ICLR 2022最佳论文解读
微信公众号“圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~
后台回复“交流”加入“圆圆的算法笔记”交流群;回复“时间序列“、”多模态“、”迁移学习“、”NLP“、”图学习“、”表示学习“、”元学习“等获取各个领域干货算法笔记~
今天给大家介绍ICLR 2022最佳论文PICO: CONTRASTIVE LABEL DISAMBIGUATION FOR PARTIAL LABEL LEARNING,这篇文章解决的是Partial Label Learning(PLL)问题,即训练数据中一个图像不是一个确定的label,而是一组可能的label集合,需要预测出每个样本的真实label。

下载地址:https://openreview.net/pdf?id=EhYjZy6e1gJ
1. 什么是Partial label learning (PLL)
有监督学习是最常见的一种机器学习问题,给定一个输入样本,预测该样本的label是什么。Partial Label Learning(PLL)问题也是预测一个样本对应的label,但是和有监督学习问题的差异是,PLL问题的训练数据中,一个输入样本对应多个候选label,真正的label是候选label中的一个。
为什么会有PLL这样的问题呢?因为在现实问题中,label来自于人工标注,而有的样本人工标注比较困难,只标注一个label会造成噪声较大的问题。例如下面的例子中,比较难区分这张狗对应的类别是哈士奇、雪橇犬还是萨摩耶,强行让人工标注成一个确定的label容易在数据中引入噪声。PLL放宽了这种限制,在标注的label中可以引入一些不确定性,给一个样本赋予多个候选label,模型学习从这些label中预测ground-truth对应的那个label。

2. PLL问题的难点
PLL的效果目前和有监督学习还有一定差距。PLL问题的难点在于标签消歧,也就是从候选label集合中预测出样本的真实label。业内一般的解法是学习样本高质量的表示,然后根据在特征空间中距离近的样本更可能属于同一类别这个假设,实现标签消歧。
然而,这种方法的问题在于,当label是一个不确定的集合而不是一个确定值时,这种不确定性也会对表示学习的过程造成负面影响。表示学习效果不好,又会对标签消歧的效果造成负面影响。
为了解决这个问题,ICLR 2022的最佳论文提出了基于对比学习的PLL问题求解方法。利用对比学习提升表示学习的效果,再利用良好的表示对label进行消歧,消歧后的label又有助于进一步生成良好的样本表征,形成良性循环,提升整体效果。
这篇文章提出的Partial label learning with COntrastive label disambiguation (PiCO) framework主要包括利用对比学习提升表示生成质量,以及基于聚类的label消歧两个核心模块。下面,我们走进这篇最佳论文,理解其背后的思想。
3. PiCO核心点1—对比学习引入PLL
第一个核心点是为了提升PLL中的表示生成效果,作者将对比学习的方法引入到PLL问题中。对比学习在有监督问题上已经取得广泛的应用,但是在PLL问题上目前还没有相关研究。将对比学习应用到PLL的一个最主要的问题是正样本对如何构造。在有监督学习中,每个样本都有其对应的确定性label,天然可以构造出正样本。而PLL问题中,每个样本的label是不确定的,无法直接获取正样本对。
为了解决上述问题,本文提出利用分类器对样本的预测结果作为样本真实label(也就是伪标签persudo label),根据这个label构造正样本对。在得到正样本对后,利用MoCo对比学习框架进行表示学习,将样本的两种view分别输入两个参数共享的Encoder,其中key侧的Encoder使用动量更新的方式减小计算开销。对比学习loss作为一个辅助任务和主任吴联合学习。对MoCo等对比学习框架不了解的同学,可以参考我之前的文章:
利用对比学习,可以让样本在特征空间形成类簇,这也为后续的标签消歧奠定了基础。

4. PiCO核心点2—标签消歧
本文采用了一种类似EM算法的思路实现标签消歧。首先,对于每个类别维护一个embedding向量u,它可以视为类的类簇中心。对于每个样本的label,在PLL中也用一个N维向量表示s,N代表类别数量,表示了该样本属于每个类别的概率。接下来为了实现标签消歧,在训练过程中不断更新s,更新方法是看样本表示和哪个类别向量最近,就用滑动平均的方式对s的那一维进行更新,公式可以表示为:

相应的,类别向量u也利用滑动平均的方式进行更新,公式如下:
![]()
通过这两个步骤的迭代进行,逐步实验标签消歧。这其实和Kmean以及Kmeans++这种方法类似,本质上就是一个聚类过程。从PiCO框架整体来看,对比学习提升表示学习效果,表示质量的提升又促进了下游基于聚类的标签消歧效果,标签的确定性增加又进一步提升了表示生成的质量,形成了良性循环。
5. 实验结果
本文进行了大量实验从多个角度验证了PiCO解决PLL问题的效果。在样本表示的学习上,从下面的t-SNE向量可视化分析图可以看出,PiCO生成不用类别的向量表示非常清晰,类内的内聚性和类间的差异性相比其他方法都是更好的。

下面的实验结果对比了PiCO和和其他方法在PLL问题上的效果,可以看出PiCO要比其他方法效果有非常显著的提升。
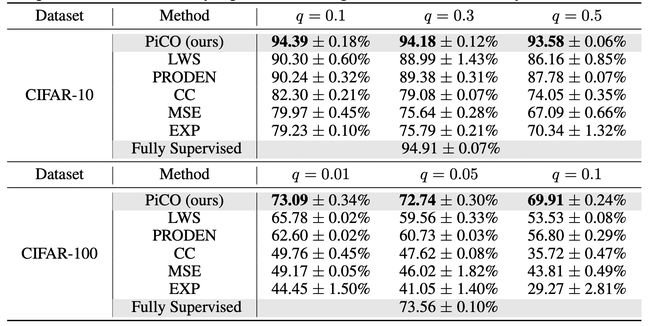
6. 总结
本文介绍了ICLR 2022的最佳论文,在Partial Label Learning问题上的解决方法。通过这篇文章,核心是理解顶会最佳论文的设计思路,本文用的求解方法比较优雅,背后的设计思路也非常清晰,背后的思考非常值得学习。
微信公众号“ 圆圆的算法笔记”,持续更新NLP、CV、搜推广干货笔记和业内前沿工作解读~
后台回复“ 交流”加入“ 圆圆的算法笔记”交流群;回复“ 时间序列“、”多模态“、”迁移学习“、”NLP“、”图学习“、”表示学习“、”元学习“等获取各个领域干货算法笔记~
后台留言”交流“,加入圆圆算法交流群~
后台留言”论文“,获取各个方向顶会论文汇总~
【历史干货算法笔记】
12篇顶会论文,深度学习时间序列预测经典方案汇总
如何搭建适合时间序列预测的Transformer模型?
Spatial-Temporal时间序列预测建模方法汇总
最新NLP Prompt代表工作梳理!ACL 2022 Prompt方向论文解析
图表示学习经典工作梳理——基础篇
一网打尽:14种预训练语言模型大汇总
Vision-Language多模态建模方法脉络梳理
花式Finetune方法大汇总
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程