3. Hadoop-3.1.3伪分布式安装部署
环境说明:
主机名:cmcc01为例
操作系统:centos7
| 安装部署软件 | 版本 | 部署方式 |
| centos | 7 | |
| zookeeper | zookeeper-3.4.10 | 伪分布式 |
| hadoop | hadoop-3.1.3 | 伪分布式 |
| hive | hive-3.1.3-bin | 伪分布式 |
| clickhouse | 21.11.10.1-2 | 单节点多实例 |
| dolphinscheduler | 3.0.0 | 单节点 |
| kettle | pdi-ce-9.3.0.0 | 单节点 |
| sqoop | sqoop-1.4.7 | 单节点 |
| seatunnel | seatunnel-incubating-2.1.2 | 单节点 |
| spark | spark-2.4.8 | 单节点 |
1.下载Hadoop:
官网:https://archive.apache.org/dist/hadoop/common/
# 解压安装包
tar -zxvf /opt/package/hadoop-3.1.3.tar.gz -C /opt/software/2.配置环境变量
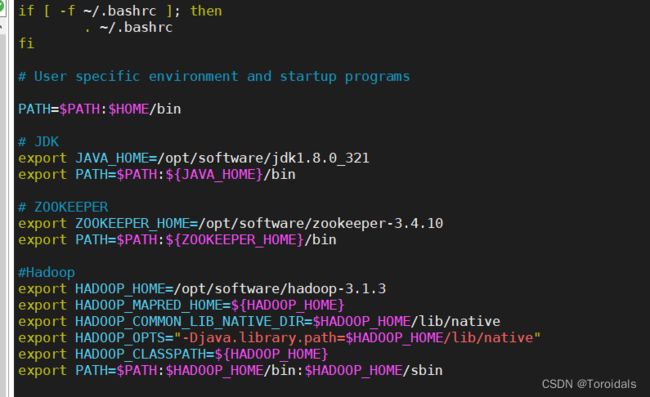
vim ~/.bash_profile
# JDK
export JAVA_HOME=/opt/software/jdk1.8.0_321
export PATH=$PATH:${JAVA_HOME}/bin
# ZOOKEEPER
export ZOOKEEPER_HOME=/opt/software/zookeeper-3.4.10
export PATH=$PATH:${ZOOKEEPER_HOME}/bin
#Hadoop
export HADOOP_HOME=/opt/software/hadoop-3.1.3
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_CLASSPATH=${HADOOP_HOME}
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使用环境变量生效
source ~/.bash_profile3.安装部署
cd /opt/software/hadoop-3.1.3/etc/hadoop1.设置环境变量
vim hadoop-env.sh
# 添加以下内容
export JAVA_HOME=/opt/software/jdk1.8.0_321
export HADOOP_HOME=/opt/software/hadoop-3.1.3
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.配置 core-site.xml
注意:hdfs://cmcc01:9001 中 cmcc01 需要修改为自己的主机名
fs.default.name
hdfs://cmcc01:9001
hadoop.tmp.dir
/opt/software/hadoop-3.1.3/data/tmp
io.file.buffer.size
1024
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
3.配置 hdfs-site.xml
dfs.namenode.name.dir
/opt/software/hadoop-3.1.3/dfs/name
dfs.namenode.data.dir
/opt/software/hadoop-3.1.3/dfs/data
dfs.replication
1
replications num
dfs.permissions.enabled
false
Canceling permission Check
4.配置 yarn-site.xml
注意:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
yarn.resourcemanager.hostname
cmcc01
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
10000
yarn.nodemanager.resource.memory-mb
3072
yarn.scheduler.minimum-allocation-mb
1024
yarn.scheduler.maximum-allocation-mb
3072
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
5.配置 mapred-site.xml
注意:
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
mapreduce.jobhistory.address
cmcc01:10020
mapreduce.jobhistory.webapp.address
cmcc01:19888
mapreduce.map.memory.mb
1024
mapreduce.reduce.memory.mb
1024
mapreduce.map.java.opts
-Xmx512m
mapreduce.reduce.java.opts
-Xmx512m
4.格式化nameNode
hadoop namenode -format5.启动集群
/opt/software/hadoop-3.1.3/sbin/start-all.sh增加启动和停止脚本
# 启动脚本:
vim /opt/software/start_hadoop_server.sh
#!bin/bash
# 启动hadoop
${HADOOP_HOME}/sbin/start-all.sh# 停止脚本:
vim /opt/software/stop_hadoop_server.sh
#!bin/bash
# 启动hadoop
${HADOOP_HOME}/sbin/stop-all.sh6.查看是否启动成功
查看yarn: http://192.168.137.233:8088
注意:ip替换为你自己的

查看hdfs:http://192.168.137.233:9870

7.运行hadoop自带例子
mkdir input
cp /opt/software/hadoop-3.1.3/etc/hadoop/*.xml input
# 创建hdfs目录
hadoop fs -mkdir -p hdfs://cmcc01:9001/user/root/input
# 上传文件到hdfs
hadoop fs -put input/* hdfs://cmcc01:9001/user/root/input
# 运行例子
hadoop jar /opt/software/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep hdfs://cmcc01:9001/user/root/input hdfs://cmcc01:9001/user/root/output 'dfs[az.]+'查看yarn状态: http://192.168.137.233:8088/cluster/scheduler

运行成功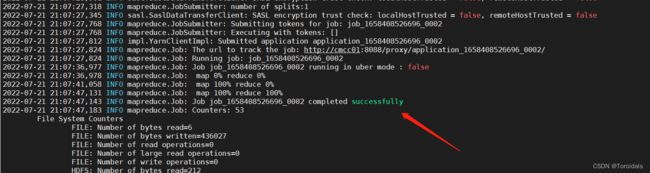
查看运行结果
hadoop fs -cat hdfs://cmcc01:9001/user/root/output/*