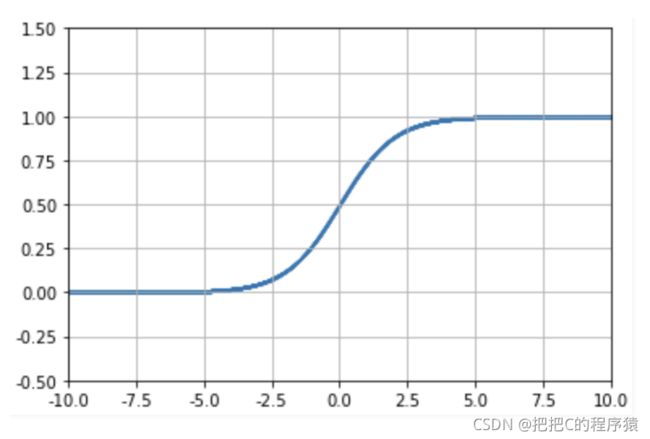
2.2 Tanh
F.tanh(x)
T a n h ( x ) = t a n h ( x ) = e x − e − x e x + e − x Tanh(x)=tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} Tanh(x)=tanh(x)=ex+e−xex−e−x
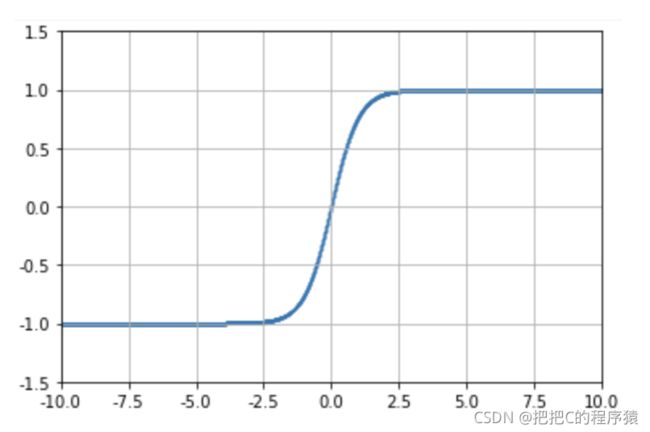
2.3 Softsign
F.softsign(x)
S o f t S i g n ( x ) = x 1 + ∣ x ∣ SoftSign(x)=\frac{x}{1+|x|} SoftSign(x)=1+∣x∣x
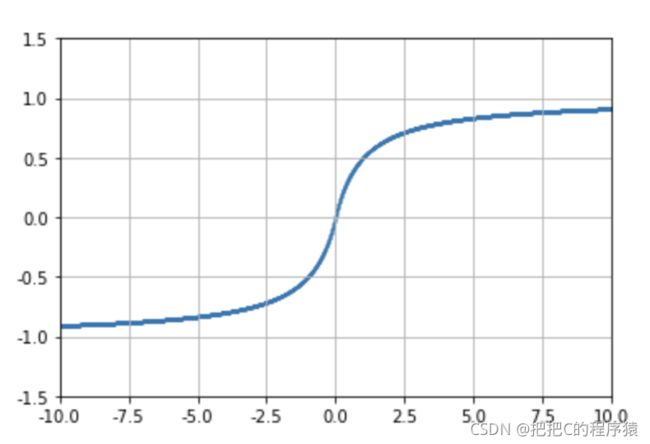
2.4 ReLU
F.relu(x)
R e L U ( x ) = m a x ( 0 , x ) ReLU(x)=max(0,x) ReLU(x)=max(0,x)
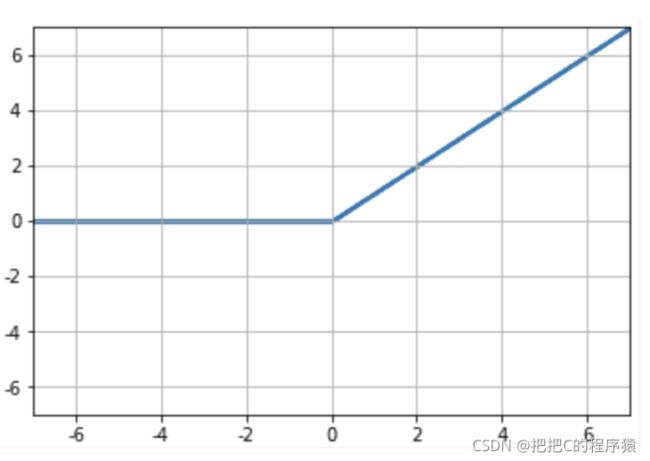
还有一些激活函数,不算常用的就不列出了。
3.池化
池化也有二种方式,跟激活函数类似
池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中元素计算输出,不同于卷积层里计算输入,池化层直接计算池化窗口内元素的最大值或平均值。
3.1 最大池化
class torch.nn.MaxPool2d(kernel_size, stride=None,padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数:
- kernel_size:窗口大小(H x W)
- stride- 步长:默认值是kernel_size
- padding:填充0
- dilation:控制窗口中元素步幅的参数
- return_indices:如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
- ceil_mode:如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取的操作
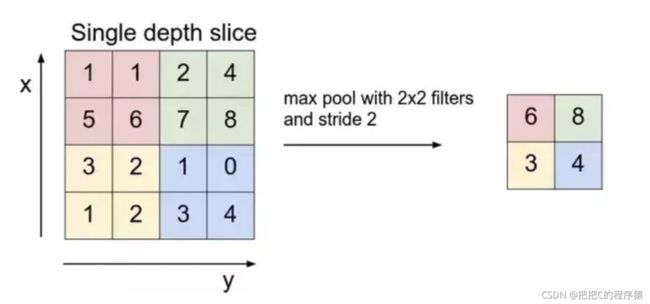
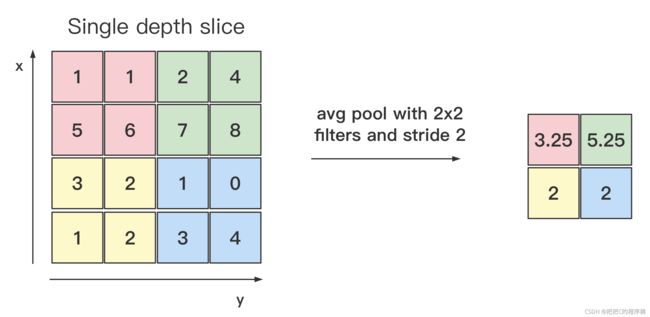
3.2 平均池化
class torch.nn.AvgPool2d(kernel_size, stride=None,padding=0, ceil_mode=False, count_include_pad=True)
4.view
在实现全连接层之前,需要把卷积层输出的多维度的tensor转化为一维的,通常使用出现在forward前向传播中,代码如下:
x = x.view(x.size()[0],-1)
这里对view函数解释一下:
在torch里面,view函数相当于numpy的reshape,来看几个例子:
a = torch.arange(1, 17) # a's shape is (16,)
a.view(4, 4) # output below
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]])
[torch.FloatTensor of size 4x4]
a.view(2, 2, 4) # output below
tensor([[[ 1, 2, 3, 4],
[ 5, 6, 7, 8]],
[[ 9, 10, 11, 12],
[13, 14, 15, 16]]])
[torch.FloatTensor of size 2x2x4]
例如一个长度的16向量x,
x.view(-1, 4)等价于x.view(4, 4)
x.view(-1, 2)等价于x.view(8,2)
5.全连接(FC)
class torch.nn.Linear(in_features,out_features,bias = True
对传入数据应用线性变换: y = A x + b y = Ax+b y=Ax+b
参数:
- in_features:每个输入样本的大小
- out_features:每个输出样本的大小
- bias:如果设置为False,则图层不会学习附加偏差。默认值:True
6.批量归一化(Batch normlization)
批量归一化的好处:
- 可以给模型选择较大的初始学习率
- 可以不用考虑过拟合中存在的dropout、L2正则项参数选择问题
- 不需要使用局部归一化层
6.1 对全连接层做批量归一化
对全连接层做批量归一化,我们将批量归一化置于仿射变换和激活函数之间
批量归一化计算公式如下:
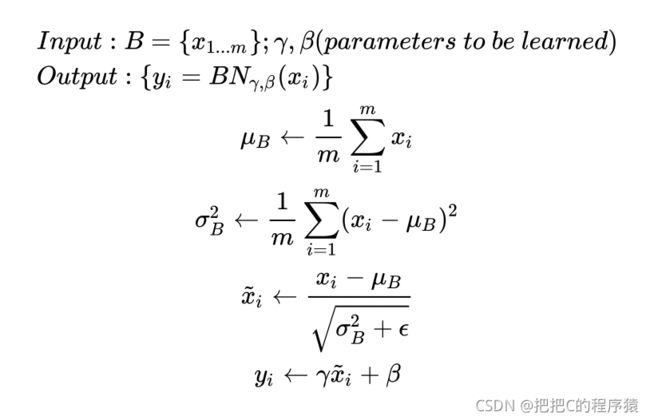
解释一下上图的公式:
- 输入为数值集合( B B B),表示仿射变换输出的一个小批量 B = x ( 1 ) , x ( 2 ) , . . . , x ( m ) B={x^{(1)},x^{(2)},...,x^{(m)}} B=x(1),x(2),...,x(m)。可训练参数 γ \gamma γ, β \beta β;
- BN的具体操作为:先计算 B B B的均值和方差,之后将 B B B集合的均值、方差变换为0、1,最后将 B B B中每个元素乘以 γ \gamma γ再加 β \beta β,输出。
- 归一化的目的:将数据规整到统一区间,减少数据的发散程度,降低网络的学习难度。BN的精髓在于归一之后,使用 γ \gamma γ和 β \beta β作为还原参数,在一定程度上保留原数据的分布。
class torch.nn.BatchNorm2d(num_features, eps=1e-05,momentum=0.1, affine=True)
参数解释:
- num_features: 一般输入参数为batch_sizenum_featuresheight*width,即为其中特征的数量,channel数。
6.2 对卷积层做批量归一化
对卷积层来说,批量归一化发生在卷积计算之后,应用在激活函数之后。
如果卷积计算输出为多个通道,那需要对这些通道的输出分别做批量归一化。
设小批量中有m个样本,在单个通道上,假设卷积计算输出的高和宽分别为q和p,我们需要对该通道中m x p x q个元素同时做批量归一化,这些元素做标准计算时,我们使用相同的均值和方差,即该通道中m x p x q个元素的均值和方差。
7.Dropout
Dropout属于一种在神经网络下的正则化,对于一个正常的神经网络如下图所示:
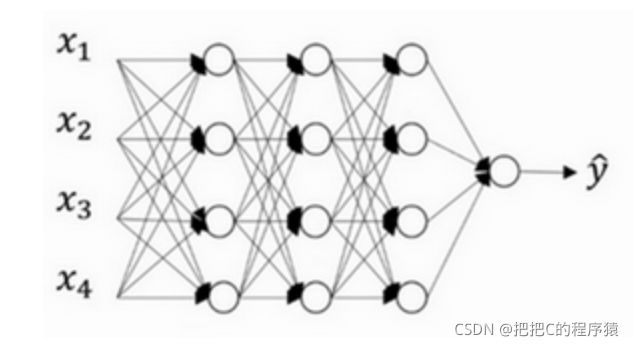
假如针对说这个神经网络存在过拟合,dropout通过在训练的过程中随机丢掉部分神经元来减小神经网络的规模从而防止过拟合。
在训练过程中我们,随机丢掉部分神经元,这里设置一个概率P,它表示针对网络中每一层消除的神经网络节点的概率。
如下图所示红色X的神经元表示已经丢弃的,然后神经网络也删除一部分神经元连接的线。
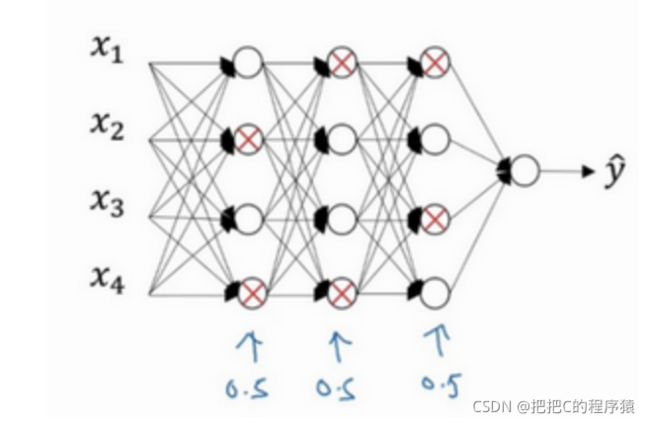
class torch.nn.Dropout(p=0.5,inplace=False)
8.NIN
传统卷积层的输入和输出通常是一个四维数组(样本数,通道,高,宽),而全连接层输入和输出则是一个二维数组(样本,特征)。
如果在全连接层后接上卷积层,则需要将全连接层输出变换为四维。前面提到的1 x 1卷积层可以看成是一个全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。
因此NIN使用1 x 1卷积层来替换全连接层,从而使空间信息自然传递到后面层中。下图对比了NIN同AlexNet和VGG等网络在结构上的主要区别。
NIN模块分成两部分组成:
- 首先用1x1卷积实现,整合多个feature map特征
- 然后对特征进行全局平均池化替代全连接层

pytorch实现
import torch
from torch import nn
import torchvision
from datetime import datetime
#NiN块
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
#1*1卷积层
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
#1*1卷积层
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU()
)
return blk
net = nn.Sequential(
#输入x是[128, 1, 224, 224]
#第一个卷积块
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
#x是[128, 96, 54, 54]
nn.MaxPool2d(kernel_size=3, stride=2),
#x是[128, 96, 26, 26]
#第二个卷积块
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
#x是[128, 256, 26, 26]
nn.MaxPool2d(kernel_size=3, stride=2),
#x是[128, 256, 12, 12]
#第三个卷积块
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
#x是[128,384,12,12]
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
#x是[128, 384, 5, 5]
#第四个卷积块
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
#x是[128, 10, 5, 5]
#全局平均池化层
#全局平均池化层可通过将窗口形状设置成输入的高和宽实现
nn.AvgPool2d(kernel_size=5),
#x是[128, 10, 1, 1]
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
nn.Flatten(start_dim=1, end_dim=3)
#x是[128, 10]
9.Residual 残差模块
是不是神经网络层越深模型效果越好?
答案是错误的,随着网络层结构加深,可能会导致训练很难收敛,同时模型的准确率也会下滑的
而Residual learning 模块可以解决这种因为深度增加而导致性能下降问题
假定某段神经网络的输入是 x,期望输出是 H(x),即 H(x) 是期望的复杂潜在映射,但学习难度大;如果我们直接把输入 x 传到输出作为初始结果,通过下图“shortcut connections(捷径连接)”,那么此时我们需要学习的目标就是 F(x)=H(x)-x,于是 ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,而是最优解 H(X) 和全等映射 x 的差值,即残差 F(x) = H(x) - x;我们的目的就是使F(x)结果逼近于0,使到随着网络加深,准确率不下降。
这里直观的理解,可以理解为我们在加深层的输入端输入x后,我们的目的是希望加深层的输出端输出也是x。这样相当于只加深了层,经过这样的加深层处理后,x值只有微小的误差。
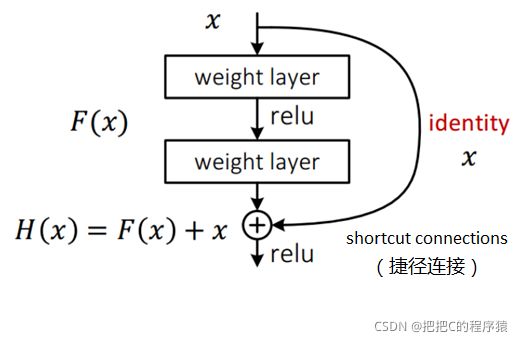
pytorch实现
class Residual(nn.Module):
def __init__(self,in_channels,out_channels,conv1x1=False,stride=1):
super(Residual, self).__init__()
self.conv1=nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,stride=stride)
self.conv2=nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
if conv1x1:
self.conv3=nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride)
else:
self.conv3=None
self.bn1=nn.BatchNorm2d(out_channels)
self.bn2=nn.BatchNorm2d(out_channels)
def forward(self,x):
y=F.relu(self.bn1(self.conv1(x)))
y=self.bn2(self.conv2(y))
if self.conv3:
x=self.conv3(x)
return F.relu(y+x)
10.bottlenect 瓶颈块
bottlenect模块是由残差模块衍生出来的,它主要的作用是对feature map进行降维
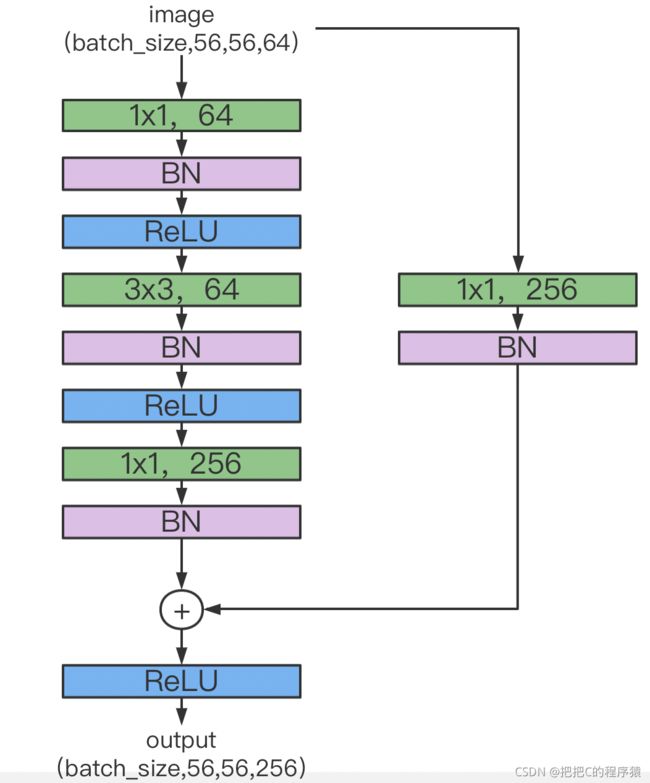
pytorch实现
# 50、101、152层残差块,三个卷积层,1*1,3*3,1*1
class Bottleneck(nn.Module):
# 这里对应是4,对应每层中的64,64,256
expansion=4
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(Bottleneck,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=out_channel,
kernel_size=1,stride=1,bias=False)
self.bn1=nn.BatchNorm2d(out_channel)
self.conv2=nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn2=nn.BatchNorm2d(out_channel)
self.conv3=nn.Conv2d(in_channels=out_channel,out_channels=out_channel*self.expansion,
kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(out_channel*self.expansion)
self.relu=nn.ReLU(inplace=True)
self.downsample=downsample
def forward(self,x):
identity=x
if self.downsample is not None:
identity=downsample(x)
out=self.conv1(x)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
out=self.relu(out)
out=self.conv3(out)
out=self.bn3(out)
out+=identity
out=self.relu(out)
return out
11.Dense 深度块
深层的网络结构,越深越容易凸出一个关键问题:梯度消失,越往后求导,导数可能会越来越小,直至消失。
为了不极端的构建更深的网络,采用特征再利用的方式,提出了一种密集的压缩模型DenseNet
传统CNN每一层前进后,都会产生output,即特征图。这种级联结构,当前层的结果特征图,运至下一层,作为下一层的输入。
而DenseNet则是将当前层得到的特征图,输入到所有后续层。
用公式表示的话,这里设 L L L表示某一网络层, x L x_L xL表示 L L L层输出的值, x L − 1 x_{L-1} xL−1表示 L L L的上一层输出的值。
传统网络的 x L x_L xL与 x L − 1 x_{L-1} xL−1对应函数为
x L = H L ( x L − 1 ) x_L=H_L(x_{L-1}) xL=HL(xL−1)
对于ResNet 残差模块 x L x_L xL与 x L − 1 x_{L-1} xL−1对应函数为
x L = H L ( x L − 1 ) + x L − 1 x_L=H_L(x_{L-1})+x_{L-1} xL=HL(xL−1)+xL−1
对于DenseNet x L x_L xL与 x L − 1 x_{L-1} xL−1对应函数为
x L = H L ( [ x 0 , x 1 , . . . , x L − 1 ] ) x_L=H_L([x_0,x_1,...,x_{L-1}]) xL=HL([x0,x1,...,xL−1])
pytorch实现
def conv_block(in_channels,out_channels):
block=nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
return block
class DenseNet(nn.Module):
def __init__(self,num_convs,in_channels,out_channels):
super(DenseNet, self).__init__()
net=[]
for i in range(num_convs):
in_c=in_channels+i*out_channels
net.append(conv_block(in_c,out_channels))
self.net=nn.ModuleList(net)
self.out_channels=in_channels+num_convs*out_channels
def forward(self,x):
for block in self.net:
y=block(x)
x=torch.cat((x,y),dim=1)
return x
12.Inception Block
Inception Block是通过不同卷积层组合而成的一种新的卷积模块,目的是希望将同一特征图像获得不同尺度下的特征,并最后通过拼接操作聚合输出表示,获得多尺度特征
常见的模块有Inception V1、V2、V3、V4
具体结构可以参考
https://blog.csdn.net/zzc15806/article/details/83447006
学会了这些模块,就可以结合实际的理论深度学习算法模型,来构造对应的模型代码了!!!