SS-Model【2】:DeepLabv1
系列文章目录
DeepLab语义分割系列(一):
SS-Model【2】:DeepLabv1
DeepLab语义分割系列(二):
SS-Model【3】:DeepLabv2
DeepLab语义分割系列(三):
SS-Model【4】:DeepLabv3
文章目录
- 系列文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
- 2. Advantages
- 3. Network Architecture
-
- 3.1. Architecture
- 3.2. Convolutional Neural Networks For Dense Image Labeling
-
- 3.1.1. Efficient Dense Sliding Window Feature Extraction With The Hole Algorithm
- 3.1.2. Controlling The Receptive Field Size And Accelerating Dense Computation With Convolutional Nets
- 3.3. Detailed Boundary Recovery: Fully - Connected Conditional Random Fields And Multi - Scale Prediction
-
- 3.3.1. Deep Convolutional Networks And The Localization Challenge
- 3.3.2. Full - Connected Conditional Random Fields For Accurate Localization
-
- 3.3.2.1. Application
- 3.3.2.2. Application on semantic segmentation
- 3.3.3. Multi - Scale prediction
- 总结
前言
DeepLab是一个语义分割的架构。首先,输入的图像通过网络,使用扩张卷积。然后,网络的输出被双线性插值,并通过全连接的CRF来微调结果,我们得到最终的预测。
原论文链接:
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
1. Abstract & Introduction
1.1. Abstract
深度卷积神经网络 (DCNN) 最近在高级视觉任务(例如图像分类和对象检测)中展示了最先进的性能。 这项工作将 DCNN 和概率图形模型的方法结合在一起,用于解决像素级分类任务(也称为“语义图像分割”)。本文表明,DCNN 最后一层的响应没有充分定位到准确的对象分割。 这是由于非常不变的属性使 DCNN 适合高级任务。本文通过将最终 DCNN 层的响应与完全连接的条件随机场 (CRF) 相结合,克服了深度网络的这种不良定位特性。定性地说,本文提出的 “DeepLab” 系统能够以超出以前方法的准确度来定位分段边界。
1.2. Introduction
将 DCNN 应用到计算机视觉系统,在包括图像分类在内的一系列高级问题上的一个共同主题是,以端到端方式训练的 DCNN 提供的结果比依赖于精心设计的表示的系统(如 SIFT 或 HOG 特征)要好得多。这一成功可以部分归因于 DCNN 对局部图像转换的内在不变性,这巩固了它们学习数据分层抽象的能力。虽然这种不变性对于高级视觉任务显然是可取的,但它可能会妨碍低级任务,例如姿势估计和语义分割——我们想要精确定位,而不是空间细节的抽象。
将 DCNN 应用于图像标记任务有两个技术障碍:信号下采样和空间“不敏感”(不变性)。第一个问题与在标准 DCNN 的每一层执行最大池化和下采样的重复组合所导致的信号分辨率降低有关,我们采用最初为有效计算未抽取离散小波变换而开发的 atrous(带孔)算法。 这使得 DCNN 响应的高效密集计算可以采用比该问题的早期解决方案简单得多的方案。
第二个问题涉及从分类器获得以对象为中心的决策需要对空间变换保持不变性,这从本质上限制了 DCNN 模型的空间精度。我们通过采用完全连接的条件随机场 (CRF) 来提高模型捕获精细细节的能力。 条件随机场已广泛用于语义分割,将多路分类器计算的类别分数与像素和边缘的局部交互捕获的低级信息相结合。
2. Advantages
- 速度更快,论文中说是因为采用了膨胀卷积的原因,但 fully-connected CRF 很耗时
- 准确率更高,相比之前最好的网络提升了 7.2 个点
- 模型很简单,主要由 DCNN 和 CRF 联级构成

3. Network Architecture
3.1. Architecture
调整 VGG16 模型,转为一个可以有效提取特征的语义分割系统
DeepLab-LargeFOV

- 将 VGG16 的 FC 层转为 conv 层,模型变为全卷积的方式(端到端训练)
- 将最后的两个最大池化层的 stride = 1(原本的 output_stride = 32,现在为 8)
- 保证 feature 的分辨率
- 把最后三个卷积层的 dilate rate 设置为2,且第一个全连接层的 dilate rate 设置为4(保持感受野)
- 把最后一个全连接层的通道数从 1000 改为 21(分类数为 21)
- 第一个全连接层,通道数从 4096 变为 1024,卷积核大小从 7x7 变为 3x3,后续实验中发现此处的 dilate rate 为 12 时(LargeFOV),效果最好
- 最后通过一次8倍上采样,还原回原图的尺寸
3.2. Convolutional Neural Networks For Dense Image Labeling
3.1.1. Efficient Dense Sliding Window Feature Extraction With The Hole Algorithm
即使用空洞卷积,关于空洞卷积的详细说明,可以参考我的另一篇blog:SS【1】:转置卷积与膨胀卷积
在一维的情况下,我们扩大输入核元素之间的步长:

在二维的情况下,如下图所示:
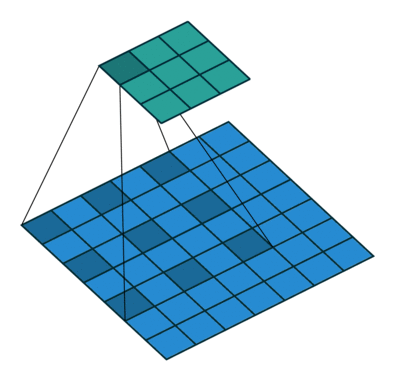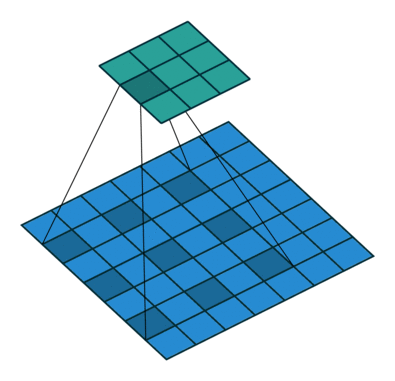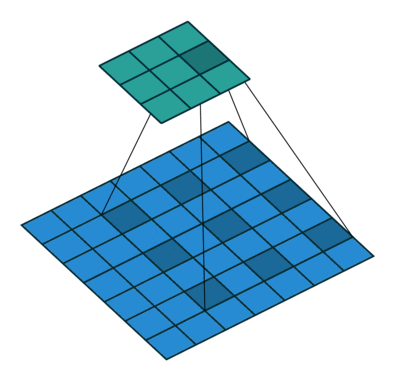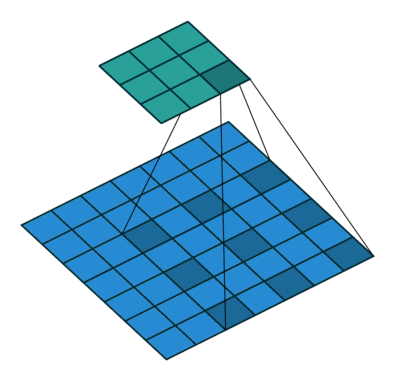
这种带孔的采样又称 atrous 算法,可以稀疏的采样底层特征映射,该方法具有通用性,并且可以使用任何采样率计算密集的特征映射。在 VGG16 中使用不同采样率的空洞卷积,可以让模型再密集的计算时,明确控制网络的感受野。保证 DCNN 的预测图可靠的预测图像中物体的位置。
3.1.2. Controlling The Receptive Field Size And Accelerating Dense Computation With Convolutional Nets
在重新设计网络进行密集分数计算时,需要明确控制网络的感受域大小(receptive filed size FOV)
这里调整的层,针对的是特征提取模块结束后的第一层,也就是 FC1
简单来说,当前很多基于 DCNN 图像识别方法都依赖于 ImageNet 上预训练的分类网络(迁移学习)。比如 VGG16 卷积部分具有较大的感受野,将网络转化成全卷积网络,那么第一层的全连接有 4096 个 7x7 的卷积,是训练过程中的计算瓶颈
(该优化操作不为常见,仅在 deeplabv1、deeplabv2 中使用)
3.3. Detailed Boundary Recovery: Fully - Connected Conditional Random Fields And Multi - Scale Prediction
3.3.1. Deep Convolutional Networks And The Localization Challenge
训练时将预训练的 VGG16 的权重做 Fine-tune(冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层),损失函数取输出的特征图与 ground truth 下采样 8 倍做交叉熵和;测试时取输出图双线性上采样8倍得到结果。但 DCNN 的预测物体的位置是粗略的,没有确切的轮廓。
在卷积网络中,因为有多个最大池化层和下采样的重复组合层使得模型的具有平移不变性,我们在其输出的 high-level 的基础上做定位是比较难的。这需要做分类精度和定位精度之间是有一个自然的折中。
解决这个问题的工作,主要分为两个方向:
- 第一种是利用卷积网络中多个层次的信息
- 第二种是采样超像素表示,实质上是将定位任务交给低级的分割方法
DeepLab 是结合了 DCNNs 的识别能力和全连接的CRF的细粒度定位精度,寻求一个结合的方法,结果证明能够产生准确的语义分割结果:

3.3.2. Full - Connected Conditional Random Fields For Accurate Localization
3.3.2.1. Application
传统上,CRF 已被用于平滑噪声分割图。通常,这些模型包含耦合相邻节点的能量项,有利于相同标签分配空间近端像素。定性的说,这些短程的CRF主要功能是清除在手工特征基础上建立的弱分类器的虚假预测。
与这些弱分类器相比,现代的 DCNN 体系产生质量不同的预测图,通常是比较平滑且均匀的分类结果(即以前是弱分类器预测的结果,不是很靠谱,现在DCNN的预测结果靠谱多了)。在这种情况下,使用短程的 CRF 可能是不利的,因为我们的目标是恢复详细的局部结构,而不是进一步平滑。而有工作证明可用全连接的 CRF 来提升分割精度。
使用空洞卷积避免了层层上采样,得到了网络的输出。之后直接使用双线性插值恢复到原尺寸,然后使用 fully-connected conditional random fields(邻域间的锐化),得到最终的分割结果:

3.3.2.2. Application on semantic segmentation
对于每个像素位置 i i i 具有隐变量 x i x_i xi (这里隐变量就是像素的真实类别标签,如果预测结果有21类,则 i ∈ 1 , 2 , . . , 21 i \in 1, 2, .. ,21 i∈1,2,..,21),还有对应的观测值 y i y_i yi(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量 y i y_i yi 来推测像素位置i对应的类别标签xi。条件随机场示意图如下:

此处涉及到复杂的数学推导与计算,博主不是很了解,建议大家自行在网上搜索,到了 Deeplabv3 的时候,将不再使用 CRF 了
3.3.3. Multi - Scale prediction
Multi-Scale Prediction,即融合多个特征层的输出,除了使用之前主分支上输出外,还融合了来自原图尺度以及前四个 Maxpool 层的输出。详细结构参考下图:

多尺度预测是希望获得更好的边界信息,与 FCN skip layer 类似:
- 在输入图片和前 4 个 Maxpool 层后添加 MLP(多层感知机,第一层是 128 个 3×33×3 卷积,第二层是 128 个 1×11×1 卷积),得到预测结果
- MLP 输出的特征映射送到模型的最后一层辅助预测,合起来后模型的 sofmax 层输入特征多了 5x128=640 个通道
效果不如 dense CRF,但有一定的提高
总结
视频资料
翻译参考
与其他先进模型相比,DeepLab 捕获到了更细节的边界。
DeepLab 创造性的结合了 DCNN 和 CRF 产生一种新的语义分割模型,模型有准确的预测结果同时计算效率高。DeepLab 是卷积神经网络和概率图模型的交集,后续可考虑将 CNN 和 CRF 结合到一起做 end-to-end 训练