SSIS高级内容 系列四
1. 如何导入EXCEL文件选择行列
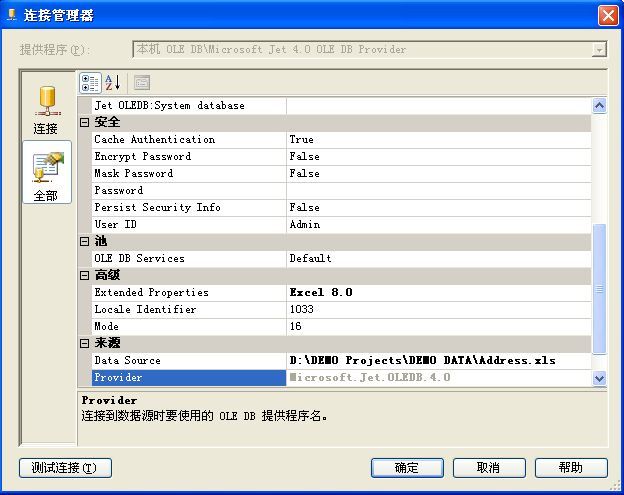
1 这里不用“Execl连接管理器”,而是选择创建“OLEDB连接管理器”,并选择“Microsoft Jet 4.0 OLE DB”提供程序;
2 在“Extended Properties”扩展属性栏中,输入“Excel 8.0”。如下图所示:
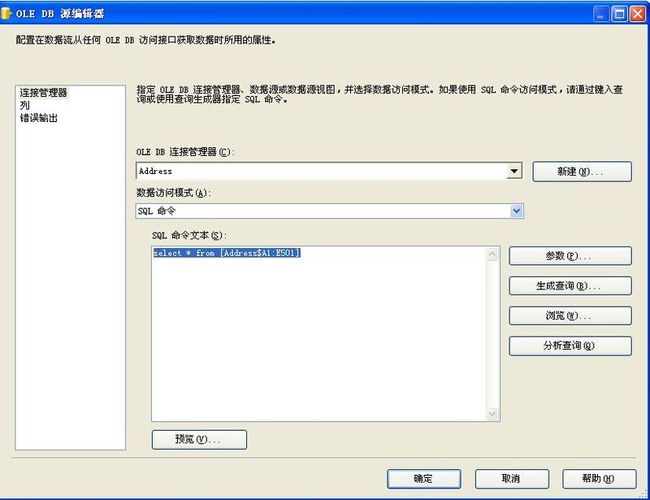
3 在执行SQL任务或OLEDB源中使用以下查询语句:
SELECT * FROM [SheetName$FromCellName:ToCellName]
例如:查询从A列到E列,从第1行到501行共500行数据如下:
select * from [Address$A1:E501]
2. 包部署方式的选择
2.1 保存成文件的优点
(1) 可以使用源代码控制进行管理
(2) 当使用“用户密钥加密”选项时具有相当高的安全性
(3) 不会受到网络故障的影响(存储在本地系统中)
(4) 可以将部署文件包交给第三方保管,其中包括复杂的文件
(5) 只需要较少的步骤即可载入设计器中。
(6) 更便于直接访问查看
(7) 可以按照层次化结构将包存储到文件系统中
(8) Visual Studio中的项目建立在磁盘的基础上,因此要求包保存到文件系统中
(9) 在开发过程中使用方便
2.2 保存到SQL Server中的优点
(1) 具有数据库安全性、DTS角色和“Agent” (代理)交互等优点
(2) 包会随着正常的数据库备份操作而带到备份
(3) 能够通过查询对包进行筛选
(4) 能够通过新的包文件夹一层次化结构存储包
(5) 在生产中使用起来更方便
1. 包模板
1 创建包模板,命名为:PackageTemplate.dtsx
2 拷贝到%ProgramFiles%"Microsoft Visual Studio 8"Common7"IDE"PrivateAssemblies"ProjectItems"DataTransformationProject"DataTransformationItems目录下
如:C:"Program Files"Microsoft Visual Studio 8"Common7"IDE"PrivateAssemblies"ProjectItems"DataTransformationProject"DataTransformationItems
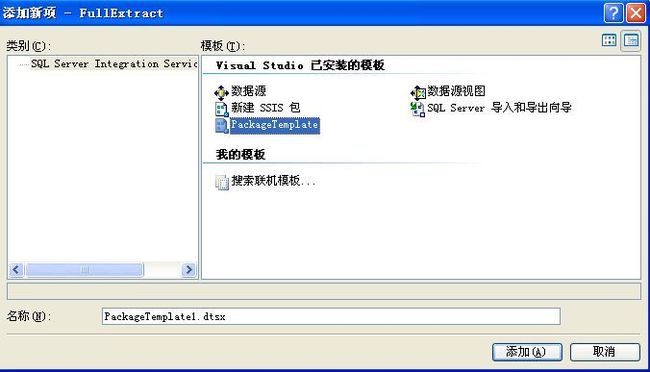
3 右键单击解决方案,在弹出的选择“添加”->“新建项”,选择刚才添加包的新模板PackageTemplate.dtsx重命名为:PackageTemplate1.dtsx
如下图:
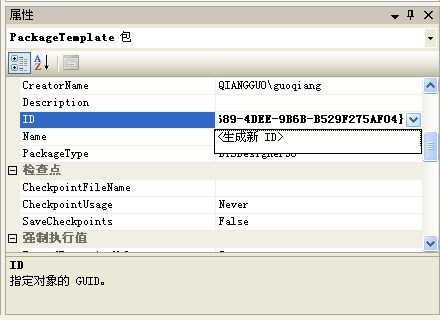
4 在新创建的包PackageTemplate1.dtsx,生成新的包ID,如下图所示:
2. 数据同步策略
2.1 数据源中有增量数据
1 寻找增量时间戳
(1)各种数据库:表的创建时间字段和修改时间字段或者最后的修改时间字段;
(2)sql server:可以用找自增字段或者时间戳;
(3)Oracle:找序列字段也是自增的;
(4)如果找不到以上字段,可以分析实际业务数据:比如各种编号是不是不重复自增的;
上个月的数据不会改变,变化只是本月的,那么本月数据就是增量数据;
(5)有增量变更记录数据表,标识哪些字段是insert,update和delete
2 如何实现insert,update和delete
(1)对有增量变更记录数据表的,拆分一下(insert,update和delete),很简单直接就可以同步处理数据了;
(2)对有增量数据的:
A:Lookup组件delete可以实现insert和update,delete只能采用outer join方法;
B:outer join和NULL关键字方法可以实现insert,update和delete,但是当数据量较大时消耗性能。
C:SCD缓慢变化维度组件可以很容易实现insert和update,delete只能采用outer join方法;
2.2 数据源无增量数据
如果实在找不到增量数据,只能先全部删除然后全部抽取
1.1 事务
1 事务:
Distributed Transaction Coordinator(DTC) Transactions:一个或多个需要DTC的事务,可以跨连接,任务和程序包。
Native Transaction:位于SQL Serve引擎级的事务,使用单一连接,该连接通过使用一个T-SQL事务命令来管理。
注:Microsoft Distributed Transaction Coordinator(MSDTC)允许应用程序跨越两个或多个SQL Server的实例来扩展事务。此外,它还允许应用程序参与到与X/Open DTP XA标准兼容的事务管理器来管理的事务中。
2 设置TransactionOption属性
Supported:如果在父对象(程序包)中已经存在事务,则容器将加入事务;
Not Supported:如果当前存在一个事务,容器将不加入事务;
Required:如果父对象不存在事务,则容器将启动一个事务,否则它将加入父对象的事务。
2. 执行树
2.1 数据流的转换类型
1阻塞特性
非阻塞转换:转换中所应用的逻辑再对数据行进行转换后不会阻止数据移动到下一个转换。
流转换:可以使用预先缓存的数据来快速应用转换逻辑并处理引擎中的计算过程。
基于行的转换:数据转换中的行是逐个流动的。
半阻塞转换:再内存缓存流动到下游之前,会再数据流中将记录保留一段时间的转换。
阻塞转换:从上游接收到所有数据然后再流向下游转换或目的地。
同步或异步输出
异步转换输出:输入中所使用的缓存与输出中所用的缓存不同。
同步转换输出:在转换逻辑执行结束后立即将缓存转移到下游的转换。
2.2 执行树
1 执行树定义
执行树是根据数据流组件(转换和适配器)彼此之间的同步关系而确定的逻辑分组。
2 执行树原则
(1) 在执行树中的每个组件和同一执行树中的剩余同步组件将转换逻辑应用于相同的一组缓存集。
(2) 不同的执行树使用不同的缓存集,因此位于新执行树中的数据要求将转换后的数据复制到针对下一个内嵌执行树而分配的新缓存中。
(3) 集成服务针对每个执行树使用一个进程线程,同时针对每个源适配器将使用一个进程线程。
3 监视数据流执行
PipelineExecutionPlan:数据流的处理过程
PipelineExecutionTree:执行树的转换输入和输出的分组情况
4 两个重要参数
MaxConcurrentEcecutables 默认设置为-1。该值向SSIS表示最大并发任务数是将任务 处理程序(CPU)总数加2,然后使用该数值作为最大并发任务数。
EngineThread =源线程树+执行树数
注:
1 在任何一个执行树中同时包含了输入和输出的转换为同步转换,反之为异步转换。
2 如果数据流中的执行树超过了可用的EngineThread值,则一个WorkThread可能会分配给多个执行树。