Pytorch定义模型、修改模型、保存与读取模型保存
1. PyTorch的模型定义
1.1 PyTorch模型定义的方式
PyTorch中有三种模型定义方式,三种方式都是基于nn.Module建立的,我们可以通过Sequential,ModuleList和ModuleDict三种方式定义PyTorch模型。
- Module类是torch.nn模块里提供的一个模型nn.Module,是所有神经网络的基础模型:
1.1.1 Sequential
- nn.Sequential,可接收一个子模块的有序字典(OrderedDict)或者一系列子模块作为参数来逐一添加Module的实例
# 1.1 直接创建
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
'''
输出结果:
Sequential(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=10, bias=True)
)
'''
# 1.2 使用OrderedDict创建
import collections
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)
'''
输出结果:
Sequential(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
'''
1.1.2 ModuleList
疑问: forward怎么安排ModuleList中存储模块的顺序?
ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,然后也可以类似List那样进行append和extend操作。同时,子模块或层的权重也会自动添加到网络中来。(需要自己定义__init__和forward)
import torch.nn as nn
import torch
from torchsummary import summary
'''
注意: nn.ModuleList定义的不是模型,只是存储模块,需要按forward输出真正的模型顺序
'''
class Mymodel(nn.Module):
def __init__(self, args):
super(Mymodel, self).__init__() # Mymodel(子类)继承nn.Module(父类)的__init__()中属性
self.ModuleList = args
# 由于继承了父类的 def __call__(): 所以在Mymodel实例化的时候,forward会自动运行,无需调用
def forward(self, x):
# 遍历ModuleList搭建模型
# for model in self.ModuleList:
# x = model(x)
# 自定义顺序, 注意数据输入大小
x = self.ModuleList[0](x)
x = self.ModuleList[2](x)
return x
if __name__ == '__main__':
args = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
args.append(nn.Linear(256, 10)) # 类似List的append操作
x = torch.randn(1, 784)
net = Mymodel(args)
print('使用继承nn.Module类中__call__自动执行定义的forward函数:\n', net(x))
# 输出模型结构
print(summary(net, (1, 784)))
print('直接调用forward对象:\n', net.forward(x))
1.1.3 ModuleDict
ModuleDict和ModuleList的作用类似,只是ModuleDict能够更方便地为神经网络的层添加名称。(需要自己定义__init__和forward)
import torch.nn as nn
'''
注意: nn.ModuleList定义的不是模型,只是存储模块,需要按forward输出真正的模型顺序
'''
class Mymodel(nn.Module):
def __init__(self, args):
super(Mymodel, self).__init__() # Mymodel(子类)继承nn.Module(父类)的__init__()中属性
self.ModuleList = args
def forward(self, x): #
for model in self.ModuleList:
x = model(x)
return x
if __name__ == '__main__':
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加 'output': nn.Linear(256, 10) 层
print('访问linear层\n', net['linear'])
print('访问输出层\n', net.output)
print('访问所有的层\n', net)
'''
输出结果:
访问linear层
Linear(in_features=784, out_features=256, bias=True)
访问输出层
Linear(in_features=256, out_features=10, bias=True)
访问所有的层
ModuleDict(
(linear): Linear(in_features=784, out_features=256, bias=True)
(act): ReLU()
(output): Linear(in_features=256, out_features=10, bias=True)
)
'''
1.2 PyTorch不同模型定义方式的使用场景
| 模型定义方式 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| Sequential | 简单、易读、不需要写init和forward | 定义丧失灵活性 | 明确那些层,验证结果 |
| ModuleList | 搭建灵活,一行顶多行 | 需要定义init和forward | 在某个完全相同的层需要重复出现多次时,非常方便实现 |
| ModuleDict | 搭建灵活,一行顶多行 | 需要定义init和forward | 在某个完全相同的层需要重复出现多次时,非常方便实现 |
例如:当我们需要之前层的信息的时候,比如 ResNets 中的残差计算,当前层的结果需要和之前层中的结果进行融合,一般使用 ModuleList/ModuleDict 比较方便。
2. PyTorch的搭建U-Net模型
U-Net模型结构如下图所示,通过残差连接结构解决了模型学习中的退化问题,使得神经网络的深度能够不断扩展。
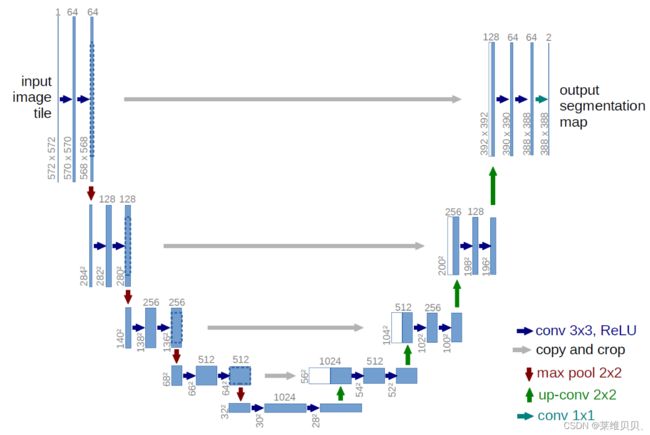
模型搭建基本方法:
- 模型的分析
- 模型块的实现
- 利用模型块组装模型
2.1 模型的分析
组成U-Net的模型块主要有如下几个部分:
1)每个子块内部的两次卷积(Double Convolution)
2)左侧模型块之间的下采样连接,即最大池化(Max pooling)
3)右侧模型块之间的上采样连接(Up sampling)
4)输出层的处理(OutConv)
5)除模型块外,还有模型块之间的横向连接,输入和U-Net底部的连接等计算,这些单独的操作可以通过forward函数来实现。
2.2 模型块的实现
实现四个模型块,根据功能,将其命名为:DoubleConv, Down, Up, OutConv。下面给出U-Net中模型块的PyTorch 实现:
DoubleConv模块的实现:
# DoubleConv 模块
# 主要实现 卷积核大小为3x3 的两次卷积
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
'''
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param mid_channels: 最小通道数
'''
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
# 第一次卷积:in_channels输入通道数,mid_channels输出通道数,kernel_size卷积核为3x3,添加设置在所有边界增加值为0的边距的大小
# padding=1,添加设置在所有边界增加值为0的边距的大小,在窗口为3*3步长为1情况下保证输出的图像形状大小与输入相同
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
# nn.BatchNorm2d() 进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# 第二次卷积
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
Down模块的实现:
# Down模块
# 主要实现下采样 maxpool 2x2
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
# 池化
nn.MaxPool2d(2),
# 进行两次卷积
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
Up模块的实现:
# Up模块
# 主要实现 上采样 up-conv 2x2
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
# scale_factor=2 大小扩大到原来的两倍,mode='bilinear'用线性插值
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# 进行两次卷积
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 非线性采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
OutConv模块的实现:
# 输出 conv 1x1
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
2.3 利用模块组装U-Net
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
# 两次卷积
x1 = self.inc(x)
# 下采样
x2 = self.down1(x1)
# 下采样
x3 = self.down2(x2)
# 下采样
x4 = self.down3(x3)
# 下采样
x5 = self.down4(x4)
# 上采样
x = self.up1(x5, x4)
# 上采样
x = self.up2(x, x3)
# 上采样
x = self.up3(x, x2)
# 上采样
x = self.up4(x, x1)
# 输出
logits = self.outc(x)
return logits
2.4 完整的U-Net代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
# DoubleConv 模块
# 主要实现 卷积核大小为3x3 的两次卷积
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
'''
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param mid_channels: 最小通道数
'''
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
# 第一次卷积:in_channels输入通道数,mid_channels输出通道数,kernel_size卷积核为3x3,添加设置在所有边界增加值为0的边距的大小
# padding=1,添加设置在所有边界增加值为0的边距的大小,在窗口为3*3步长为1情况下保证输出的图像形状大小与输入相同
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
# nn.BatchNorm2d() 进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# 第二次卷积
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
# Down模块
# 主要实现下采样 maxpool 2x2
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
# 池化
nn.MaxPool2d(2),
# 进行两次卷积
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
# Up模块
# 主要实现 上采样 up-conv 2x2
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
# scale_factor=2 大小扩大到原来的两倍,mode='bilinear'用线性插值
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# 进行两次卷积
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
# 非线性采样
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
'''
:param n_channels: channels这里3代表rgb
:param n_classes: 输出类别
:param bilinear: 上采样时候,决定采用线性算法还是非线性算法
'''
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
# 两次卷积
x1 = self.inc(x)
# 下采样
x2 = self.down1(x1)
# 下采样
x3 = self.down2(x2)
# 下采样
x4 = self.down3(x3)
# 下采样
x5 = self.down4(x4)
# 上采样
x = self.up1(x5, x4)
# 上采样
x = self.up2(x, x3)
# 上采样
x = self.up3(x, x2)
# 上采样
x = self.up4(x, x1)
# 输出
logits = self.outc(x)
return logits
if __name__ == '__main__':
# 输入为3个样本,大小为256*256的RGB数据即3*256*256
input_data = torch.randn(3, 3, 256, 256) # (样本数,通道数,高,宽)
print('输入的数据大小:\n', input_data.shape)
net = UNet(3, 1)
print('输出的数据:\n', net(input_data))
# 直接打印模型结构
# print(net)
# 用summary 打印模型结构,(3,256,256)表示(通道数,高,宽)
print(summary(net, (3, 256, 256)))
3. PyTorch的模型修改
3.1 修改模型
以pytorch官方视觉库torchvision预定义好的模型ResNet50为例,修该全连接层的输出大小;
import torch.nn as nn
import torchvision.models as models
from collections import OrderedDict
net = models.resnet50()
print('原最后的输出为1000类:\n', net.fc)
classifier_ten = nn.Sequential(OrderedDict([
('fc1', nn.Linear(2048, 128)),
('relu1', nn.Dropout(0.5)),
('fc2', nn.Linear(128, 10)),
('output', nn.Softmax(dim=1))
]))
# 修改全连接层即输出层
net.fc = classifier_ten
3.2 添加额外输入
在原有模型中添加额外输入的思路为:
将原模型添加输入位置前的部分作为一个整体,同时在forward中定义好原模型不变的部分,添加输入和后续层之间的链接关系;
案例:
以torchvision的resnet50模型为基础,任务还是10分类任务。不同点在于,我们希望利用已有的模型结构,在倒数第二层增加一个额外的输入变量add_variable来辅助预测。具体实现如下:
import torch.nn as nn
import torch
import torchvision.models as models
from collections import OrderedDict
# 添加外部输入
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc_add = nn.Linear(1001, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x, add_variable):
# net(x)为resnet50()
x = self.net(x)
# 增加一个额外的输入变量add_variable,辅助预测
# 添加 self.dropout(self.relu(x)) 的输出为1000维,add_variable.unsqueeze(1))为1维
# cat之后1001维度
x = torch.cat((self.dropout(self.relu(x)), add_variable.unsqueeze(1)), 1)
x = self.fc_add(x)
x = self.output(x)
return x
net = models.resnet50()
print('添加额外输入之前:\n', net)
model = Model(net)
print('添加额外输入之后:\n', model)
# 另外别忘了,训练中在输入数据的时候要给两个inputs:
# outputs = model(inputs, add_var)
3.2 添加额外输出
以resnet50做10分类任务为例,在已经定义好的模型结构上,同时输出1000维的倒数第二层和10维的最后一层结果。具体实现如下:
import torch.nn as nn
import torch
import torchvision.models as models
from collections import OrderedDict
# 添加额外输出
class Model(nn.Module):
def __init__(self, net):
super(Model, self).__init__()
self.net = net
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc1 = nn.Linear(1000, 10, bias=True)
self.output = nn.Softmax(dim=1)
def forward(self, x):
x1000 = self.net(x)
x10 = self.dropout(self.relu(x1000))
x10 = self.fc1(x10)
x10 = self.output(x10)
# 输出倒数第二层x1000,和最后一层x10
return x10, x1000
net = models.resnet50()
print('添加额外输出之前:\n', net)
model = Model(net)
print('添加额外输出之后:\n', model)
4. PyTorch的模型保存与读取
- 模型存储格式:pkl、pt、pth
- 模型存储内容:存储整个模型(模型结构和权重)model、只存储模型权重model.state_dict
- 多卡模型存储:torch.nn.DataParallel(model).cuda()
以resnet50模型的单卡保存和单卡加载为例:
import torch.nn as nn
import torch
import os
import torchvision.models as models
# os.environ用于指定使用的GPU,这里使用编号为0的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
model = models.resnet50(pretrained=True)
# 保存地址
save_dir = './models/resnet50.pkl'
# 保存整个模型
torch.save(model, save_dir)
# 读取整个模型
loaded_model = torch.load(save_dir)
save_dir = './models/resnet50_state_dict.pkl'
# 保存模型权重
torch.save(model.state_dict(), save_dir)
# 读取模型权重
loaded_dict = torch.load(save_dir)
loaded_model = models.resnet50()
# 定义模型的权重
# loaded_model.load_state_dict(loaded_dict)
loaded_model.state_dict = loaded_dict
print(loaded_dict)
5.总结
本次主要学习了PyTorch定义模型、利用自定义的模块快速搭建所需模型,修改模型、保存与读取模型保存。
- PyTorch模型主要有三种定义方式,分别是Sequential(简单)、ModuleList(灵活)和ModuleDict。
- 对于大型复杂的网络,通过构建模型块,再利用forward链接模型,从而可以快速搭建所需的模型。
- 修改规模,可有三种方式:直接修改模型层,添加额外输入,添加额外输出。
- 利用模型保存和读取函数,可以保存整个模型,也可以只保存模型的权重。
参考
https://blog.csdn.net/candice5566/article/details/114179718
https://blog.csdn.net/it_lxg123/article/details/88168019
https://blog.csdn.net/hehuaiyuyu/article/details/105676549
https://blog.csdn.net/weixin_41449637/article/details/91778456
https://github.com/datawhalechina/thorough-pytorch
https://relph1119.github.io/my-team-learning/#/pytorch_learning35/task05