大数据基础之Hadoop(四)——Yarn
作者:duktig
博客:https://duktig.cn (文章首发)
优秀还努力。愿你付出甘之如饴,所得归于欢喜。
本篇文章源码参看:https://github.com/duktig666/big-data
Yarn 资源调度器
Hadoop系列
-
大数据基础之Hadoop(一)—— Hadoop概述
-
大数据基础之Hadoop(二)—— HDFS
-
大数据基础之Hadoop(三)—— MapReduce
-
大数据基础之Hadoop(四)——Yarn
Yarn 概述
思考:
- 如何管理集群资源?
- 如何给任务合理分配资源?
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
Yarn 基础架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
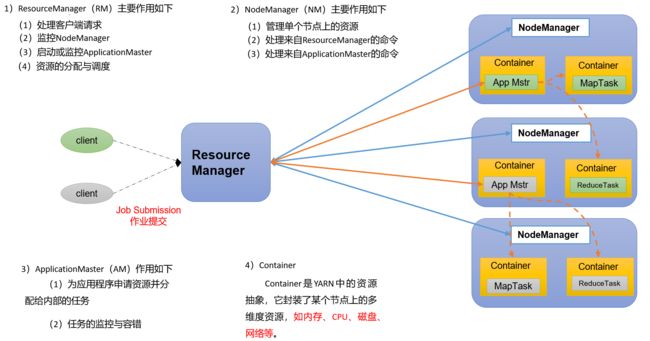
Yarn工作机制

详细流程:
(1)MapReduce 程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
作业提交全过程
HDFS、YARN、MapReduce三者关系

作业提交过程之YARN
参看上文:Yarn工作机制
作业提交过程之HDFS & MapReduce

作业提交全过程详解
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
Yarn调度器和调度算法
目前,Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。
- Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
- CDH框架默认调度器是Fair Scheduler。
具体设置详见:yarn-default.xml文件
<property>
<description>The class to use as the resource scheduler.description>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
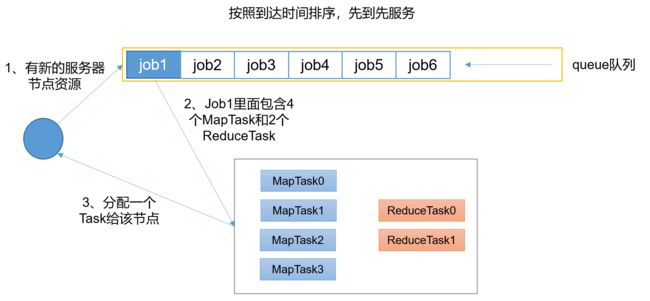
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
容量调度器(Capacity Scheduler)
Capacity Scheduler是 Yahoo 开发的多用户调度器。

特点:
1、多队列:每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
2、容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
3、灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
4、多租户:
- 支持多用户共享集群和多应用程序同时运行。
- 为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
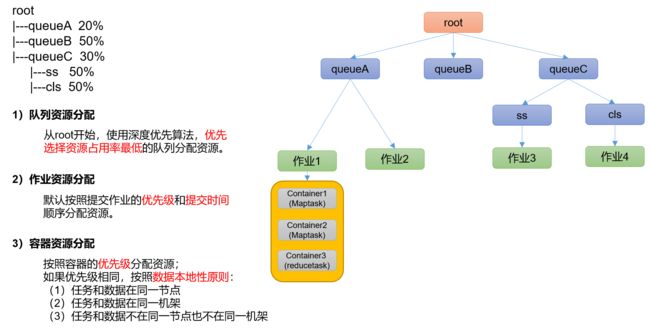
容量调度器资源分配算法:
公平调度器(Fair Scheduler)
特点
Fair Schedulere是Facebook开发的多用户调度器。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oF4c2MM3-1635411196011)(C:\Users\rsw\AppData\Roaming\Typora\typora-user-images\image-20211009172355581.png)]
1)与容量调度器相同点
(1)多队列:支持多队列多作业
(2)容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
(3)灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
(4)多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
2)与容量调度器不同点
(1)核心调度策略不同
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比例大的
(2)每个队列可以单独设置资源分配方式
容量调度器:FIFO、DRF
公平调度器:FIFO、FAIR、DRF
公平调度器——缺额
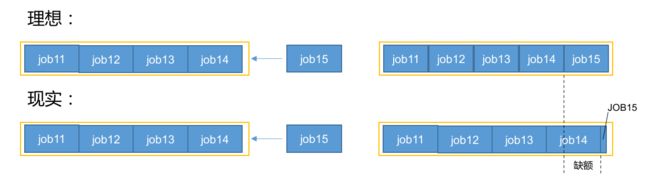
公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。
- 某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”
- 调度器会优先为缺额大的作业分配资源。
公平调度器队列资源分配方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YySngxL0-1635411196021)(C:\Users\rsw\Pictures\公平调度器队列资源分配方式.png)]
公平调度器资源分配算法
分配额度
root
|---queueA 20%
|---queueB 50%
|---queueC 30%
|---ss 50%
|---cls 50%
(1)队列资源分配
需求:集群总资源100,有三个队列,对资源的需求分别是:
queueA -> 20,queueB ->50,queueC -> 30
第一次算:100 / 3 = 33.33
queueA:分33.33 → 多13.33
queueB:分33.33 → 少16.67
queueC:分33.33 → 多3.33
第二次算:(13.33 + 3.33)/ 1 = 16.66
queueA:分20
queueB:分33.33 + 16.66 = 50
queueC:分30

(2)作业资源分配

3)DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:
假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU,100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
Yarn的调度器总结
- 调度器:FIFO/容量/公平
- apache 默认调度器 容量; CDH默认调度器 公平
- 公平/容量调度器,默认一个default队列 ,需要创建多队列
- 多队列选择(创建)
- 中小企业:hive spark flink mr
- 中大企业:业务模块:登录/注册/购物车/营销
- 队列好处:解耦 降低风险 11.11 6.18 降级使用=
- 每个调度器特点:
- 相同点:支持多队列,可以借资源,支持多用户
- 不同点:
- 容量调度器:优先满足先进来的任务执行
- 公平调度器,在队列里面的任务公平享有队列资源
- 生产环境怎么选调度器:
- 中小企业,对并发度要求不高,选择容量
- 中大企业,对并发度要求比较高,选择公平。
Yarn 常用命令
# 查看任务 yarn application
## 列出所有 Application
yarn application -list
## 根据 Application 状态过滤:yarn application -list -appStates (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
yarn application -list -appStates <appStates>
## Kill 掉 Application
yarn application -kill <application_id>
# 查看日志 yarn logs
## 查询 Application 日志
yarn logs -applicationId <ApplicationId>
## 查询 Container 日志
yarn logs -applicationId <ApplicationId> -containerId <ContainerId>
# 查看尝试运行的任务 yarn applicationattempt
## 列出所有 Application 尝试的列表
yarn applicationattempt -list <ApplicationId>
## 打印 ApplicationAttemp 状态
yarn applicationattempt -status <ApplicationAttemptId>
# 查看容器 yarn container
## 列出所有 Container
yarn container -list <ApplicationAttemptId>
## 打印 Container 状态
yarn container -status <ContainerId>
# 查看节点状态 yarn node
## 列出所有节点
yarn node -list -all
# 更新配置 yarn rmadmin
## 加载队列配置
yarn rmadmin -refreshQueues
# 查看队列 yarn queue
## 打印队列信息
yarn queue -status <QueueName>