pytorch-geometric笔记
这篇博客是我学习pytorch-geometric(正文将以PyG代替)时做的笔记,有错误的地方在所难免,欢迎指正,非常感谢。
参考pytorch-geometric官网
1 图数据处理
1.1 创建自己的图数据
PyG创建图的方式很简单,假设我们有一张无向无权图,它包含3个结点和2条边,如下图所示:
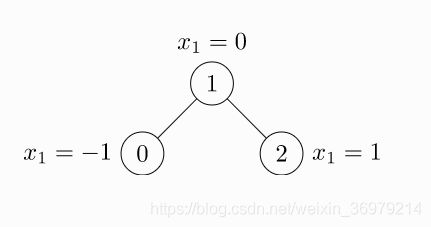
在数据结构里面我们创建一张图,至少需要指定其结点、 边等信息。PyG也不例外,用PyG创建一张图,可以给图指定如下的信息

x 表示结点的特征。二维矩阵, shape: [结点个数, 结点的特征维度]
edge_index表示边的信息。这个有点反人类,二维矩阵,shape[2, 边的条数]。 比如我们有三条边(0,1)(0, 2), (1, 2) ,那么这个矩阵将表示成
[
[0, 0, 1],
[1, 2, 2]
]
每一列表示一条边
edge_attr 表示边的属性,例如权重,结点之间的关联程度等信息。 二维矩阵,shape[边数, 边的特征维度]
y 表示结点的标签,二维矩阵,shape[结点个数, 标签的维度]。当标签的维度大于1时,就成了多标签问题了
注意!在创建图的时候,这些属性不是都要指定的,根据需要指定就好,甚至可以一个都不指定(空图)
现在可以开始创建我们的第一张图了 (根据上面那张图)
import torch
from torch_geometric.data import Data # 用来创建图
# 三个结点的特征, 特征维度为1
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 边
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
# 每个结点的标签, 假设我们只有两个标签0和1
y = torch.tensor([[0], [0], [1]])
# 创建图
data = Data(x=x, edge_index=edge_index, y=y)
print(data)
输出结果:
Data(edge_index=[2, 4], x=[3, 1], y=[3, 1])
我们还可以从data中获取更多信息
# 结点个数
print(data.num_nodes)
# 边数
print(data.num_edges)
# 是否为有向图
print(data.is_directed())
# 是否包含孤立结点
print(data.contains_isolated_nodes())
# 结点的特征数
print(data.num_node_features)
输出
3
4
False
False
1
1.2 使用PyG提供的数据集
PyG中提供了大量的数据集供我们使用,比如Cora,Citeseer, Pubmed等经典的数据集。我们可以使用TUDataset轻松加载数据,只需要指定数据集在你本地的存储位置以及你要加载的数据集的name
接下来我们尝试加载ENZYMES数据集,它包含600张图,六个类别。
import torch
from torch_geometric.data import Data
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='./dataset/ENZYMES', name='ENZYMES')
# 图的个数
print(len(dataset))
# 类别
print(dataset.num_classes)
# 结点特征
print(dataset.num_node_features)
输出
Downloading https://www.chrsmrrs.com/graphkerneldatasets/ENZYMES.zip
Extracting dataset\ENZYMES\ENZYMES\ENZYMES.zip
Processing...
Done!
600
6
3
这样,我们就完成了数据集的加载。事实上,TUDataset的功能远远不止这些,我们还可以做更多的事情!稍微look一下它的源码。
def __init__(self, root, name, transform=None, pre_transform=None,
pre_filter=None, use_node_attr=False, use_edge_attr=False,
cleaned=False):
self.name = name
self.cleaned = cleaned
super(TUDataset, self).__init__(root, transform, pre_transform,
pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0])
if self.data.x is not None and not use_node_attr:
num_node_attributes = self.num_node_attributes
self.data.x = self.data.x[:, num_node_attributes:]
if self.data.edge_attr is not None and not use_edge_attr:
num_edge_attributes = self.num_edge_attributes
self.data.edge_attr = self.data.edge_attr[:, num_edge_attributes:]
可以看到我们还可以对数据进行transform和pretransform,使用结点属性等等
对拿到的数据集进行划分,shuffle等
from torch_geometric.dataset import TUDataset
dataset = TUDataset(root='./dataset/ENZYMES', name='ENZYMES')
# 训练数据集
dataset_train = dataset[:540]
dataset_train = dataset_train.shuffle()
# 测试数据集
dataset_test = dataset[540:]