YOLOv3训练自己的数据集
写这篇博客的原因就是想记录一下自己使用YOLOv3时踩过的坑,之前一直都是使用pytorch版本的YOLOv3,比较熟悉,但是最近导师接了一个项目,需要使用darknet版本的YOLOv3,一直没有使用过这个框架,比较小众,因此处理很多的错,想简单的记录一下,方便自己以后的学习。
1安装darknet框架
git clone https://github.com/pjreddie/darknet.git其实也可以去下面这个网站下载压缩包,然后上传到服务器,用自己电脑跑代码的话,可以直接解压即可
https://github.com/pjreddie/darknet
下载完成之后,进入文件(我解压之后,将文件名darknet-master改为了darknet)
cd darknet输入 ./darknet
系统会输出 usage: ./darknet
然后使用make命令进行编译
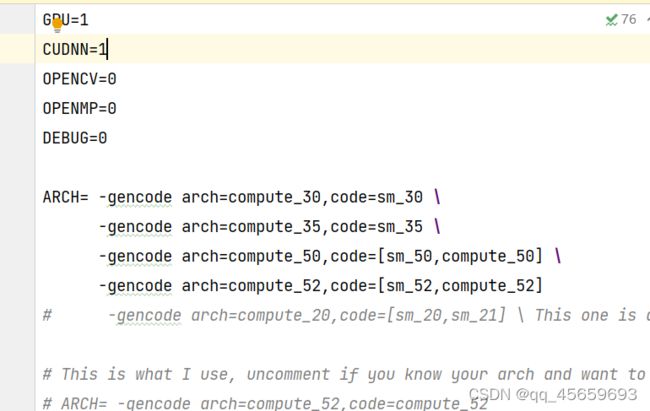
make编译完成,修改Makefile文件,如果使用GPU训练,修改如下,GPU和CUDNN都设置为1,否则边为0
2制作数据集
本次使用的是VOC数据集格式
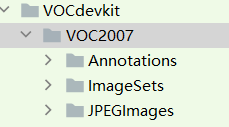
按照如上形式制作数据集,并放在scripts文件夹下
使用如下代码,命名为test1.py,放在VOC2007文件夹下,运行代码,将生成四个文件:train.txt,val.txt,test.txt和trainval.txt。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()结果如下:
在scripts文件下新建xinjianlabel.py,并把下列代码复制进去,然后会生成label文件夹,和2007-train等文件
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 源代码sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] # 改成自己建立的myData
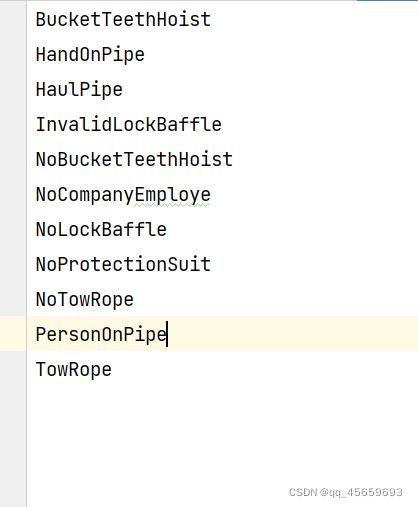
classes = ["BucketTeethHoist","HandOnPipe","HaulPipe","InvalidLockBaffle","NoBucketTeethHoist",
"NoCompanyEmploye","NoLockBaffle","NoProtectionSuit","NoTowRope",
"PersonOnPipe","TowRope"] # 改成自己的类别
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % (image_id)) # 源代码VOCdevkit/VOC%s/Annotations/%s.xml
out_file = open('VOCdevkit/VOC2007/labels/%s.txt' % (image_id), 'w') # 源代码VOCdevkit/VOC%s/labels/%s.txt
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC2007/labels/'): # 改成自己建立的myData
os.makedirs('VOCdevkit/VOC2007/labels/')
image_ids = open('VOCdevkit/VOC2007/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('VOCdevkit/VOC2007/%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC2007/JPEGImages/%s.jpg\n' % (wd, image_id))
convert_annotation(year, image_id)
list_file.close()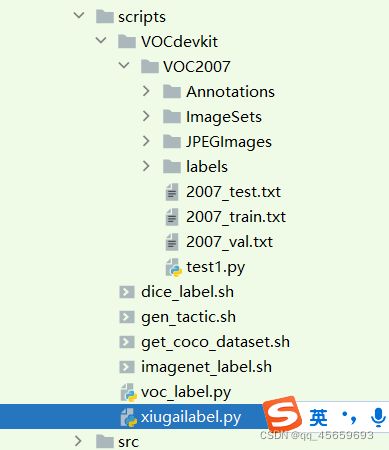
三局部修改
1、 修改cfg/voc.data

根据自己的路径修改,一定是绝对路径,修改自己的类别数
2、修改data/voc.names
根据自己的修改
3.修改参数文件cfg/yolov3-voc.cfg
ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。一定注意,是三处
每个地方都必须要改2处, filters:3*(5+len(classes));
其中:classes: len(classes) = 1,这里以单个类dog为例
filters = 18
classes = 1
可修改:random = 1:原来是1,显存小改为0。(是否要多尺度输出。)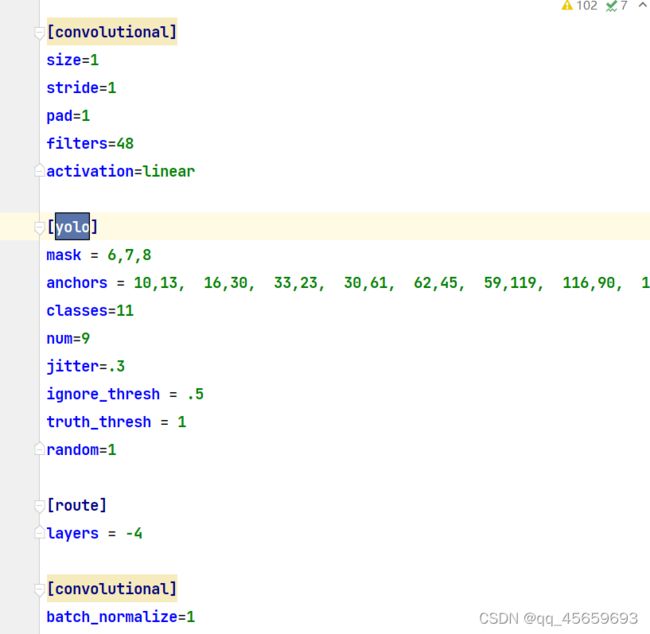
四开始训练
wget https://pjreddie.com/media/files/darknet53.conv.74
下载预训练权重
使用如下命令开始训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
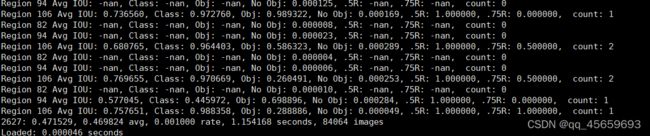
9798是迭代次数,0.370096是loss 0.451929是平均loss,0.001是学习率 3.3s是当前批次花费的总时间,627072images是截止到当前,训练图片数。
Region xx: cfg文件中yolo-layer的索引;
Avg IOU:当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1;
Class: 标注物体的分类准确率,越大越好,期望数值为1;
obj: 越大越好,期望数值为1;
No obj: 越小越好;
.5R: 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。