软件工程独立项目作业报告
项目名称:Words Frequency
项目开发环境:Microsoft Visual Studio 2012 C# Windows Form
<<Part 01>>
Before you implement this project, Record your estimate about the time you will spend in each component of your program.
我的代码主要分为以下几个部分:
第1部分:界面按钮操作(主要代码为选择路径之后的查找工作代码,如下图显示)
第2部分:查找时需要用到的函数(如下图所示)

按照功能的需求可以分为以下几个阶段:
(1) 选择路径
(2) 依次访问路径下的所有文件(包括文件夹里的文件)
(3) 分割单个文件的内容,判断是否为单词并进行统计操作
(4) 按次数排序并显示所有结果
其中:估计时间使用比例最大的是第3部分,而且由于要搜索4种文件的内容,使得(如果仅使用单线程的话)需要独立的4个相似的循环来达到目的,这样就比较浪费时间(即理应是进行1次文件搜索并找出是符合4种文件格式的文件,而现在对于4种文件需要进行4次的独立搜索,大大增加了时间)
<<Part 02>>
After you had implemented this project, record the Actual time you spent in each component of your program.
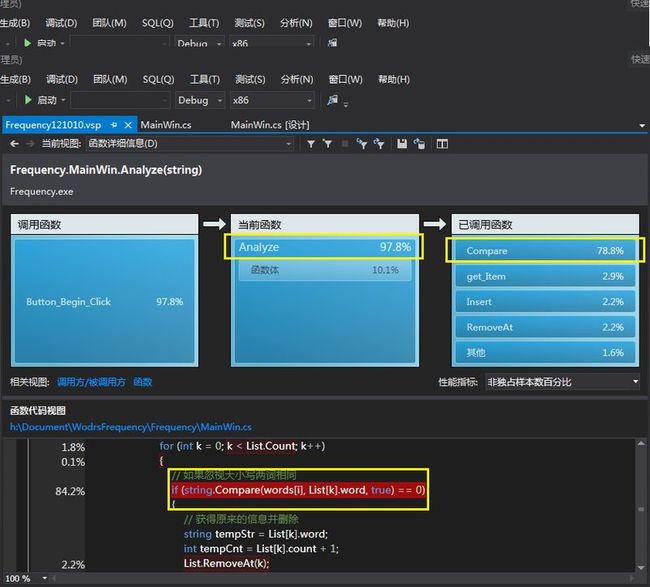
真实的时间占用总量及大致分配情况可以用VS2012的分析报告功能来获得(如下图所示)
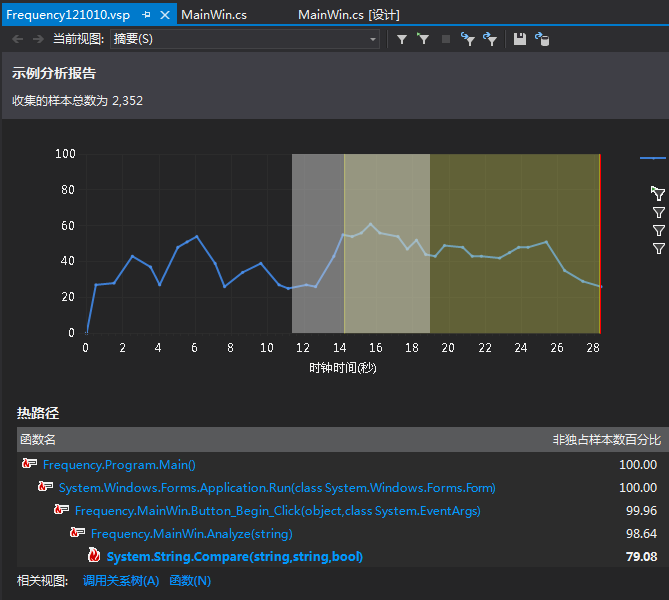
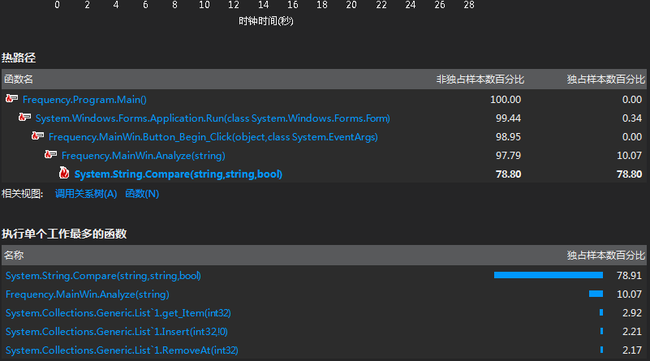
其中能看出各个阶段的时间使用和CPU使用率,以及使用频率最高的函数(如下图所示)
<<Part 03>>
Describe how much time you spent on improving the performance of your program, and show a performance analysis graph (Generated by VS2012 analysis tool), if possible, please show the most costly function in your program.
有分析报告可以看出,和预计的时间占用率最高的部分的情况有差异的是,使用时间最多的是MainWin.Analyze(string)这个函数,即是实现单词分析的功能部分,而不是定位访问文件的部分,而其中独立样本数百分比最高的是里面的Compare函数,高达79.08%,这说明遍历比较是造成这个程序运行时间较长的硬伤。

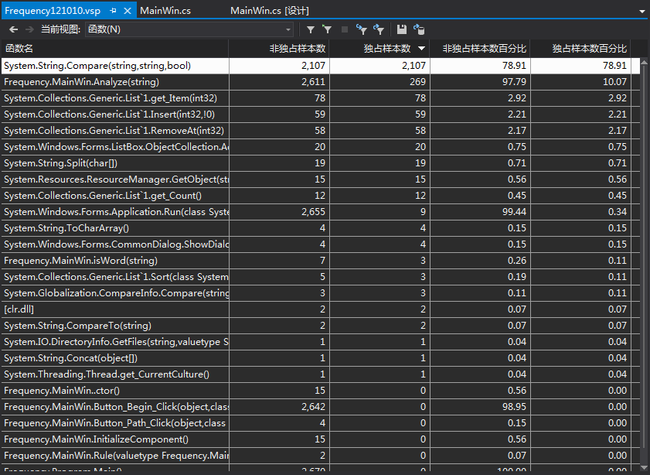
改进措施:由于在每找到一个单词之后程序都会去遍历以前已经在结构体数组里储存过的所有单词信息,因此当单词数目很大时,统计工作就会做很多重复性的工作,所以我的改进措施为:取到单词时首先储存而不进行判断(这样会使数组中的单词有很多重复,可能会造成一点储存空间占用过大的问题),然后当搜索完全部文件进行输出显示的时候,按顺序输出的同时进行判断,如果有所重复就在已经输出的结果上+1,如果没有就输出新的项目。这样的优点在于,数目庞大的遍历查找重复的工作不是在遍历文件的循环嵌套之内了,而变为两层单独的循环。事实证明这样的改动会比原来的程序快上很小一部分(还是取决于单词量的巨大),以下给出代码:
(1) 遍历某种格式的文件
foreach (var File in DI.GetFiles("*.txt", SearchOption.AllDirectories)) { string Content = String.Empty; using (StreamReader SR = new StreamReader(File.FullName)) { Content = SR.ReadToEnd(); Analyze(Content); } }
(2) 获取文件内容,分割内容为字符串数组
string[] words = Content.Split(' ', ',', '.', '<', '>', ':', ';', '/', '?', '[', ']', '{', '}', '!', '@', '#', '$', '%', '^', '&', '*', '(', ')',
'-', '_', '+', '=', '|', '\'', '\"', '\\', '\r', '\n'); // 搜索单词数组 for (int i = 0; i < words.Length; i++) { // 判断是否是单词 if (isWord(words[i])) { // 如果结构体表为空 if (List.Count == 0) addWord(words[i]); else { // 不为空时搜索结构体表 for (int k = 0; k < List.Count; k++) { // 如果忽视大小写两词相同 if (string.Compare(words[i], List[k].word, true) == 0) { // 获得原来的信息并删除 string tempStr = List[k].word; int tempCnt = List[k].count + 1; List.RemoveAt(k); // 新建并插入更新后的元素 wordsFrequency newWord = new wordsFrequency(); newWord.word = tempStr; newWord.count = tempCnt; List.Insert(k, newWord); break; } // 否则新建单词 if (k == List.Count - 1) { addWord(words[i]); break; } } } } }
(3) 判断是否是单词
private bool isWord(string word) { if (word.Length >= 3) { char[] letters = word.ToCharArray(); if ((letters[0] >= '0') && (letters[0] <= '9')) return false; else return true; } else return false; }
}
(4) 在统计数组中添加新的单词
private void addWord(string word) { wordsFrequency newWord = new wordsFrequency(); newWord.word = word; newWord.count = 1; List.Add(newWord); }
统计时用到的结构体及其数组:
private struct wordsFrequency { public int count; public string word; }; private List<wordsFrequency> List = new List<wordsFrequency>();
<<Part 04>>
Share your 10 test cases, and how did you make sure your program can produce the correct result.
以下是其中1次的测试结果:
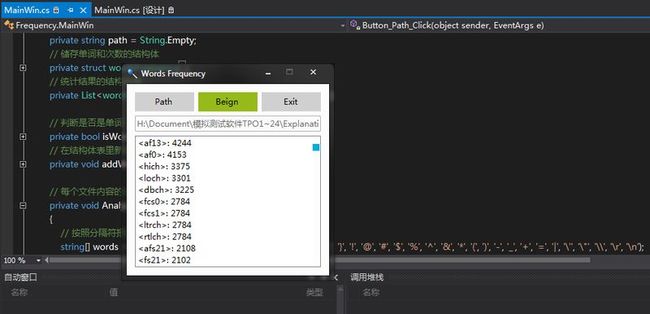
其中包含的特殊情况:
(1) 空文件夹
(2) 特殊单词的出现(如以数字开头的不算,大小写重复的不算等等)
(3) 特殊符号的出现(字符串分隔符的扩展)