StrongSORT:Make DeepSORT Great Again(翻译)
原文链接:https://arxiv.org/abs/2202.13514
代码链接:https://github.com/dyhBUPT/StrongSORT
Abstract.
Existing Multi-Object Tracking (MOT) methods can be roughly classified as tracking-by-detection and joint-detection-association paradigms. Although the latter has elicited more attention and demonstrates comparable performance relative to the former, we claim that the tracking-by-detection paradigm is still the optimal solution in terms of tracking accuracy. In this paper, we revisit the classic tracker DeepSORT and upgrade it from various aspects, i.e., detection, embedding and association.The resulting tracker, called StrongSORT, sets new HOTA and IDF1records on MOT17 and MOT20. We also present two lightweight andplug-and-play algorithms to further refine the tracking results. Firstly,an appearance-free link model (AFLink) is proposed to associate shorttracklets into complete trajectories. To the best of our knowledge, thisis the first global link model without appearance information. Secondly,we propose Gaussian-smoothed interpolation (GSI) to compensate formissing detections. Instead of ignoring motion information like linear interpolation, GSI is based on the Gaussian process regression algorithmand can achieve more accurate localizations. Moreover, AFLink and GSIcan be plugged into various trackers with a negligible extra compu-tational cost (591.9 and 140.9 Hz, respectively, on MOT17). By integrating StrongSORT with the two algorithms, the final tracker Strong-SORT++ ranks first on MOT17 and MOT20 in terms of HOTA andIDF1 metrics and surpasses the second-place one by 1.3 - 2.2. Code willbe released soon
摘要。现有的多目标跟踪(MOT)方法大致可分为检测跟踪(tracking-by-detection)和联合检测关联(joint-detection-association)两种,虽然后者已经引起了更多的关注,并且表现出与前者相当的性能,但我们认为从跟踪精度来看,检测跟踪(tracking-by-detection)仍然是最优的解决方案。本文对经典的跟踪器DeepSORT进行了回顾,并从detection、embedding和association等方面对其进行了升级,提出了一种称为StrongSORT的跟踪器,在MOT17和MOT20上设置了新的HOTA和IDF1记录。我们还提出了两种轻量级、即插即用的算法来进一步完善跟踪结果。首先,提出了一种无外观链接模型appearence-free link(AFLink)模型,将短轨迹关联成完整的轨迹。据我们所知,这是第一个没有外观信息的全局链接模型。其次,我们提出了高斯平滑插值Gaussian-smoothed interpolation(GSI)来补偿漏检。GSI不像线性插值那样忽略运动信息,而是基于高斯过程回归算法,可以实现更精确的定位。此外,AFLink和GSI可以插入到各种跟踪器中,额外的计算成本可以忽略不计(在MOT17上分别为591.9 Hz和140.9 Hz)。通过将StrongSORT与这两种算法相结合,最终的跟踪器Strong-Sort++在HOTA和IDF1度量方面在MOT17和MOT20上排名第一,并以1.3-2.2的优势超过第二名。
1 Introduction
Multi-Object Tracking (MOT) plays an essential role in video understanding. Itaims to detect and track all specific classes of objects frame by frame. In thepast few years, the tracking-by-detection paradigm [3, 4, 36, 62, 69] dominatedthe MOT task. It performs detection per frame and formulates the MOT prob-lem as a data association task. Benefiting from high-performing object detectionmodels, tracking-by-detection methods have gained favor due to their excellent performance.
多目标跟踪(MOT)在视频理解中起着至关重要的作用。它旨在用于逐帧检测和跟踪所有特定类别的对象。在过去的几年里,tracking-by-detection[3,4,36,62,69]在MOT任务中占据主导地位。它按帧执行检测,并将MOT问题公式化为数据关联任务。得益于高性能的目标检测模型,基于检测的跟踪方法因其优良的性能而受到青睐。

Fig. 1. IDF1-MOTA-HOTA comparisons of state-of-the-art trackers with our proposed StrongSORT and StrongSORT++ on MOT17 and MOT20 test sets. The horizontal axis is MOTA, the vertival axis is IDF1, and the radius of the circle is HOTA. ”*”represents our reproduced version. Our StrongSORT++ achieves the best IDF1 and HOTA and comparable MOTA performance.
图1.IDF1-MOTA-HOTA在MOT17和MOT20测试集上与我们建议的StrongSORT和StrongSORT++进行的最先进跟踪器的比较。水平轴是MOTA,垂直轴是IDF1,圆的半径是HOTA。“*”代表我们的复制版本。我们的StrongSORT++实现了最好的IDF1和HOTA以及可与之媲美的MOTA性能。
However, these methods generally require multiple computationally expensive components, such as a detector and an embedding model. To solve this problem, several recent methods [1,60,74] integrate the detector and embedding model into a unified framework. Moreover, joint detection and embedding training appears to produce better results compared with the seperate one [47]. Thus, these methods (joint trackers) achieve comparable or even better tracking accuracy compared with tracking-by-detection ones (seperate trackers).
然而,这些方法通常需要多个计算昂贵的组件,例如检测器和embedding模型。为了解决这一问题,最近的几种方法[1,60,74]将探测器和embedding模型集成到一个统一的框架中。此外,联合检测和embedding训练似乎比单独的检测和嵌入训练产生了更好的效果。因此,joint trackers与seperate trackers相比,实现了相当的跟踪精度,甚至更高的跟踪精度。
The success of joint trackers has motivated researchers to design unified track-ing frameworks for various components, e.g., detection, motion, embedding, and association models [30, 32, 38, 57, 59, 65, 68]. However, we argue that two problems exist in these joint frameworks: (1) the competition between different components and (2) limited data for training these components jointly. Although several strategies have been proposed to solve them, these problems still lower the upper bound of tracking accuracy. On the contrary, the potential of seperate trackers seems to be underestimated.
联合跟踪器的成功促使研究人员为各种组件设计统一的跟踪框架,例如检测、运动、嵌入和关联模型[30,32,38,57,59,65,68]。然而,我们认为这些联合框架中存在两个问题:(1)不同组件之间的竞争和(2)用于联合训练这些组件的数据有限。虽然已经提出了几种策略来解决这些问题,但这些问题仍然降低了跟踪精度的上限。相反,seperate trackers的潜力似乎被低估了。
In this paper, we revisit the classic seperate tracker DeepSORT [62], which is among the earliest methods that apply the deep learning model to the MOT task. It’s claimed that DeepSORT underperforms compared with state-of-the-artmethods because of its outdated techniques, rather than its tracking paradigm. We show that by simply equipping DeepSORT with advanced components invarious aspects, resulting in the proposed StrongSORT, it can achieve new SOTA on popular benchmarks MOT17 [35] and MOT20 [11].
在本文中,我们回顾了经典的独立跟踪器DeepSORT[62],它是最早将深度学习模型应用于MOT任务的方法之一。DeepSORT的性能不如最先进的方法是因为它的技术落后,而不是它的跟踪模式,我们证明了通过简单地为DeepSORT配备先进的组件不变方面(We show that by simply equipping DeepSORT with advanced components invarious aspects.不知道怎么翻译了),从而产生了所提出的StrongSORT,它可以在流行的基准MOT17[35]和MOT20[11]上实现新的SOTA。
Two lightweight, plug-and-play, model-independent, appearance-free algorithms are also proposed to refine the tracking results. Firstly, to better exploit the global information, several methods propose to associate short tracklets into trajectories by using a global link model [12,39,55,56,67]. They usually generate accurate but incomplete tracklets and associate them with global information in an offline manner. Although these methods improve tracking performance sig-nificantly, they all rely on computation-intensive models, especially appearance embeddings. By contrast, we propose an appearance-free link model (AFLink)that only utilizes spatio-temporal information to predict whether the two inputtracklets belong to the same ID.
提出了两种轻量级、即插即用、模型无关、外观无关的算法来改进跟踪结果。首先,为了更好地利用全局信息,几种方法提出通过使用全局链接模型将短轨迹关联到轨迹[12,39,55,56,67]。它们通常生成准确但不完整的轨迹,并用离线的方式将它们与全局信息关联。虽然这些方法显著提高了跟踪性能,但它们都依赖于计算密集型模型,尤其是appearance embeddings。相反,我们提出了一种只利用时空信息来预测两个输入轨迹是否属于同一ID的AFLink模型。
Secondly, linear interpolation is widely used to compensate for missing detections [12, 21, 37, 40, 41, 73]. However, it ignores motion information, which limits the accuracy of the interpolated positions. To solve this problem, we propose the Gaussian-smoothed interpolation algorithm (GSI), which enhances the interpolation by using the Gaussian process regression algorithm [61].
其次,线性插值被广泛用于补偿缺失检测[12,21,37,40,41,73]。但是,该算法忽略了运动信息,限制了插值位置的精度。为了解决这个问题,我们提出了高斯平滑插值算法(GSI),它通过使用高斯过程回归算法来增强插值[61]。
Extensive experiments prove that the two proposed algorithms achieve notable improvements on StrongSORT and other state-of-the-art trackers, e.g.,CenterTrack [77], TransTrack [50] and FairMOT [74]. Particularly, by applyingAFLink and GSI to StrongSORT, we obtain a stronger tracker called Strong-SORT++. It achieves 64.4 HOTA, 79.5 IDF1 and 79.6 MOTA (7.1 Hz) on theMOT17 test set and 62.6 HOTA, 77.0 IDF1 and 73.8 MOTA (1.4 Hz) on theMOT20 test set. Figure 1 compares our StrongSORT and StrongSORT++ withstate-of-the-art trackers on MOT17 and MOT20 test sets. Our method achievesthe best IDF1 and HOTA and a comparable MOTA performance. Furthermore,AFLink and GSI respectively run at 591.9 and 140.9 Hz on MOT17, 224.0 and17.6 Hz on MOT20, resulting in a negligible computational cost.
大量的实验证明,这两种算法在StrongSORT和其他最先进的跟踪器(如CenterTrack[77]、Transtrack[50]和FairMOT[74])上取得了显著改进。特别地,通过将AFLink和GSI应用于StrongSORT,我们得到了一个更强的跟踪器,称为Strong-Sort++。在MOT17测试集上达到64.4HOTA、79.5IDF1和79.6MOTA(7.1 Hz),在MOT20测试集上达到62.6HOTA、77.0IDF1和73.8MOTA(1.4 Hz)。图1将我们的StrongSORT和StrongSORT++与MOT17和MOT20测试集上最先进的跟踪器进行了比较。我们的方法获得了最好的IDF1和HOTA,并且获得了与MOTA相当的性能。此外,AFLink和GSI分别在MOT17上运行591.9 Hz和140.9 Hz,在MOT20上运行224.0 Hz和17.6 Hz,导致计算量可以忽略不计。
The contributions of our work are summarized as follows:
- We revisit the classic seperate tracker DeepSORT and improve it from various aspects, resulting in StrongSORT, which sets new HOTA and IDF1 records on MOT17 and MOT20 datasets.
- We propose two lightweight and appearance-free algorithms, AFLink andGSI, which can be plugged into various trackers to improve their performanceby a large margin.
- By integrating StrongSORT with AFLink and GSI, our StrongSORT++ ranks first on MOT17 and MOT20 in terms of widely used HOTA and IDF1metrics and surpasses the second-place one [73] by 1.3 - 2.2.
本文的主要工作如下:
-
对经典的独立跟踪器DeepSORT进行了改进,提出了在MOT17和MOT20数据集上达到新的HOTA和IDF1记录的StrongSORT算法;
-
提出了AFLink和GSI两种轻量级、appearance-free的跟踪算法,可以嵌入到各种跟踪器中,大大提高了跟踪性能;
-
通过将StrongSORT与AFLink和GSI集成,在广泛使用的HOTA和IDF1指标方面,我们的StrongSORT++在MOT17和MOT20中排名第一,并以1.3-2.2的优势超过第二名[73]。
2 Related Work
2.1 Seperate and Joint Trackers
MOT methods can be classified as seperate and joint trackers. Seperate trackers[3,4,7,8,15,36,62,69] follow the tracking-by-detection paradigm and localize targets first and then associate them with information on appearance, motion, etc. Benefiting from the rapid development of object detection [17, 42, 43, 52, 53, 78],seperate trackers have dominated the MOT task for years. Recently, severaljoint trackers [30, 32, 38, 57, 59, 65, 68] have been proposed to train detection andsome other components jointly, e.g., motion, embedding and association models.The main benefit of these trackers is their low computational cost and comparable performance. However, we claim that joint trackers face two major problems: competition between different components and limited data for training the components jointly. The two problems limit the upper bound of tracking accuracy.Therefore, we argue that the tracking-by-detection paradigm is still the optimal solution for tracking performance.
MOT方法可分为单独跟踪器和联合跟踪器。独立跟踪器[3,4,7,8,15,36,62,69]遵循先检测后跟踪的范式,首先定位目标,然后将它们与外观、运动等信息相关联,得益于目标检测的快速发展[17,42,43,52,53,78],独立跟踪器多年来一直主导着MOT任务。最近,人们提出了几种联合跟踪器[30,32,38,57,59,65,68]来联合训练检测和其他一些组件,如运动、嵌入和关联模型,这些跟踪器的主要优点是计算成本低,性能相当。然而,我们声明联合跟踪器面临两大问题:不同组件之间的竞争,有限的数据用于训练联合组件。这两个问题限制了跟踪精度的上限,因此,我们认为tracking-by-detection仍然是跟踪性能的最佳解决方案。
Meanwhile, several recent studies [48, 49, 73] have abandoned appearance information and relied only on high-performance detectors and motion information, which achieve high running speed and state-of-the-art performance on MOTChallenge benchmarks [11,35]. However, we argue that it’s partly due to the general simplicity of motion patterns in these datasets. Abandoning appearance features would lead to poor robustness in more complex scenes. In this paper, we adopt the DeepSORT-like [62] paradigm and equip it with advanced techniques from various aspects to confirm the effectiveness of this classic framework.
同时,最近的一些研究[48,49,73]已经放弃了外观信息,而只依赖于高性能的检测器和运动信息,它们在MOT挑战基准上获得了高运行速度和最先进的性能[11,35]。然而,我们认为这在一定程度上是由于这些数据集中运动模式的普遍简单性。在更复杂的场景中,放弃外观特征会导致较差的鲁棒性。本文采用类DeepSORT[62]范式,并从各个方面为其配备了先进的技术,以证实这一经典框架的有效性。
2.2 Global Link in MOT
To exploit rich global information, several methods refine the tracking results with a global link model [12, 39, 55, 56, 67]. They tend to generate accurate but incomplete tracklets by using spatio-temporal and/or appearance information first. Then, these tracklets are linked by exploring global information in an offline manner. TNT [56] designs a multi-scale TrackletNet to measure the connectivity between two tracklets. It encodes motion and appearance informationin a unified network by using multi-scale convolution kernels. TPM [39] presents a tracklet-plane matching process to push easily confusable tracklets into different tracklet-planes, which helps reduce the confusion in the tracklet matching step. ReMOT [67] is improved from ReMOTS [66]. Given any tracking results, ReMOT splits imperfect trajectories into tracklets and then merges them with appearance features. GIAOTracker [12] proposes a complex global link algorithm that encodes tracklet appearance features by using an improved ResNet50-TP model [16] and associates tracklets together with spatial and temporal costs. Although these methods yield notable improvements, they all rely on appearance features, which bring high computational cost. Differently, we propose the AFLink model that only exploits motion information to predict the link confidence between two tracklets. By designing an appropriate model framework and training process, AFLink benefits various state-of-the-art trackers with a negligible extra cost. To the best of our knowledge, this is the first appearance-freeand lightweight global link model for the MOT task.
为了利用丰富的全局信息,几种方法使用全局链接模型[12,39,55,56,67]来改进跟踪结果。他们倾向于通过首先使用时空和/或外观信息来生成准确但不完整的轨迹。然后,通过以一种灵活的方式探索全局信息,将这些轨迹链接起来。TNT[56]设计了一个多尺度TrackletNet来测量两个轨道之间的连通性。它利用多尺度卷积核在统一的网络中对运动和外观信息进行编码。TPM[39]提出了一种轨迹-平面匹配过程,将容易混淆的轨迹推送到不同的轨迹-平面中,这有助于减少轨迹匹配步骤中的混淆。ReMOT[67]是从ReMOTS[66]改进的。给定任何跟踪结果,ReMOT都会将不完美的轨迹拆分成tracklet,然后将它们与外观特征合并。GIAOTracker[12]提出了一种复杂的全局链接算法,该算法使用改进的ResNet50-TP模型[16]对轨迹块外观特征进行编码,并将轨迹块与空间和时间代价相关联,虽然这些方法都取得了显著的改进,但都依赖于外观特征,带来了较高的计算代价。不同的是,我们提出了AFLink模型,该模型只利用运动信息来预测两个轨迹之间的链接概率。通过设计合适的模型框架和训练过程,AFLink 以微不足道的额外成本使各种最先进的跟踪器受益。据我们所知,这是MOT任务的第一个外观自由和轻量级的全局链接模型。
2.3 Interpolation in MOT
Linear interpolation is widely used to fill the gaps of recovered trajectories for missing detections [12, 21, 37, 40, 41, 73]. Despite its simplicity and effectiveness,linear interpolation ignores motion information, which limits the accuracy of the restored bounding boxes. To solve this problem, several strategies have been proposed to utilize spatio-temporal information effectively. V-IOUTracker [5]extends IOUTracker [4] by falling back to single-object tracking [20, 25] while missing detection occurs. MAT [19] smooths the linearly interpolated trajectories nonlinearly by adopting a cyclic pseudo-observation trajectory filling strategy. An extra camera motion compensation (CMC) model [14] and Kalman filter [26]are needed to predict missing positions. MAATrack [49] simplifies it by applying only the CMC model. All these methods apply extra models, i.e., single-objecttracker, CMC, Kalman filter, in exchange for performance gains. Instead, we propose to model nonlinear motion on the basis of the Gaussian process regression(GPR) algorithm [61]. Without additional time-consuming components, our pro-posed GSI algorithm achieves a good trade-off between accuracy and efficiency.
线性插值被广泛用于填补形成检测的恢复轨迹的空白[12,21,37,40,41,73]。尽管线性插值简单有效,但它忽略了运动信息,这限制了存储的边界框的精度。为了解决这一问题,人们提出了几种有效利用时空信息的策略。V-IOUTracker 扩展了 IOUTracker,在发生漏检时回退到单目标跟踪。MAT [19]采用循环伪观测轨迹填充策略对线性插值轨迹进行非线性平滑。需要额外的相机运动补偿模型[14]和卡尔曼过滤[26]来预测丢失位置。MAATrack[49]通过只应用CMC模型简化了它。所有这些方法都使用额外的模型,即单对象跟踪器、CMC法、卡尔曼过滤法,以换取性能的提高。相反,我们建议在高斯过程回归(GPR)算法的基础上对非线性运动进行建模[61]。在不增加额外耗时组件的情况下,我们提出的GSI算法在精度和效率之间取得了很好的折衷。

Fig. 2. Framework and performance comparison between DeepSORT and Strong-SORT. Performance is evaluated on the MOT17 validation set based on detectionspredicted by YOLOX [17].
图2.DeepSORT和Strong-Sort的结构和性能比较。基于YOLOX[17]预测的检测,在MOT17验证集上评估性能。
The most similar work with our GSI is [79], which uses the GPR algorithm to smooth the uninterpolated tracklets for accurate velocity predictions. How-ever, it works for the event detection task in surveillance videos. Differently, westudy on the MOT task and adopt GPR to refine the interpolated localizations.Moreover, we present an adaptive smoothness factor, instead of presetting ahyperparameter like [79].
与我们的 GSI 最相似的工作是 [79],它使用 GPR 算法来平滑未插值的轨迹,以进行准确的速度预测。但是,它适用于监控视频中的事件检测任务。不同的是,我们对 MOT 任务进行了研究,并采用 GPR 来改进插值定位。此外,我们提出了一个自适应平滑因子,而不是像 [79] 那样预设超参数。
3 StrongSORT
In this section, we present various approaches to improve the classic tracker DeepSORT [62]. Specifically, we review DeepSORT in Section 3.1 and introduce StrongSORT in Section 3.2. Notably, we do not claim any algorithmic novelty in this section. Instead, our contributions here lie in giving a clear understanding of DeepSORT and equipping it with various advanced techniques to prove the effectiveness of its paradigm.
在本节中,我们将介绍改进经典trackerDeepSORT[62]的各种方法。具体地说,我们在3.1节中回顾了DeepSORT,并在3.2节中介绍了StrongSORT。值得注意的是,我们在这一节中没有声称有任何算法新颖性。相反,我们在这里的贡献在于对DeepSORT有了一个清晰的理解,并为其配备了各种先进的技术来证明其范式的有效性。
3.1 Review of DeepSORT
We briefly summarize DeepSORT as a two-branch framework, that is, appearance branch and motion branch, as shown in the top half of Figure 2
我们简要地将DeepSORT概括为一个由两个分支组成的框架,即外观分支和运动分支,如图2的上半部分所示
In the appearance branch, given detections in each frame, the deep appearance descriptor (a simple CNN), which is pretrained on the person re-identification dataset MARS [75], is applied to extract their appearance features.It utilizes a feature bank mechanism to store the features of the last 100 frames for each tracklet. As new detections come, the smallest cosine distance between the feature bank R i R_i Ri of the i i i-th tracklet and the feature f j f_j fj of the j j j-th detectionis computed as
在外观分支中,给定每一帧中的检测,应用在行人重识别数据集MARS[75]上预训练的深度外观描述符(一种简单的CNN)来提取其外观特征,并利用feature bank机制来存储每条轨迹的最后100帧的特征。随着新检测的到来,第i个轨道小程序的feature bank R i R_i Ri 和第 j j j个检测的特征 f j f_j fj之间的最小余弦距离被计算为
d ( i , j ) = min 1 − f j T f k ( i ) ∣ f k ( i ) ∈ R i ( 1 ) d(i,j)=\min{1-f_j^Tf_k^{(i)}|f_k^{(i)}\in R_i} \ \ \ \ (1) d(i,j)=min1−fjTfk(i)∣fk(i)∈Ri (1)
The distance is used as the matching cost during the association procedure.
在关联过程中,将距离作为匹配代价。
In the motion branch, the Kalman filter algorithm [26] accounts for predicting the positions of tracklets in the current frame. Then, Mahalanobis distance is used to measure the spatio-temporal dissimilarity between tracklets and detections. DeepSORT takes this motion distance as a gate to filter out unlikely associations.
在运动分支中,卡尔曼过滤算法[26]负责预测当前帧中轨迹的位置。然后,利用马氏距离来度量轨迹和目标之间的时空差异性。DeepSORT以此运动距离为阀来过滤排除不可能的关联。
Afterwards, the matching cascade algorithm is proposed to solve the association task as a series of subproblems instead of a global assignment problem. The core idea is to give greater matching priority to more frequently seen objects. Each association subproblem is solved using the Hungarian algorithm [29].
然后提出匹配级联算法将关联任务作为一系列子问题来求解,而不是全局分配问题。其核心思想是赋予更频繁出现的对象更高的匹配优先级,每个关联子问题都使用匈牙利算法[29]来求解。
3.2 Stronger DeepSORT
Our improvements over DeepSORT lie mainly in the two branches, as shown in the bottom half of Figure 2. For the appearance branch, a stronger appearance feature extractor, BoT [34], is applied to replace the original simple CNN. By taking ResNeSt50 [71] as the backbone and pretraining on the DukeMTMC-reID [44] dataset, it can extract much more discriminative features. In addition,we replace the feature bank with the feature updating strategy proposed in[60], which updates appearance state e i t e_i^t eit for the i i i-th tracklet at frame t t t in an exponential moving average (EMA) manner as follows:
我们对DeepSORT的改进主要体现在两个分支上,如图2的下半部分所示。对于外观分支,应用了更强大的外观特征提取器BOT[34]来取代原来简单的CNN。该算法以ResNeSt50[71]为主干,在DukeMTMC-Reid[44]数据集上进行预训练,可以提取更具区分性的特征。此外,我们用[60]中提出的特征更新策略替换了特征库,该策略以指数移动平均(EMA)的方式更新帧 t t t处第 i i i个轨迹的外观状态 e i t e_i^t eit ,如下所示:
e i t = α e i t − 1 + ( 1 − α ) f i t ( 2 ) e_i^t=\alpha e_i^{t-1}+(1-\alpha)f_i^t \ \ \ \ (2) eit=αeit−1+(1−α)fit (2)
where f i t f_i^t fit is the appearance embedding of the current matched detection and α \alpha α = 0.9 is a momentum term. The EMA updating strategy not only enhances the matching quality, but also reduces the time consumption.
其中, f i t f_i^t fit 是当前匹配检测的外观嵌入,并且 α \alpha α = 0.9 是动量项。EMA更新策略不仅提高了匹配质量,而且减少了时间消耗。
For the motion branch, similar to [19, 27, 49], we adopt ECC [14] for cameramotion compensation. Furthermore, the vanilla Kalman filter is vulnerable w.r.t. low-quality detections [49] and ignores the information on the scales of detection noise. To solve this problem, we borrow the NSA Kalman algorithm from [12]that proposes a formula to adaptively calculate the noise covariance R ~ k \widetilde{R}_k R k:
对于运动分支,类似于[19,27,49],我们采用ECC[14]进行摄像机运动补偿。此外,普通卡尔曼滤波很容易受到低质量检测的攻击[49],并且忽略了检测噪声尺度上的信息。为了解决这个问题,我们借用了[12]中的NSA卡尔曼算法,提出了一个自适应计算噪声协方差 R ~ k \widetilde{R}_k R k的公式:
R ~ k = ( 1 − c k ) R k ( 3 ) \widetilde{R}_k=(1-c_k)R_k \ \ \ \ (3) R k=(1−ck)Rk (3)
where R k R_k Rk is the preset constant measurement noise covariance and c k c_k ck is the detection confidence score at state k k k . Furthermore, instead of employing only the appearance feature distance dur-ing matching, we solve the assignment problem with both appearance and motioninformation, similar to [60]. Cost matrix C C C is a weighted sum of appearance cost A a A_a Aa and motion cost A m A_m Am as follows:
其中 R k R_k Rk是预先设定的常量测噪声协方差, c k c_k ck是状态 k k k下的检测置信度分数,并且在匹配过程中不再只使用外观特征距离,而是同时考虑外观和运动信息,类似于[60]。成本矩阵 C C C是外观成本 A a A_a Aa和动作成本 A m A_m Am的加权和,如下所示:
C = λ A a + ( 1 − λ ) A m ( 4 ) C = \lambda A_a+(1-\lambda)A_m\ \ \ \ (4) C=λAa+(1−λ)Am (4)
where weight factor λ \lambda λ is set to 0.98. Another interesting finding is that although the matching cascade algorithm is not trivial in DeepSORT, it limits the performance as the tracker becomes more powerful. The reason is that as the trackerbecomes stronger, it becomes more robust to confusable associations. Therefore, additional prior constraints would limit the matching accuracy. We replace matching cascade with vanilla global linear assignment.
其中,权重因子λ设置为0.98.另一个有趣的发现是,虽然匹配级联算法在DeepSORT中不是微不足道的,但随着跟踪器变得更强大,它限制了性能。原因是,随着跟踪器变得更强大,它对容易混淆的关联也变得更加健壮。因此,附加的先验约束会限制匹配精度。我们用普通的全局线性分配来代替匹配级联(matching cascade)。
4 StrongSORT++
We presented a strong tracker in Section 3. In this section, we introduce twolightweight, plug-and-play, model-independent, appearance-free algorithms, namelyAFLink and GSI, to further refine the tracking results. We call the final methodStrongSORT++, which integrates StrongSORT with the two algorithms.
我们在第三节介绍了一个强大的跟踪器。在这一节中,我们介绍了两种轻量级、即插即用、模型无关、外观无关的算法,命名为AFLink和GSI,以进一步完善跟踪结果。我们称最终的方法为StrongSORT++,它集成了StrongSORT和这两种算法。
4.1 AFLink
The global link for tracklets is used in several works to pursue highly accurate associations. However, they generally rely on computationally expensive components and numerous hyperparameters to fine-tune. For example, the link algorithm in GIAOTracker [12] utilizes an improved ResNet50-TP [16] to extract tracklets 3D features and performs association with additional spatial andtemporal distances. This means 6 hyperparameters (3 thresholds and 3 weight factors) are to be fine-tuned, which incurs additional tuning experiments and poor robustness. Moreover, we find that over-reliance on appearance featuresis vulnerable to noise. Motivated by this, we design an appearance-free model, AFLink, to predict the connectivity between two tracklets by relying only on spatio-temporal information.
Tracklet的全局链接在几个works中使用,以追求高准确率的关联。然而,它们通常依赖于计算昂贵的组件和大量的超参数来微调。例如,GIAOTracker[12]中的链接算法利用改进的ResNet50-TP[16]来提取Tracklet 3D特征,并执行与附加的空间和时间距离的关联。这意味着需要微调6个超参数(3个阈值和3个权重因子),这会带来额外的调整实验,并且鲁棒性很差。此外,我们发现过度依赖外观特征很容易受到噪声的影响。受此启发,我们设计了一个appearance-free的模型,AFLink,仅依靠时空信息预测两个tracklet之间的连通性。

Fig. 3. Framework of the AFLink model. It adopts the spatio-temporal information of two tracklets as the input and then predicts their connectivity.
图3.AFLink模型的框架。它采用两个轨迹的时空信息作为输入,然后预测它们的连通性。
Figure 3 shows the two-branch framework of the AFLink model. It adopts two tracklets T i T_i Ti and T j T_j Tj as the input, where T ∗ = { f k , x k , y k } k = 1 N T_∗ = \{f_k,x_k,y_k\}^N_{k=1} T∗={fk,xk,yk}k=1N consists of theframes f k f_k fk and positions ( x k x_k xk, y k y_k yk) of the recent N N N = 30 frames. Zero padding is used for those shorter than 30 frames. A temporal module is applied to extract features by convolving along the temporal dimension with 7×1 kernels. Then,a fusion module performs 1×3 convolutions to integrate the information from different feature dimensions, namely f f f, x x x and y y y. The two resulting feature mapsare pooled and squeezed to feature vectors respectively, and then concatenated,which includes rich spatio-temporal information. Finally, an MLP is used topredict a confidence score for association. Note that the temporal module andfusion module of the two branches are not tied.
图3显示了AFLink模型的两个分支框架。它采用两个轨迹 T i T_i Ti 和 T j T_j Tj 作为输入,其中 T ∗ = { f k , x k , y k } k = 1 N T_∗ = \{f_k,x_k,y_k\}^N_{k=1} T∗={fk,xk,yk}k=1N 由最近 N N N = 30 帧的帧 f k f_k fk和位置( x k x_k xk, y k y_k yk) 组成。零填充用于短于30帧的图像。特征提取采用时间模块,沿时间维度与7×1个核进行卷积。然后,融合模块对来自不同特征维数 f f f, x x x 和 y y y的信息进行1×3卷积,将得到的两个特征映射分别合并和压缩成特征向量,然后进行拼接,包含丰富的时空信息。最后,使用MLP来判断关联的置信度分数。请注意,两个分支的时态模块和融合模块没有绑定。
During association, we filter out unreasonable tracklet pairs with spatio-temporal constraints. Then, the global link is solved as a linear assignment task[29] with the predicted connectivity score.
在关联过程中,我们过滤出具有时空约束的不合理轨迹对。然后,将全局链路求解为具有预测连通性分数的线性分配任务[29]。
4.2 GSI
Interpolation is widely used to fill the gaps in trajectories caused by missing detections. Linear interpolation is highly popular due to its simplicity. However, its accuracy is limited because it does not use motion information. Although several strategies have been proposed to solve this problem, they generally introduce additional time-consuming modules, e.g., single-object tracker, Kalmanfilter, ECC. Differently, we present a lightweight interpolation algorithm that employs Gaussian process regression [61] to model nonlinear motion.
插值被广泛地用来填补因漏检而造成的轨迹空白。线性插值因其简单性而广受欢迎。但是,由于没有使用运动信息,其精度受到限制。虽然已经提出了几种策略来解决这一问题,但通常都会引入额外的耗时模块,如单目标跟踪器、卡尔曼滤波器、纠错码等。不同的是,我们提出了一种轻量级的插值算法,它使用高斯过程回归[61]来建模非线性运动。
We formulate the GSI model for the i i i-th trajectory as follows:
我们将 i i i-th轨迹的GSI模型表示如下:
p t = f ( i ) ( t ) + ϵ ( 5 ) p_t=f^{(i)}(t)+\epsilon \ \ \ \ (5) pt=f(i)(t)+ϵ (5)
where t ∈ F t \in F t∈F is the frame, p t ∈ P p_t \in P pt∈P is the position coordinate variate at frame t t t (i.e., x , y , w , h x,y,w,h x,y,w,h) and ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim N(0,σ^2) ϵ∼N(0,σ2) is Gaussian noise. Given tracked and linearly interpolated trajectories S ( i ) = { t ( i ) , p t ( i ) } t = 1 L S^{(i)} = \{t^{(i)},p_t^{(i)}\}_{t=1}^L S(i)={t(i),pt(i)}t=1L with length L L L, the task of nonlinear motion modeling is solved by fitting the function f ( i ) f^{(i)} f(i).We assume that it obeys a Gaussian process f ( i ) ∈ G P ( 0 , k ( ⋅ , ⋅ ) ) f^{(i)} \in GP(0,k(·,·)) f(i)∈GP(0,k(⋅,⋅)), where k ( x , x ′ ) = e x p ( − ∥ x − x ′ ∥ 2 2 λ 2 ) k(x,x′) =exp(−\frac{\|x-x'\|^2}{2\lambda^2} ) k(x,x′)=exp(−2λ2∥x−x′∥2)is a radial basis function kernel. On the basis of the properties of the Gaussian process, given new frame set F ∗ F^* F∗,its smoothed positions P ∗ P^∗ P∗ is predicted by
其中 t ∈ F t \in F t∈F 是帧, p t ∈ P p_t \in P pt∈P 是帧 t t t处的位置坐标变量(即 x , y , w , h x,y,w,h x,y,w,h),并且 ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim N(0,σ^2) ϵ∼N(0,σ2)是高斯噪声。给定长度为 L L L的轨迹 S ( i ) = { t ( i ) , p t ( i ) } t = 1 L S^{(i)} = \{t^{(i)},p_t^{(i)}\}_{t=1}^L S(i)={t(i),pt(i)}t=1L ,通过拟合函数 f ( i ) f^{(i)} f(i)来解决非线性运动建模问题,假设其服从高斯过程 f ( i ) ∈ G P ( 0 , k ( ⋅ , ⋅ ) ) f^{(i)} \in GP(0,k(·,·)) f(i)∈GP(0,k(⋅,⋅)),其中 k ( x , x ′ ) = e x p ( − ∥ x − x ′ ∥ 2 2 λ 2 ) k(x,x′) =exp(−\frac{\|x-x'\|^2}{2\lambda^2} ) k(x,x′)=exp(−2λ2∥x−x′∥2)是径向基函数。根据高斯过程的性质,在给定新的帧集 F ∗ F^* F∗的情况下,对其平滑位置 P ∗ P^∗ P∗ 进行了预测
P ∗ = K ( F ∗ , F ) ( K ( F , F ) + σ 2 I ) − 1 P ( 6 ) P^*=K(F^*,F)(K(F,F)+\sigma^2I)^{-1}P \ \ \ \ (6) P∗=K(F∗,F)(K(F,F)+σ2I)−1P (6)
where K ( ⋅ , ⋅ ) K(·,·) K(⋅,⋅) is a covariance function based on k ( ⋅ , ⋅ ) k(·,·) k(⋅,⋅). Moreover, hyperparameter λ \lambda λ controls the smoothness of the trajectory, which should be related with its length. We simply design it as a function adaptive to length l l l as follows:
其中 K ( ⋅ , ⋅ ) K(·,·) K(⋅,⋅)是基于 k ( ⋅ , ⋅ ) k(·,·) k(⋅,⋅)的协方差函数。此外,超参数 λ \lambda λ控制着轨迹的平滑度,这应该与其长度有关。我们简单地将其设计为与长度 l l l相适应的函数,如下所示:
λ = τ ∗ log ( τ 3 / l ) ( 7 ) \lambda = \tau * \log(\tau ^3/l) \ \ \ \ (7) λ=τ∗log(τ3/l) (7)
where τ \tau τ is set to 10.
τ \tau τ设置为10。
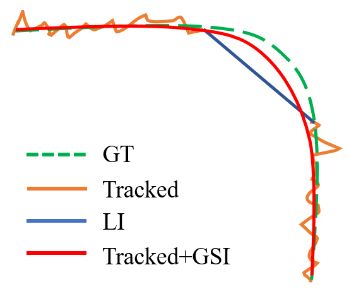
Fig. 4. Illustration of the difference between linear interpolation(LI) and the proposed Gaussian-smoothed interpolation (GSI).
图4.说明线性插值(LI)和提出的高斯平滑插值(GSI)之间的区别。
Figure 4 illustrates an example of the difference between GSI and linear interpolation ( L I LI LI). The raw tracked results (in orange) generally include noisy jitter, and L I LI LI(in blue) ignores motion information. Our GSI (in red) solve both problems simultaneously by smoothing the entire trajectory with an adaptive smoothness factor.
图4举例说明了GSI和线性插值( L I LI LI)之间的区别。原始跟踪结果(橙色)通常包括噪波抖动,而 L I LI LI(蓝色)忽略运动信息。我们的GSI(红色)通过使用自适应平滑度因子平滑整个轨迹,同时解决了这两个问题。
5 Experiments
5.1 Datasets and Evaluation Metrics
Datasets. We conduct experiments on MOT17 [35] and MOT20 [11] datasets under the ”private detection” protocol. MOT17 is a popular dataset for MOT, which consists of 7 sequences, 5316 frames for training and 7 sequences, 5919 frames for testing. MOT20 is set for highly crowded challenging scenes, with 4 sequences, 8,931 frames for training and 4 sequences, 4,479 frames for testing. For ablation studies, we take the first half of each sequence in the MOT17 training set for training and the last half for validation following [73, 77]. Weuse DukeMTMC [44] to pretrain our appearance feature extractor. We trainthe detector on the CrowdHuman dataset [46] and MOT17 half training set forablation following [50, 63, 70, 73, 77]. We add Cityperson [72] and ETHZ [13] fortesting as in [30, 60, 73, 74].
数据集。在“私有检测”协议下,我们在MOT17[35]和MOT20[11]数据集上进行了实验。MOT17是目前流行的MOT数据集,它包含7个序列5316帧用于训练,7个序列5919帧用于测试。MOT20是为高度拥挤的挑战性场景设置的,有4个序列8931帧用于训练,4个序列4479帧用于测试,对于消融研究,我们取MOT17训练集中每个序列的前一半用于训练,后半部分用于验证[73,77]。我们使用DukeMTMC[44]来预先训练我们的外观特征提取器。我们在CrowdHuman数据集[46]和MOT17半训练集上训练检测器,以便在[50,63,70,73,77]之后进行消融。我们添加CityPerson[72]和ETHZ[13]用于测试,如[30,60,73,74]。
Metrics. We use the metrics MOTA, IDs, IDF1, HOTA, AssA, DetA and FPS to evaluate tracking performance [2, 33, 44]. MOTA is computed based on FP,FN and IDs, and focuses more on detection performance. By comparison, IDF1better measures the consistency of ID matching [23]. HOTA is an explicit com-bination of detection score DetA and association score AssA, which balancesthe effects of performing accurate detection and association into a single unified metric. Moreover, it evaluates at a number of different distinct detection similarity values (0.05 to 0.95 in 0.05 intervals) between predicted and GT bounding boxes, instead of setting a single value (i.e., 0.5) like MOTA and IDF1, and better takes localization accuracy into account.
评估。我们使用度量MOTA、IDS、IDF1、HOTA、ASSA、DETA和FPS来评估跟踪性能[2,33,44]。MOTA是基于FP、FN和ID计算的,更关注检测性能。相比之下,IDF1更好地衡量ID匹配的一致性[23]。HOTA是检测分数DATA和关联分数ASSA的显式组合,它将精确检测和关联的效果平衡到单一的统一度量中。此外,它不像MOTA和IDF1那样设置单一的值(即0.5),而是在预测和GT边界框之间以不同的检测相似度值(0.05到0.95在0.05的间隔内)进行评估,并且更好地考虑了定位精度。
5.2 Implementation Details
For detection, we adopt YOLOX-X [17] pretrained on COCO [31] as our detectorfor an improved time-accuracy trade-off. The training schedule is similar to that in [73]. In inference, a threshold of 0.8 is set for non-maximum suppression (NMS)and a threshold of 0.6 for detection confidence. For StrongSORT, the featuredistance threshold is 0.45, the warp mode for ECC is MOTION EUCLIDEAN, the momentum term α in EMA is 0.9 and the weight factor for appearance cost λ is 0.98. For GSI, the maximum gap allowed for interpolation is 20 frames, and hyperparameter τ \tau τ is 10.
对于检测,我们采用在COCO[31]上预训练的YOLOX-X[17]作为我们的检测器,以提高时间精度。训练与[73]中的类似。在推理中,将非最大抑制(NMS)的阈值设置为0.8,将检测置信度的阈值设置为0.6。对于StrongSORT,特征距离阈值为0.45,ECC的翘曲模式为运动欧几里得,均线方程中的动量项α为0.9,外观成本λ的权重因子为0.98。对于GSI,允许插值的最大间隙是20帧,超参数 τ \tau τ是10。
For AFLink, the temporal module consists of four convolution layers with 7×1 kernels and {32,64,128,256} output channels. Each convolution is followed by a BN layer [24] and a ReLU activation layer [18]. The fusion module includes a 1×3 convolution, a BN and a ReLU. It doesn’t change the number of channels. The classifier is an MLP with two fully connected layers and a ReLU layer inserted in between. The training data are generated by cutting annotated trajectories into tracklets with random spatio-temporal noise at a 1:3 ratio of positive andnegative samples. We use Adam as the optimizer [28], cross-entropy loss as the objective function and train it for 20 epochs with a cosine annealing learning rate schedule. The overall training process takes just over 10 seconds. In inference,a temporal distance threshold of 30 frames and a spatial distance thresholdof 75 pixels are used to filter out unreasonable association pairs. Finally, theassociation is considered if its prediction score is larger than 0.95.
对于AFLink,时间模块由4个卷积层组成,具有7×1个内核和{32,64,128,256}个输出通道。每个卷积之后是BN层[24]和RELU激活层[18]。融合模块包括1×3卷积、BN和REU。它不会改变频道的数量。该分类器是具有两个全连接层和插入其间的RELU层的MLP。训练数据是通过以1:3的正负样本比率将带注释的轨迹切割成具有随机时空噪声的轨迹来生成的。我们使用Adam作为优化器[28],以交叉熵损失为目标函数,并用余弦退火学习率调度对其进行了20个周期的训练。整个训练过程仅需10秒多一点。在推理中,时间距离阈值为30帧,空间距离阈值为75像素,用于过滤提取不合理的关联对。最后,如果关联性的预测得分大于0.95,则考虑该关联性。
5.3 Ablation Studies

Albation study for StrongSORT. Table 1 summarizes the path from DeepSORT to StrongSORT:
StrongSORT的消融研究。表1总结了从DeepSORT到StrongSORT的路径:
-
BoT: Replacing the original feature extractor with BoT leads to a signif-icant improvement for IDF1, indicating that association quality benefits from more discriminative appearance features.
BOT:用BOT替换原来的特征提取器导致IDF1的显著改善,表明关联质量受益于更具区分性的外观特征。
-
ECC: The CMC model results in a slight increase in IDF1 and MOTA, implying that it helps extract more precise motion information.
ECC:CMC模型导致IDF1和MOTA略有增加,这意味着它有助于提取更精确的运动信息。a
-
NSA: The NSA Kalman filter improves HOTA but not MOTA and IDF1.This means it enhances positioning accuracy.
NSA:NSA卡尔曼滤波改善了HOTA,但没有改善MOTA和IDF1。这意味着它提高了定位精度。
-
EMA: The EMA feature updating mechanism brings not only superior association, but also faster speed.
EMA:EMA特征更新机制不仅带来了更好的关联性,而且速度更快。
-
MC: Matching with both appearance and motion cost aids association.
MC:与外观和动作成本辅助关联都匹配。
-
woC: For the stronger tracker, the matching cascade algorithm with re-dundant prior information limits the tracking accuracy. By simply employing avanilla matching method, IDF1 is improved by a large margin.
woC:对于较强的跟踪器,具有冗余先验信息的匹配级联算法限制了跟踪精度。通过简单地采用avanilla匹配方法,IDF1得到了较大幅度的改善。
Ablation study for AFLink and GSI. We apply AFLink and GSI on six different trackers, i.e., three versions of StrongSORT and three state-of-the-art trackers (CenterTrack [77], TransTrack [50] and FairMOT [74]). Their resultsare shown in Table 2. The first line of the results for each tracker is the originalperformance. The application of AFLink (the second line) brings different levels of improvement for the different trackers. Specifically, poorer trackers tend tobenefit more from AFLink due to more missing associations. Particularly, theIDF1 of CenterTrack is improved by 3.7. The third line of the results for eachtracker proves the effectiveness of GSI for both detection and association. Differ-ent from AFLink, GSI works better on stronger trackers. It would be confusedby the large amount of false association in poor trackers. Table 3 compares ourGSI with LI. The results show that GSI yields better performance with a littleextra computational cost.
AFLink和GSI的消融研究。我们在六个不同的跟踪器上应用AFLink和GSI,即三个版本的StrongSORT和三个最先进的跟踪器(CenterTrack[77]、Transtrack[50]和FairMOT[74])。它们的结果如表2所示。每个跟踪器的结果的第一行是原始性能。AFLink(第二行)的应用为不同的跟踪器带来了不同程度的改进。具体地说,由于更多的关联缺失,表现较差的跟踪者往往从AFLink中获益更多。特别是,CenterTrack的IDF1改进了3.7。每个跟踪器的第三行结果证明了GSI对于检测和关联的有效性。与AFLink不同的是,GSI在更强大的追踪器上工作得更好。它会被糟糕的跟踪器中的大量错误关联所迷惑。表3将我们的GSI与LI进行了比较。结果表明,GSI算法以较小的额外计算量获得了较好的性能。


5.4 MOTChallenge Results
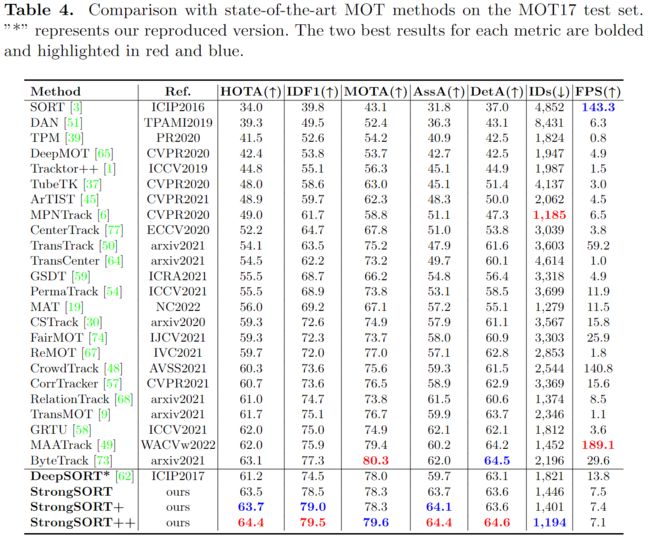
We compare StrongSORT, StrongSORT+ (StrongSORT+AFLink) and Strong-SORT++ (StrongSORT+AFLink+GSI) with state-of-the-art trackers on the test sets of MOT17 and MOT20, as shown in Tables 4 and 5, respectively. Notably, comparing FPS with absolute fairness is difficult because the speedclaimed by each method depends on the devices where they are implemented,and the time spent on detections is generally excluded for tracking-by-detectiontrackers.
我们将StrongSORT,StrongSORT+(StrongSORT+AFLink)和StrongSORT++(StrongSORT+AFLink+GSI)分别在MOT17和MOT20的测试集上与最先进的跟踪器进行了比较,如表4和表5所示,值得注意的是,比较FPS具有绝对公平性是困难的,因为每种方法要求的速度取决于它们实现的设备,并且跟踪检测所花费的时间通常被排除在外。
MOT17. StrongSORT++ ranks first among all published methods on MOT17for metrics HOTA, IDF1, AssA, DetA, and ranks second for MOTA, IDs. In particular, it yields an accurate association and outperforms the second-performancetracker by a large margin (i.e., +2.2 IDF1 and +2.4 AssA). We use the same hyperparameters as in the ablation study and do not carefully tune them foreach sequence like in [73]. The steady improvements on the test set prove the robustness of our methods. It is worth noting that, our reproduced version of DeepSORT (with a stronger detector and several tuned hyperparameters) also performs well on the benchmark, which demonstrates the effectiveness of the DeepSORT-like tracking paradigm.
MOT17。对于HOTA、IDF1、ASA、DETA等指标,StrongSORT++在MOT17发布的所有方法中排名第一,在MOTA、IDS方面排名第二。与之相比,它产生了准确的关联,并大大超过了第二性能的tracker(即+2.2IDF1和+2.4ASSA)。我们使用与消融研究中相同的超参数,并且不像在[73]中那样在每个序列中仔细地调整它们。在测试集上的稳步改进证明了我们方法的有效性。值得注意的是,我们复制的DeepSORT版本(具有更强大的检测器和几个可调的超参数)也在基准测试中运行良好,这证明了类似DeepSORT的跟踪范例的有效性。
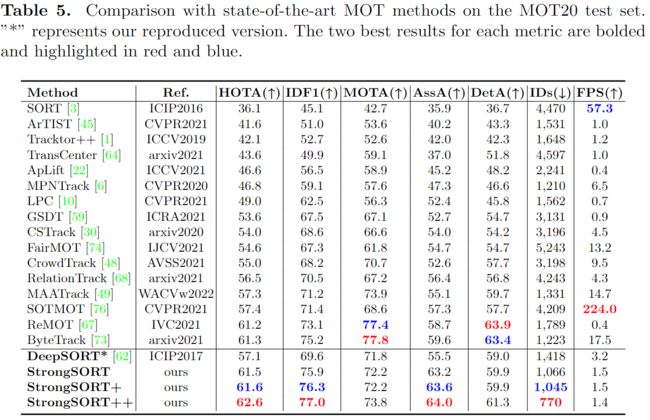
MOT20. MOT20 is from more crowded scenarios. High occlusion means a highrisk of missing detections and associations. StrongSORT++ still ranks first formetrics HOTA, IDF1 and AssA. It achieves significantly less IDs than the othertrackers. Note that we use exactly the same hyperparameters as in MOT17,which implies the generalization capability of our method. Its detection per-formance (MOTA and DetA) is slightly poor compared with that of severaltrackers. We think this is beacuse we use the same detection score threshold asin MOT17, which results in many missing detections. Specifically, the metric FN(number of false negatives) of our StrongSORT++ is 117,920, whereas that ofByteTrack [73] is only 87,594.
MOT20。MOT20来自更拥挤的场景。高度遮挡意味着遗漏检测和关联的高风险。StrongSORT++仍然位居HOTA、IDF1和ASSA的第一位。与其他跟踪器相比,它获得的ID要少得多。请注意,我们使用与MOT17中完全相同的超参数,这意味着我们方法的泛化能力。与几种跟踪器相比,其检测性能(MOTA和DETA)略差。我们认为这是因为我们使用与MOT17相同的检测分数阈值,这会导致许多检测丢失。具体地说,我们的StrongSORT++的度量FN(假阴性数)是117,920,而ByteTrack[73]的度量只有87594
Qualitative Results. Figure 5 visualizes several tracking results of Strong-SORT++ on the test sets of MOT17 and MOT20. The results of MOT17-01show the effectiveness of our method in normal scenarios. From the resultsof MOT17-08, we can see correct associations after occlusion. The results ofMOT17-14 prove that our method can work well while the camera is moving.Moreover, the results of MOT20-04 show the excellent performance of Strong-SORT++ in scenarios with severe occlusion.
定性结果。图5可视化了MOT17和MOT20测试集上强排序++的几个跟踪结果。MOT17-01的测试结果表明,该方法在正常情况下是有效的。从MOT17-08的结果中,我们可以看到遮挡后正确的关联。MOT17-14的实验结果证明了我们的方法能够在摄像机移动的情况下很好地工作,MOT20-04的实验结果显示了强排序++算法在严重遮挡场景下的优异性能。
5.5 Limitations
StrongSORT and StrongSORT++ still have several limitations. The main concern is their relatively low running speed compared with joint trackers and several appearance-free seperate trackers. Further research on improving computationalefficiency is necessary. Moreover, although our method ranks first in metricsIDF1 and HOTA, it has a slightly lower MOTA, which is mainly caused bymany missing detections due to the high threshold of the detection score. Webelieve an elaborate threshold strategy or association algorithm would help. Asfor AFLink, although it performs well in restoring missing associations, it ishelpless against false association problems. Specifically, AFLink cannot split IDmixed-up trajectories into accurate tracklets. Future work is needed to developstronger and more flexible global link strategies.
StrongSORT和StrongSORT++仍有几个限制。主要的问题是,与联合跟踪器和几种appearance-free的单独跟踪器相比,它们的运行速度相对较低。在提高计算效率方面还需要进一步的研究。此外,虽然我们的方法在IDF1和HOTA指标中名列前茅,但它的MOTA略低,这主要是由于检测分数的高门限导致了许多漏检造成的。我们相信精心设计的阈值策略或关联算法会有所帮助。至于AFLink,虽然它在恢复丢失的关联方面做得很好,但它对错误关联问题无能为力。具体地说,AFLink不能将ID混淆的轨迹拆分成精确的轨迹。未来需要开展工作,以制定更强大、更灵活的全局联系策略。
6 Conclusion
In this paper, we revisit the classic tracker DeepSORT and improve it in variousaspects. The resulting StrongSORT achieves new SOTA on MOT17 and MOT20benchmarks and demonstrates the effectiveness of the DeepSORT-like paradigm.We also propose two lightweight and appearance-free algorithms to further refinethe tracking results. Experiments show that they can be applied to and benefitvarious state-of-the-art trackers with a negligible extra computational cost. Our final method, StrongSORT++, ranks first on MOT17 and MOT20 in terms of HOTA and IDF1 metrics and surpasses the second-place one by 1.3 - 2.2. Notably, our method runs relatively slow compared with joint trackers. In the future, we will investigate further for an improved time-accuracy trade-off.
本文对经典跟踪器DeepSORT进行了重新审视,并对其进行了多方面的改进。所得到的StrongSORT在MOT17和MOT20基准上实现了新的SOTA,验证了DeepSORT类范式的有效性,并提出了两种轻量级的appearance-free算法来进一步完善跟踪结果。实验表明,它们可以应用于各种最先进的跟踪器,并且可以在可以忽略的额外计算代价的情况下受益于各种跟踪器。在HOTA和IDF1度量方面,我们的最终方法StrongSORT++在MOT17和MOT20上排名第一,超过第二名1.3-2.2。值得注意的是,与联合跟踪器相比,我们的方法运行相对较慢。在未来,我们将进一步研究改进时间精度的权衡。