Flink(Pometheus监控)
简介
Flink发布监控全流程
入门
使用架构图

特点
能够监控进程内部的信息
规范化的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:
http_request_status{code='200',content_path='/api/path',environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2',environment='produment'} => [value1@timestamp1,value2@timestamp2...]每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
- http_request_status:指标名称(Metrics Name)
- {code='200',content_path='/api/path',environment='produment'}:表示维度的标签,基于这些Labels我们可以方便地对监控数据进行聚合,过滤,裁剪。
- [value1@timestamp1,value2@timestamp2...]:按照时间的先后顺序 存储的样本值。
查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围?
- CPU占用率前5位的服务有哪些?
Prometheus的架构

官网
Prometheus - Monitoring system & time series database
下载地址
Download | Prometheus
安装包
链接:https://pan.baidu.com/s/1pvbFCCLv6XekPk8h6o1nkA
提取码:yyds
--来自百度网盘超级会员V4的分享
使用
![]()
解压

部署情况
| master | node1 | node2 |
| prometheus pushgateway node exporter |
node exporter | node exporter |
修改prometheus.yml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['master:9090']
# 添加 PushGateway 监控配置
- job_name: 'pushgateway'
static_configs:
- targets: ['master:9091']
labels:
instance: pushgateway
# 添加 Node Exporter 监控配置
- job_name: 'node exporter'
static_configs:
- targets: ['master:9100', 'node1:9100', 'node2:9100']参数说明
- job_name:监控作业的名称
- static_configs:表示静态目标配置,就是固定从某个target拉取数据
- targets:指定监控的目标,其实就是从哪儿拉取数据。Prometheus会从http://hadoop202:9090/metrics上拉取数据。
Prometheus是可以在运行时自动加载配置的。启动时需要添加:--web.enable-lifecycle
修改配置如图

分发node_exporter
./xsync /home/bigdata/prome/node_exporter-1.2.2.linux-amd64/启动
启动prometheus
nohup ./prometheus --config.file=prometheus.yml > ./prometheus.log 2>&1 &启动pushgateway
nohup ./pushgateway --web.listen-address=":9091" > ./pushgateway.log 2>&1 &启动node_exporter(三台机器都启动)
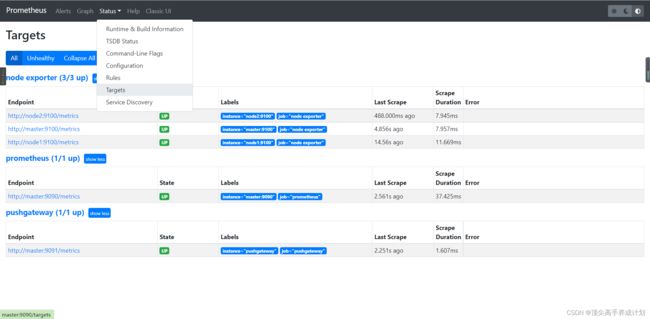
./node_exporter & 访问 prometheus的9090端口
点击对应的界面进行查看
使用PromSql
按时间查询
node_arp_entries[5m]m表示分钟
条件查询
node_arp_entries{device='ens33',instance='node1:9100'}使用正则表达式
node_arp_entries{device=~'^ens33'}使用条件
node_arp_entries{device=~'^ens33'}[1m] offset 10m对于历史数据累加
sum(node_arp_entries{device=~'^ens33'} offset 10m) by(device)
监控Flink
添加配置文件
添加依赖
org.apache.flink
flink-metrics-prometheus_2.12
1.13.5
provided
打包插件
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
在resource下面添加配置文件

log4j.properties
monitorInterval=30
# This affects logging for both user code and Flink
rootLogger.level = error
rootLogger.appenderRef.file.ref = MainAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.main.name = MainAppender
appender.main.type = RollingFile
appender.main.append = true
appender.main.fileName = ${sys:log.file}
appender.main.filePattern = ${sys:log.file}.%i
appender.main.layout.type = PatternLayout
appender.main.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.main.policies.type = Policies
appender.main.policies.size.type = SizeBasedTriggeringPolicy
appender.main.policies.size.size = 100MB
appender.main.policies.startup.type = OnStartupTriggeringPolicy
appender.main.strategy.type = DefaultRolloverStrategy
appender.main.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
flink-conf.yaml
##### 与Prometheus集成配置 #####
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
# PushGateway的主机名与端口号
metrics.reporter.promgateway.host: master
metrics.reporter.promgateway.port: 9091
## Flink metric在前端展示的标签(前缀)与随机后缀
metrics.reporter.promgateway.jobName: flink-metrics-ppg
#如果jobName启动二次,那么第二次的时候会有一个随机的名字
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
#这里表示多久推一次数据
metrics.reporter.promgateway.interval: 15 SECONDS启动程序的时候修改配置(由于加了
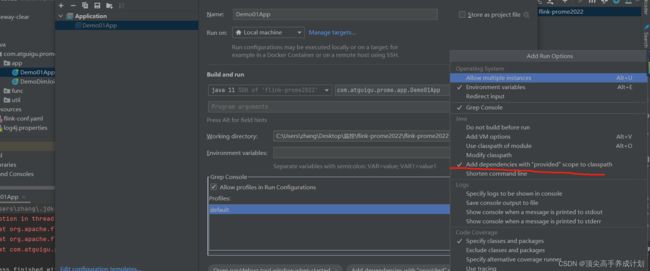
本地测试监控Flink
传入参数
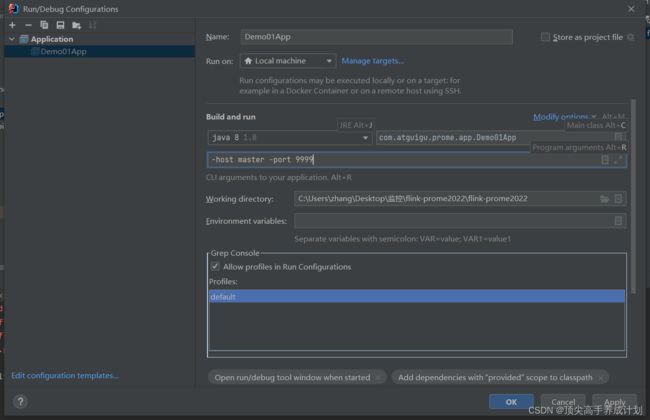
对应的应用程序(本地测试)
public class Demo01App {
public static void main(String[] args) throws Exception {
//0 调试取本地配置 ,打包部署前要去掉
// Configuration configuration=new Configuration(); //此行打包部署专用
// String resPath = Thread.currentThread().getContextClassLoader().getResource("flink-conf.yaml").getPath(); //本地调试专用
Configuration configuration = GlobalConfiguration.loadConfiguration("C:\\Users\\zhang\\Desktop"); //本地调试专用
//1. 读取初始化环境
configuration.setString("metrics.reporter.promgateway.jobName","demo01App");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 2. 指定nc的host和port
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 3. 接受socket数据源
DataStreamSource dataStreamSource = env.socketTextStream(hostname, port);
dataStreamSource.print();
//appname
env.execute("demo01App");
}
} 测试程序
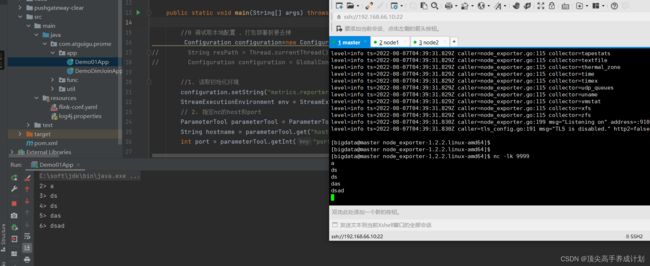
查看控制台然后可以看到采集过来的数据

发布集群测试监控Flink
先启动yarn
修改linux里面flink的配置

提交运行
./flink run -m node1:34982 -c com.atguigu.prome.app.Demo01App -p 2 ./flink-prome2022-1.1-SNAPSHOT.jar使用grafana
安装
解压
tar -zxvf grafana-enterprise-8.1.2.linux-amd64.tar.gz启动
nohup ./bin/grafana-server web > ./grafana.log 2>&1 &访问
监控Linux
先添加数据源

如果和前一分钟比,它们的时间不在变化那么这个时候说明Flink挂掉了
flink_jobmanager_job_uptime-flink_jobmanager_job_uptime offset 1m导入数据

得到的效果为
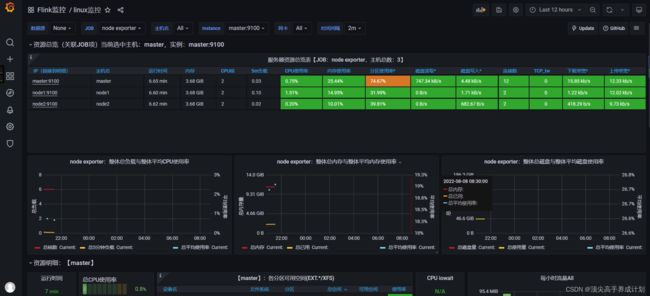
监控Flink

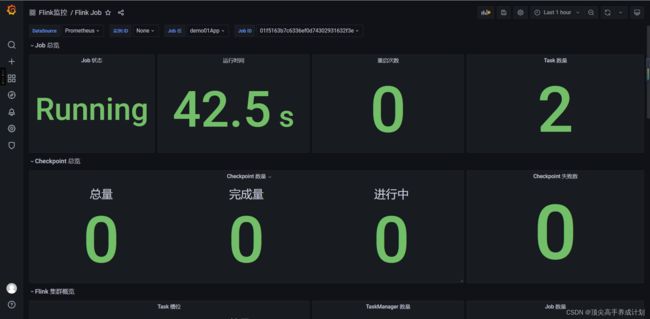
修改监控Flink配置文件的问题
原因:是pushgateway不会主动的清理数据,监控面板的判断有误,如果我们改成现在和过去一分钟的数据进行减法如果等于零,也就是没有数据更新的时候改成complete
原始值
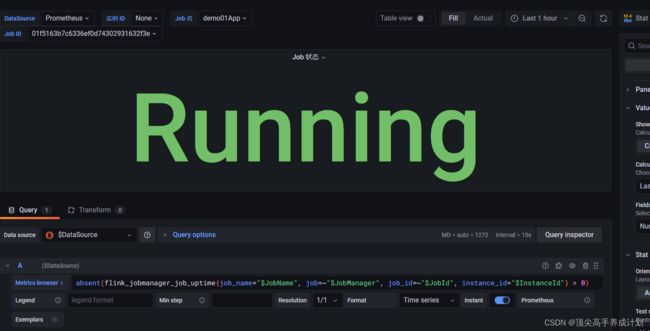
absent(flink_jobmanager_job_uptime{job_name="$JobName", job=~"$JobManager", job_id=~"$JobId", instance_id="$InstanceId"} > 0)修改后的值为
absent(flink_jobmanager_job_uptime{job_name="$JobName", job=~"$JobManager", job_id=~"$JobId", instance_id="$InstanceId"} - flink_jobmanager_job_uptime{job_name="$JobName", job=~"$JobManager", job_id=~"$JobId", instance_id="$InstanceId"} offset 1m > 0)当程序停止以后可以看到
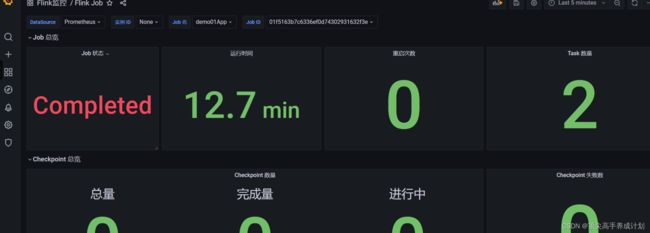
添加心跳图
因为只有图表才能发送报警

配置查询参数
flink_jobmanager_job_uptime - flink_jobmanager_job_uptime offset 1m效果图

Flink监控埋点
示例程序
public class Demo01App {
public static void main(String[] args) throws Exception {
//0 调试取本地配置 ,打包部署前要去掉
// Configuration configuration=new Configuration(); //此行打包部署专用
String resPath = Thread.currentThread().getContextClassLoader().getResource("flink-conf.yaml").getPath(); //本地调试专用
Configuration configuration = GlobalConfiguration.loadConfiguration("C:\\Users\\zhang\\Desktop"); //本地调试专用
//1. 读取初始化环境
configuration.setString("metrics.r+eporter.promgateway.jobName","demo01App");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
// 2. 指定nc的host和port
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 3. 接受socket数据源
DataStreamSource dataStreamSource = env.socketTextStream(hostname, port);
dataStreamSource.keyBy(new KeySelector() {
@Override
public String getKey(String s) throws Exception {
return s;
}
}).process(new ProcessFunction() {
Counter counter=null;
@Override
public void open(Configuration parameters) throws Exception {
//TODO 申明埋点
counter = getRuntimeContext().getMetricGroup().addGroup("mycount").counter("mycountTest");
}
@Override
public void processElement(String s, ProcessFunction.Context context, Collector collector) throws Exception {
// TODO 对于埋点的数据进行累加
counter.inc();
collector.collect(s);
}
}).print();
//appname
env.execute("demo01App");
}
}
使用Prometheus得到指标
http://master:9091/metrics
上图可以看到自定义的指标收集到了
窗口最大值,求缓存命中率
![]()
思想就是10分钟一个窗口,求出窗口的最大值,和上一个窗口进行减法然后就是10分钟的增量
自定义得到的数据
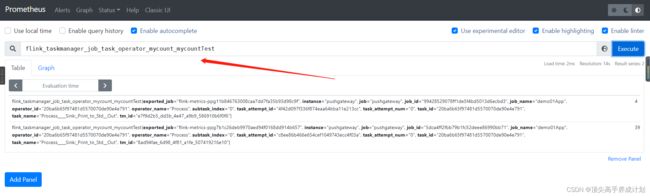
使用grafana展示自定义指标
添加图表,把查询Prometheus的查询得到的数据到grafana进行展示
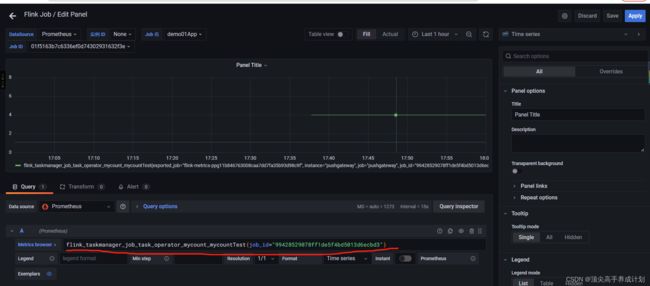
保存以后得到图标
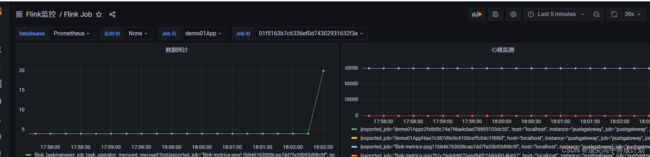
pushGetWay定期清理过期数据
由于pushGetWay在任务挂掉一会不会自动清理掉数据,它是由最新的数据覆盖久数据的形式,如果任务挂了以后,那么就没有新的数据进行覆盖了,这个时候就会有数据的残留,我们得进行处理
总结
pushGetWay不会自动的删除过期的数据,Promethus默认保存15天的数据,自己会对每一次拉去过来的数据加上一个时间戳