CVPR2019领域自适应/语义分割:Adapting Structural Information across Domains for Boosting Sema适应结构信息跨领域促进语义分割
CVPR2019 All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation 所有关于结构:适应结构信息跨领域促进语义分割
- 0.摘要
- 1.概述
- 2.相关工作
- 3.方法
-
- 3.1.领域不变的结构提取
- 3.2.学习
- 3.3.实现
-
- 3.3.1.网络架构
- 3.3.1.训练细节
- 4. 实验结果
-
- 4.1.数据集
- 4.2.性能比较
- 4.3.消融实验
- 4.4.Image-to-Image翻译
- 5. 结论
- 参考文献
论文下载
代码开源
0.摘要
在本文中,我们解决了用于语义分割任务的无监督域适应问题,我们试图在没有任何注释的情况下,将在带有地面真实标签的合成数据集上学习到的知识转移到真实世界的图像。与假设图像是最丰富的结构内容和决定性因素语义分割,能够很容易地跨域共享,我们提出一个域不变结构提取(DISE)框架解决图像域不变结构和特定于域的纹理表示,进一步实现了图像的跨域翻译和标签转移,提高了分割性能。大量的实验验证了我们提出的dis模型的有效性,并证明了其优于几种最先进的方法。
1.概述

图1所示。比较传统的领域适应的语义分割和我们提出的方法。而不是使整个特征表示域不变,我们只对齐结构组件的分布跨域
语义分割是预测图像的像素级语义标签。它被认为是计算机视觉中最具挑战性的任务之一。由于近年来深度学习的复兴,我们看到了这一任务的巨大飞跃。全卷积网络(FCN)建立在预先训练的分类模型(如VGG[21]和ResNet[7])和反卷积层的基础上,自其诞生以来,人们提出了许多技术来推进语义分割,如扩大接受域[2,27]和更好地保存上下文信息[28],举几个例子。然而,这些方法很大程度上依赖于监督学习,因此需要昂贵的像素级注释。为了解决这个问题,一种解决方案是在合成数据上训练分割模型。当今的计算机图形技术能够合成高质量、逼真的虚拟场景图像。因此,可以基于这些合成图像建立一个有监督的语义分割数据集(例如GTA5[17]和SYNTHIA[18])。在渲染过程中,它们的像素级语义标签随时可用。然而,在合成数据集上训练的分割模型往往难以在真实世界场景中获得令人满意的性能,这是由于一种被称为领域转移的现象——即,合成图像和真实图像在低级纹理外观上仍然可以显示出相当大的差异。
因此,领域适应被提出,将知识从一个源领域(如合成图像)转移到另一个目标领域(如真实图像)。一种常见的方法是通过匹配其特征分布来学习跨域的域不变特征空间,其中已经探索了不同的匹配标准,例如最小化二阶统计量[23]和域对抗训练[6,8,25]。最近还有一项研究[24],直接在结构输出空间中引入分布对齐来完成语义分割任务。然而,这些方法都是由一个强烈的假设驱动的,即两个域的整个特征或输出空间可以很好地对齐(参见图1 (a)),从而产生一个对所讨论的任务也具有区别性的域不变表示。
在本文中,我们提出了一个领域不变结构抽取(DISE)框架,以解决无监督的领域适应语义分割。我们假设图像的高级结构信息将是最有效的分割预测。因此,我们的DISE旨在通过学习将图像的领域不变结构信息与其领域特定纹理信息分离,发现一个领域不变结构特征,如图1 (b)所示。
我们的方法不同于之前类似的工作:
- 学习由明确的领域不变结构组件和领域特定纹理组件组成的图像表示,
- 使结构组件具有领域不变
- 允许跨领域的图像到图像的转换,这进一步允许标签转移,所有这些都在一个框架内实现。尽管DISE与域分离网络[1]和DRIT[13]有一些相似之处,但它强调的是结构和纹理信息的分离,以及跨域翻译图像并同时保持结构的能力,显然突出了它的新奇之处。在标准化数据集上进行的广泛实验证实了其优于几种最先进的基线。
2.相关工作

表1。在语义分割领域适应方面,已有研究采用了不同的策略。IT、DA、LT分别代表图像平移、分布对齐和标签传输。顺序表示这些策略应用的顺序。
与已有许多研究领域适应问题的图像分类相比,语义分割被认为是应用领域适应的更具挑战性的任务,因为它的输出是一个分割图,充满了高度结构化和上下文语义信息。我们在这里回顾了一些相关的工作,并根据三种广泛使用的策略进行分类:分布对齐,图像平移和标签转移。不同的作品对这些策略的选择和实施顺序可能有所不同,如表1所示。
首先,与图像分类中的域适应类似,在特征空间(如[9,20,26,30])或输出空间中,可以采用不同的标准来匹配跨域的分布。后者的代表性工作是由Tsai等人[24]提出的,其中对抗学习应用于分割映射,基于源和目标域之间的空间上下文相似性。然而,考虑到在某些应用中,合成图像和真实图像在外观(即纹理)上的实质性差异,假设两个域的整个特征或输出空间可以很好地对齐往往是不切实际的。
其次,最近在图像到图像的平移和风格转移方面的进展[10,12,29]促使源图像平移以获得目标图像的纹理外观,反之亦然。一方面,这种翻译过程允许分割模型使用翻译后的图像作为增强训练数据[8,26];另一方面,在图像平移过程中学习到的共同特征空间有助于学习领域不变的分割模型[20,30]。
最后,图像到图像的转换使标签从源域转移到目标域成为可能,为学习适用于目标域图像的模型提供了额外的监督信号[8,26]。然而,直接的图像转换可能对学习有害,因为有将源特定信息传递到目标域的风险。
我们提出的DISE使用了所有这三种策略,但在几个重要方面与之前的工作有所不同。我们假设图像的高级结构信息对其语义分割来说是最重要的信息。因此,DISE是通过一组公共和私有编码器将图像的高级、领域不变的结构信息与其低级、领域特定的纹理信息分离开来。
3.方法
在本文中,我们提出了一个域不变结构抽取(DISE)框架来解决无监督域适应语义分割的问题。强调明确地规范化公共和私有编码器以捕获结构和纹理信息,以及将图像从一个域转换到另一个域以进行标签传输的能力,突出了我们的方法的新颖之处。下面给出了dis的正式处理。我们首先概述它的框架。接下来,我们将详细介绍所使用的损失函数,然后描述实现细节。
3.1.领域不变的结构提取

图2。概述了提出的用于语义分割的领域不变结构提取(DISE)框架。DISE框架由跨域共享的公共编码器Ec、两个特定于域的专用编码器Esp、Etp、像素分类器T和共享解码器D组成。它将图像、源域或目标域编码为特定于域的纹理组件zp和域不变结构组件zc,如(a)部分所示。通过这种分离,它可以将一个域中的图像xs(分别为xt)的结构内容与xt(分别为xs)的纹理外观相结合,将一个域中的图像xs(分别为xt)转换为另一个域中的图像xˆs2t(分别为xˆt2s),如(b)和(c)部分所示。这进一步实现了地面真相标签从源域到目标域的传输,如第(d)部分所示
DISE的目的是学习由领域不变结构组件和领域特定纹理组件组成的图像表示。设访问Ns个带注释的源域图像Xs = {(xsi, ysi)}Nsi=1,每个图像xsi∈R^H×W ×3^ 具有对象类别的高H、宽W和C类像素标签 ysi∈{0,1}^H×W ×C^,Nt个未注释的目标图像 Xt = {xti}Nti=1。如图2 (a)所示,在DISE中有五个子网络,即跨域共享的公共编码器Ec、特定域的私有编码器Esp、Etp、共享解码器D和像素分类器T。它们分别由θc、θsp、θtp、θd和θt参数化。
给定一个源域图像xs作为输入,公共编码器Ec产生zsc = Ec(xs;θc)表征其域不变的高级结构信息,而源特定的私有编码器Esp生成zsp = Esp(xs;θsp)用于捕捉其残余方面,这些方面主要与特定领域的低水平纹理信息有关。这两个分量,{zsc ,zsp}是相辅相成的;当组合在一起时,它们允许解码器D最小化输入xs与其重构xˆs2s = D(zsc ,zsp;θd)之间的重构损失Lsrec。同样,目标域图像xt也可以被类似地编码和解码,以最小化Ltrec,得到ztc = Ec(xt;θc), ztp = Etp(xt;θtp)和xt≈xˆt2t = D(ztc, ztp;θd),其中私有编码器Etp与对应的Esp一样,提取目标特定的纹理信息。分类器T将使用结构分量zsc, ztc来预测源域和目标域的分割图,yˆs = T (zsc, θt),yˆt = T (ztc, θt)。
利用领域对抗训练[14]和感知损失最小化[12]对图像平移进行正则化,实现结构和纹理信息的解纠缠。如图2 (b)和©所示,我们考虑任意一对源域和目标域图像及其各自的表示xs = {zsc, zsp}和xt = {ztc, ztp}。我们首先交换它们的领域特定组件,然后将它们解码为两个不可见的、翻译后的图像xˆs2t = D(zsc, ztp;θd)和xˆt2s = D(ztc, zsp;θd)。如果公共编码器和私有编码器的行为与我们预期的一样,它们分别捕获结构和纹理信息,则翻译后的图像ˆxs2t(分别为ˆxt2)应该具有与xs(分别为xt)相同的高级结构,同时显示与xt(分别为xs)相似的低级纹理外观。为此,我们通过施加域对抗性损失Lt2strans-adv, Ls2ttrans-adv[14]和感知损失Lt2strans-str, Lt2strans-tex, Ls2ttrans-str,在解码器D的输出处使用Ls2ttrans-tex[12],以确保这些翻译后的图像与源或目标域中的对应图像之间的域和感知相似性。DISE的图像转换功能进一步允许将地面真实标签从源域转移到目标域。更具体地说,由于类似于目标域的图像xˆs2t与xs共享相同的结构组件,基于我们的假设,即图像的分割预测仅依赖于其结构信息,我们认为xs的ground-truth标签ys是xˆs2t的伪标签。
最后,我们通过最小化分类器T输出端的另一个域对抗性损失Lseg-adv,以及地面真值标签ys相对于xs和xˆs2t的负对数似然函数,即Lsseg和Ls2tseg,使提取的结构组件zsc和ztc对域保持不变(见图2(d))。
3.2.学习
所提议的DISE的训练是最小化上述损失函数关于五个子网络的参数{θc,θsp,θtp,θd,θt}的加权组合:

其中,根据经验选择组合权重λ,以在模型容量、重建/翻译质量和预测精度之间取得平衡。下面,我们将详细介绍这些损失函数。
分割损失:基于源域GroundTruth ys的典型交叉熵给出的分割损失Lsseg(θc,θt)是对公共编码器Ec和分类器T进行监督训练,以预测源域图像xs的分割图yˆs。
输出空间对抗损失 :受Tsai等人[24]的启发,我们在分类器T的输出端引入了一个对抗性损失Lseg-adv(θc,θt),希望使通用编码器Ec和分类器T能够很好地在目标域图像上推广。具体地说,我们首先训练一个鉴别器Dsegadv,通过最小化监督域损失(即Dsegadv理想情况下应为源预测yˆs中的每个patch输出1,为目标预测yˆt中的每个patch输出0),在patch级别[11]区分源预测yˆs和目标预测yˆt。然后,我们更新公共编码器Ec和分类器T,通过将 yˆt的输出从0反转为1(即最小化)来愚弄鉴别器Dsegadv

其中,h’,w’是面片坐标,h’=H/16,w’=W/16,系数16说明鉴别器Dsegadv中的下采样。
重建损失:重建损失Lrec(θc,θsp,θtp,θd)是为了确保图像表示的两个域不变量和域特定分量zc,zp一起构成图像的几乎完整摘要。为了鼓励重建在感知上与输入图像相似,我们遵循感知损失的概念[12],将质量度量Lperc(x,y;w)定义为从预先训练的VGG网络中提取的特征表示之间的L1差异的加权和[22]。在符号方面,我们有
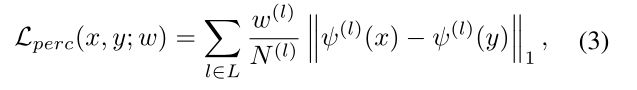
式中,ψ(l)(x)(分别,ψ(l)(y))是预训练VGG网络的第l层对输入x(y)的激活,N(l)是第l层中激活的次数,w(l)对第l层中的损失给出单独的权重,l指VGG网络的{relu1,relu2_1,relu3_1,relu4_1,relu5_1}。正如[12]所指出的,VGG网络的高层往往代表图像的高级结构内容,而下层通常描述其低级纹理外观。然后,通过最小化源域和目标域图像各自的感知损失之和,使用等式3来正则化源域和目标域图像的重建:
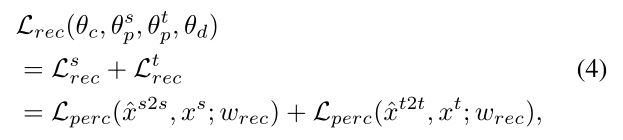
其中,权重wrec设置为在更高的层上更重
翻译结构损失。如前3.1节所述,跨域翻译产生的图像应保持其结构不变。等式5中定义的翻译结构损失Ltrans-str(θc,θsp,θtp,θd)测量翻译图像xˆs2t和从中导出xˆs2t结构成分的图像xs之间,以及同样地,Xˆt2s和xt之间的高层结构差异。这是通过为感知度量选择加权wstr来实现的,加权wstr再次强调预训练VGG网络更高层中的特征重建损失。我们的目标是惩罚在结构上与它们共享相同结构组件zc的图像显著不同的翻译图像,从而使zc明确编码图像的结构方面。
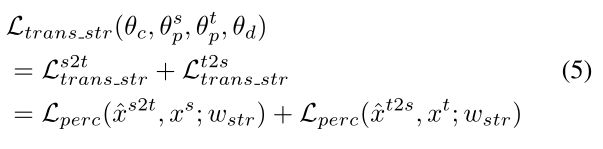
翻译纹理损失。翻译纹理损失Ltrans-tex(θc,θsp,θtp,θd)进一步要求翻译图像xˆs2t(xˆt2s)在纹理上应与图像xt(xs)非常相似,因为它们共享相同的纹理分量zp。在这样做时,zp必须明确编码图像的纹理方面。受AdaIN[10]工作的启发,我们提出了一种加权度量Ltex(x,y;w),用于明智地测量从预训练VGG网络中提取的激活平均值的差异:

其中C(l)是VGG网络l层中的通道数,w(l)指定给l层的权重,µC(·)返回通道C的平均激活。与翻译结构损失一样,翻译纹理损失也涉及两种类型的翻译:

现在选择感知度量的加权wtex,以更强调早期层。
翻译对抗性损失。除了上述感知损失外,我们还使用对抗性损失Ltrans-adv(θc、θsp、θtp、θd)来调整翻译图像xˆs2t和xˆt2s,使其看起来分别像是目标域和源域之外的图像。为此,我们采用了LSGAN[16]和Patch Discriminator[11]。
标签转移损失。标签传输损失Ls2tseg(θc,θt)由一个典型的交叉熵损失给出,该损失在带有伪标签ys的翻译图像xˆs2t上监督训练公共编码器Ec和分类器T。

3.3.实现
3.3.1.网络架构
在实验中,我们使用了一个基本模型,共同参考了通用编码器Ec和像素分类器T,类似于[24]中的分割网络,该网络是基于DeepLab-v2[2]和ResNet-101[7]构建的。我们通过对PASCAL VOC[5]数据集进行预训练来获得初始权重,并在训练时重用预训练的batchnorm层。公共编码器Ec将最后一个剩余层(第4层)的特征映射输出为zc。对于专用编码器Esp、Etp,我们采用一个包含4个卷积块的卷积神经网络,然后是一个全局池层和一个完全连接层。专用编码器Esp(Etp)的输出是8维表示的zsp(分别为ztp)。对于共享解码器D,我们使用三个剩余块和三个反卷积层。解码器的输入是zp、特征映射zc和指示私码域的标志。
3.3.1.训练细节
我们在一个16gb内存的特斯拉V100上使用Pytorch实现了DISE。完整的训练需要88个GPU小时。由于内存有限,在训练时,我们将输入图像的大小调整为512×1024,并以256×512的大小进行随机裁剪。然而,在测试时,输入图像的大小是512×1024。为了进行公平的比较,我们跟随Tsai等人[24],并在评估时调整输出预测从512×1024到1024×2048的大小。我们对批量大小为2的250,000次迭代的模型进行训练。我们使用初始学习率为2.5 × 10−4的SGD求解器,用于通用编码器Ec和分类器T;解码器D的初始学习率为1.0 × 10−3的Adam求解器;Adam求解器的初始学习率为1.0 × 10−4。所有的学习速率都按照多项式衰减策略下降。动量设置为0.9和0.99。
4. 实验结果
在本节中,我们对典型数据集进行语义分割实验。我们将我们提出的方法的性能与几个最先进的基线进行比较,并进行消融研究,以了解各种损失函数组合对分割性能的影响。代码和预先训练的模型可以在网上找到。
4.1.数据集
在实验中,我们遵循了之前大多数作品所采用的通用协议;即,将带有ground-truth注释的合成数据集GTA5[17]或SYNTHIA[18]作为源域,将Cityscapes数据集[4]作为目标域,在训练过程中没有可用注释。在测试时,对城市景观验证集进行评价。
4.2.性能比较

图3。根据GTA5改编时,城市景观的分割结果。从左到右,(a)目标图像,(b)地面真相,(c)仅来源,(d)常规适应[24],(e)和DISE
我们将我们的方法与几种基线进行了比较,包括[3,9,19,20,24,26]的模型。其中,文献[3,9,24]代表了传统的适应方法,即基于对抗性训练匹配跨域特征或输出空间的分布;文献[20,26]是通过图像平移或样式转移将源域图像在像素级映射到目标域的典型作品;[19]通过基于对象检测的前景实例方法脱颖而出。这些作品的更多细节可以在第2节找到。
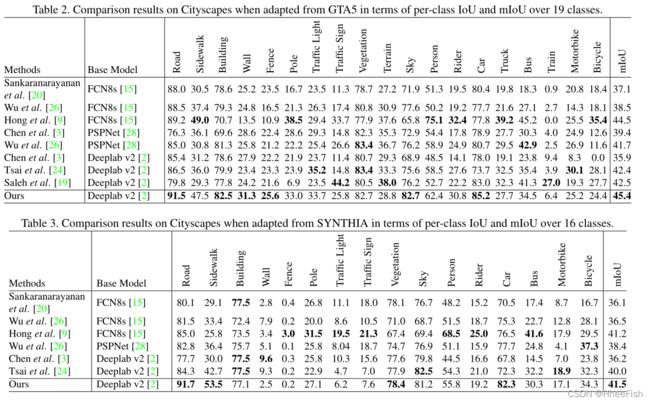
GTA5->Cityscapes。表2显示,与基线相比,我们的方法在平均相交-过并集(mIoU)方面达到了最先进的性能45.4。细分分析进一步显示,它在预测“道路”、“人行道”、“墙”、“栅栏”、“建筑”和“天空”类时,比大多数基线都要好得多。这些类经常并发地出现在图像中,并且往往在空间上是连接的。此外,“Road”、“Sidewalk”等也表现出高度相似的纹理外观。因此,我们将我们的方案的良好性能归因于它能够过滤特定领域的纹理信息,形成一个领域不变的结构表示用于语义分割。
在图3中,我们展示了将我们的方法与“仅来源”(即没有适应)和“常规适应”(即没有结构和纹理的解缠)进行比较的定性结果。对于后者,我们给出[24]的结果。很明显,我们的方法所做的分割预测看起来最类似于地面事实。经过进一步的研究,我们发现我们的模型与基线相比,可以更好地识别“人行道”和“道路”之间的差异。它还能很好地识别罕见的类别,如“极点”和“交通标志”。这些观察者的变化表明,我们的基于结构的表征确实比其他可能像“常规适应”那样编码了结构和纹理信息的表征更具辨别能力。
SYNTHIA->Cityscapes。我们还在更具挑战性的SYNTHIA数据集上评估所有模型。具体来说,我们遵循[24]来比较仅16个类的基于语义预测的结果。表3给出了每类欠条和mIoU的定量结果。我们可以看到上述关于GTA5数据集的讨论都可以延续到SYNTHIA中。虽然之前的工作[9]在mIoU上与我们的模型非常接近,但我们的方法在“Road”、“Sidewalk”、“Building”、“Sky”类上的优势仍然存在。
4.3.消融实验
以下是对我们的模型的四种变体的研究,通过比较它们与四个不同的训练目标的表现:
- 只有源域数据:仅通过最小化Lsseg来使用带注释的GTA5数据集[17]进行培训,即不进行任何领域适配。
- 分割图像自适应:使用带注释的GTA5数据集[17]进行训练,并通过最小化Lsseg和Lseg advat在输出空间进行域适应。这对应于[24]中的方法,它将跨域的分段预测对齐。
- DISE w/o 标签转移:使用除标签转移损失之外的所有损失功能进行训练,即设置分割映射适应加上结构和纹理组件的解缠。
- DISE:具有所有损失功能的训练。

表4。当从GTA5改编为mIoU时,城市景观的消融研究结果。我们给出了无自适应(仅源)、仅在输出空间自适应(Seg映射自适应)、在输出空间自适应以及结构和纹理解纠缠(DISE w/o标签转移)和考虑所有损失的自适应(DISE)的结果。
表4根据mIoU比较了这些设置的性能。正如预期的那样,在没有任何域适配的情况下,“Source Only”的性能最差,为39.8 mIoU。当在输出空间引入域适应时,Seg-map adaptive的性能提高了2.8,达到42.6 mIoU。“DISE w/o Label Transfer”的设置比“Source Only”的增益更高,为4.3,确认了解缠结构和纹理组件的好处。最后,由于标签传输的附加数据,DISE获得了最佳的性能。
4.4.Image-to-Image翻译
图4。翻译图像的示例结果。S2T:将(a)中GTA5图像的结构内容与(b)和(d)中城市景观图像的纹理外观相结合,分别输出(c)和(e)中的翻译图像。T2S:将(a)中城市景观图像的结构内容与(b)和(d)中GTA5图像的纹理外观相结合,分别输出(c)和(e)中的翻译图像。
在图4中,我们展示了在S2T和T2S两种设置下,使用DISE进行图像-图像转换的定性结果。我们利用S2T(分别,T2S)将列(a)中的GTA5(分别,Cityscapes)图像的结构内容与列(b)和(d)中的Cityscapes(分别,GTA5)图像的纹理外观相结合,分别生成列©和列(e)中的翻译图像。我们看到DISE在高质量地将图像从一个域转换到另一个域是非常有效的。在所有情况下,翻译后的图像都很好地保留了结构内容,同时产生了所需的纹理外观。这也验证了我们使用源域图像的地面真实标签作为其翻译图像的伪标签,其纹理外观类似于目标域图像。
5. 结论
在本文中,我们假设图像的高级结构信息对语义分割起着决定性的作用,并且可以使其跨域不变性。基于这一假设,我们提出了一种新的框架,即域不变结构提取(DISE),将图像表示分解为域不变结构分量和域特定纹理分量,其中,前者用于推进域适应语义分割。DISE还允许将地面真实标签从源域转移到目标域,为学习适合于目标域图像的分割网络提供额外的监督。在典型数据集上的大量模拟结果证实了DISE优于几种最先进的方法,验证了我们最初的假设
参考文献
[1] K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan. Domain separation networks. In Advances in Neural Information Processing Systems (NIPS), 2016. 2
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018. 1, 5, 7
[3] Y . Chen, W. Li, and L. V an Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2, 6, 7
[4] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 5, 6
[5] M. Everingham, S. A. Eslami, L. V an Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision (IJCV), 2015. 5
[6] Y . Ganin and V . Lempitsky. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning (ICML), 2015. 1
[7] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 1, 5
[8] J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P . Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle consistent adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning (ICML), 2018. 1, 2
[9] W. Hong, Z. Wang, M. Yang, and J. Y uan. Conditional generative adversarial network for structured domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2, 6, 7
[10] X. Huang and S. J. Belongie. Arbitrary style transfer in realtime with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 2, 5
[11] P . Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 4, 5
[12] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), 2016. 2, 3, 4
[13] H.-Y . Lee, H.-Y . Tseng, J.-B. Huang, M. Singh, and M.-H. Yang. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), 2018. 2
[14] M.-Y . Liu, T. Breuel, and J. Kautz. Unsupervised image-toimage translation networks. In Advances in Neural Information Processing Systems (NIPS), 2017. 3, 4
[15] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 7
[16] X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. P . Smolley. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 5
[17] S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision (ECCV), 2016. 1, 5, 6
[18] G. Ros, L. Sellart, J. Materzynska, D. V azquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 1, 5, 6
[19] F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez. Effective use of synthetic data for urban scene semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), 2018. 6, 7
[20] S. Sankaranarayanan, Y . Balaji, A. Jain, S. N. Lim, and R. Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 2, 6, 7
[21] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), 2014. 1
[22] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 4
[23] B. Sun and K. Saenko. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), 2016. 1
[24] Y .-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 1, 2, 4, 5, 6, 7, 8
[25] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 1
[26] Z. Wu, X. Han, Y .-L. Lin, M. G. Uzunbas, T. Goldstein, S. N. Lim, and L. S. Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), 2018. 2, 6, 7
[27] F. Y u and V . Koltun. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), 2015. 1
[28] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 1, 7
[29] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 2
[30] X. Zhu, H. Zhou, C. Yang, J. Shi, and D. Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In Proceedings of the Euro