深度学习(六)-卷积神经网络
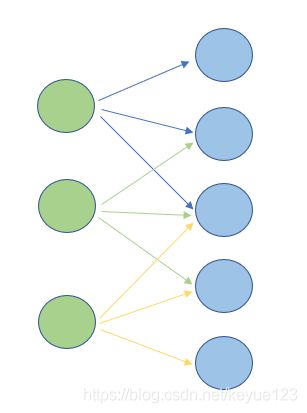
与全连接神经网络一样,卷积神经网络 ( C N N CNN CNN) 也是由神经元构成的,但是网络的层结构却不相同,在深度学习(四)-前馈神经网络中我们了解到,全连接神经网络由一系列隐藏层构成,每个隐藏层又是由很多个神经元构成,其中每个神经元都和前一层的所有神经元相关联,但是每一层中的神经元是相互独立的。而在卷积神经网络中的每一个神经元都只和下一层中某个局部窗口内的神经元相连,构成一个局部连接网络,组成卷积层,如下图所示:
1. 卷积
在了解卷积神经网络的时候,我们需要先知道什么是卷积,网上和书上各说纷纭,都有自己的解释,但是万变不离其宗,我也根据自己的资料阐述一下自己的理解。
在信号处理或图像处理中,经常使用一维或二维卷积。
一维卷积经常用在信号处理中,用于计算信号的延迟累积。假设一个信号发生器每个时刻 t t t 产生一个信号 x t x_t xt,其信息的衰减率为 w k w_k wk,即在 k − 1 k−1 k−1个时间步长后,信息为原来的 w k w_k wk 倍。那么在时刻 t t tt 收到的信号 y t y_t yt 为当前时刻产生的信息和以前时刻延迟信息的叠加,数学表现形式为:
y t = w 1 x t + w 2 x t − 1 + . . . + w k x t − k + 1 = ∑ k = 1 m w k x t − k + 1 {y_t} = {w_1}{x_t} + {w_2}{x_{t - 1}} + ... + {w_k}{x_{t - k + 1}} = \sum\limits_{k = 1}^m {{w_k}{x_{t - k + 1}}} yt=w1xt+w2xt−1+...+wkxt−k+1=k=1∑mwkxt−k+1
w 1 , w 2 . . . w k w_1, w_2...w_k w1,w2...wk 称为滤波器或卷积核,信号序列 x x x 和滤波器 w w w 的卷积定义为:
y = w ⊗ x y = w \otimes x y=w⊗x
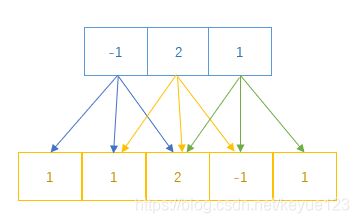
例:信号序列为: x = [ 1 , 1 , 2 , − 1 , 1 ] x = [1, 1, 2, -1, 1] x=[1,1,2,−1,1],滤波器为: w = [ 1 , 0 , − 1 ] w = [1, 0, -1] w=[1,0,−1],我们可以推出卷积:
w ⊗ x = [ ( 1 ∗ 1 + 1 ∗ 0 + 2 ∗ ( − 1 ) ) , ( 1 ∗ 1 + 2 ∗ 0 + ( − 1 ) ∗ ( − 1 ) ) , ( 2 ∗ 1 + ( − 1 ) ∗ 0 + 1 ∗ ( − 1 ) ) ] = [ − 1 , 2 , 1 ] w \otimes x = [(1*1+1*0+2*(-1)), (1*1+2*0+(-1)*(-1)), (2*1+(-1)*0+1*(-1))]=[-1, 2, 1] w⊗x=[(1∗1+1∗0+2∗(−1)),(1∗1+2∗0+(−1)∗(−1)),(2∗1+(−1)∗0+1∗(−1))]=[−1,2,1]
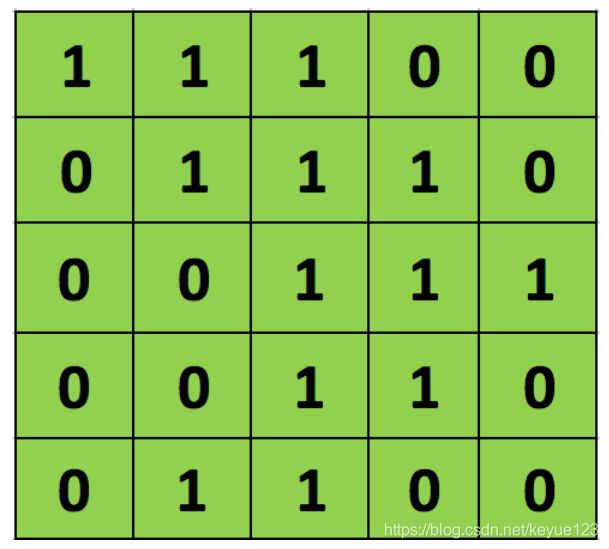
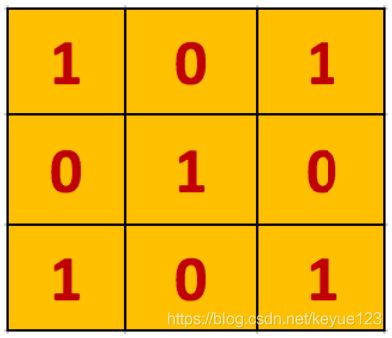
滤波器经过上述图像矩阵之后,以每次一个像素的速度向右和向下移动,对于每个位置,就变成了一维卷积计算,输出作为最终输出矩阵的一个元素,最终得到下面的二维卷积矩阵。
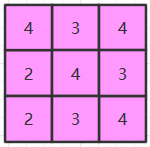
在卷积的标准定义基础上,还可以引入滤波器的滑动步长和零填充来增加卷积的多样性,可以更灵活地进行特征抽取,滤波器的步长是指滤波器在滑动时的时间间隔,零填充是在输入向量两端进行补零,图片引用自《神经网络与深度学习》。
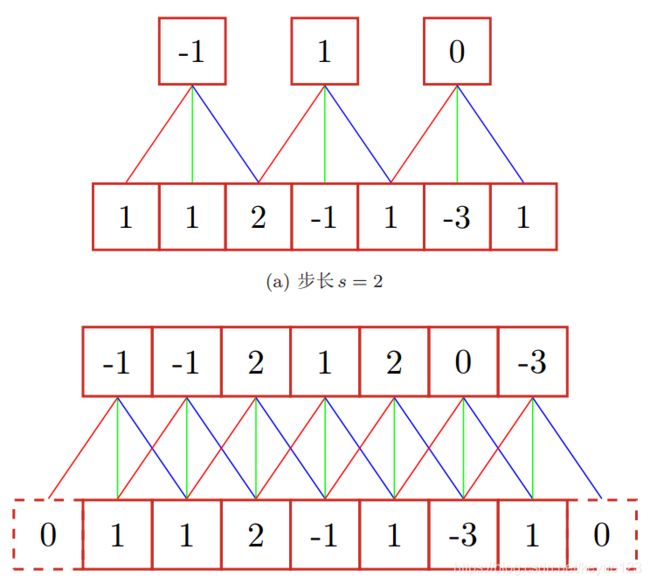
但是步长和零填充并不是随便取的,假设卷积层的输入数据大小为 n n n,卷积层神经元大小为 m m m,步长为 s s s, p p p 为边界填充 0 的数量,那么该卷积层的输出空间大小为 ( n − m + 2 p ) / s + 1 (n − m + 2p)/s + 1 (n−m+2p)/s+1,但是空间大小不能为小数,所以必须满足其为整数,否则说明神经元不能整齐对称地滑过输入数据体,这样的超参数设置是无效的,可以使用合理的零填充让设置变得合理 。比如输入是 7 X 7,滤波器是 3 X 3,步长是 1,填充的数量是 0,那么根据公式,就能得到 ( 7 − 3 + 2 ∗ 0 ) / 1 + 1 (7-3+2*0)/1+1 (7−3+2∗0)/1+1 ,即输出的空间大小是 5 x 5。
2. 卷积神经网络
卷积神经网络主要结构有卷积层、池化层、全连接层,通过堆叠这些层结构形成了一个完整的卷积神经网络结构 。
2.1 卷积层
卷积层是卷积神经网络的核心,大多数计算都是在卷积层中进行的。卷积层中滤波器必须都是三维的,宽度,高度可以自己定义,但是一般都比较小,这样才可以充分的获取特征,但是深度必须与输入相同,这样在前向传播的时候,每个滤波器在输入数据的宽度和高度上滑动,然后在深度方向上层叠起来就形成了卷积层的输出。
根据卷积的定义,卷积层有两个很重要的性质:1. 局部连接。在卷积层中的每一个神经元都只和下一层中部分窗口内的神经元相连,构成一个局部连接网络。2. 参数共享。在卷积层使用参数共享可以有效地减少参数的个数,因为相同的滤波器能够检测出不同位置的相同特征,假如一个卷积层的输入是 20 x 20 x 32 ,那么其中神经元的个数就是 20 x 20 x 32 = 12800 ,如果窗口大小是 3 x 3,而输入的数据的深度是 10 ,那么每个神经元就有 3 x 3 x 10 = 90 个参数,这样合起来就有 12800 x 90 = 1152000 个参数,单单一层
卷积就有这么多参数,这样运算速度显然是特别慢的,而根据之前介绍的,一个滤波器检测出空间位置 ( x 1 , y 1 ) (x_1, y_1) (x1,y1)处的特征,那么也能够有效检测出 ( x 2 , y 2 ) (x_2,y_2) (x2,y2) 位置的特征,所以就可以用相同的滤波器来检测相同的特征,基于这个假设,我们就能够有效减少参数个数,如上面这个例子,一共有 32 个滤波器,这使得输出体的深度是 32 ,每个滤波器的参数为 3 x 3 x 10 = 90 ,总共的参数就有32 x 90 = 2880 个,极大减少了参数的个数。
P y t o r c h Pytorch Pytorch 中二维卷积层 (常用二维) 表示为 n n . C o n v 2 d ( i n _ c h a n n e l s , o u t _ c h a n n e l s , k e r n e l _ s i z e , s t r i d e = 1 , p a d d i n g = 0 , d i l a t i o n = 1 , g r o u p s = 1 , b i a s = T r u e ) nn.Conv2d(in\_channels, out\_channels, kernel\_size, stride=1, padding=0, dilation=1, groups=1, bias=True) nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True)
参数解释:
i n _ c h a n n e l s ( i n t ) in\_channels(int) in_channels(int) – 输入信号的通道深度
o u t _ c h a n n e l s ( i n t ) out\_channels(int) out_channels(int) – 卷积产生的通道深度
k e r n e r _ s i z e ( i n t o r t u p l e ) kerner\_size(int or tuple) kerner_size(intortuple) - 卷积核的尺寸, i n t int int 表示宽高相同,元祖表示宽高不同
s t r i d e ( i n t o r t u p l e , o p t i o n a l ) stride(int or tuple, optional) stride(intortuple,optional) - 卷积步长
p a d d i n g ( i n t o r t u p l e , o p t i o n a l ) padding(int or tuple, optional) padding(intortuple,optional) - 输入的每一条边补充 0的层数
d i l a t i o n ( i n t o r t u p l e , o p t i o n a l ) dilation(int or tuple, optional) dilation(intortuple,optional) – 卷积核元素之间的间距
g r o u p s ( i n t , o p t i o n a l ) groups(int, optional) groups(int,optional) – 从输入通道到输出通道的阻塞连接数
b i a s ( b o o l , o p t i o n a l ) bias(bool, optional) bias(bool,optional) - 如果 b i a s = T r u e bias=True bias=True,添加偏置
输入: ( N , C i n , H , W ) (N, C_{in}, H, W) (N,Cin,H,W)
N N N: b a t c h _ s i z e batch\_size batch_size
C i n C_{in} Cin:表示 c h a n n e l channel channel 个数,
H H H:输入特征图高
W W W:输入特征图宽
输出: ( N , C o u t , H , W ) (N, C_{out}, H, W) (N,Cout,H,W)
N N N: b a t c h _ s i z e batch\_size batch_size
C i n C_{in} Cin:表示 c h a n n e l channel channel 个数,
H H H:输出特征图高
W W W:输出特征图宽
2.2 池化层
通常会在卷积层之间周期性插入一个池化层,其作用是逐渐降低数据体的空间尺寸,这样就能够减少网络中参数的数量 .减少计算资源耗费, 同时也能够有效地控制过拟合。
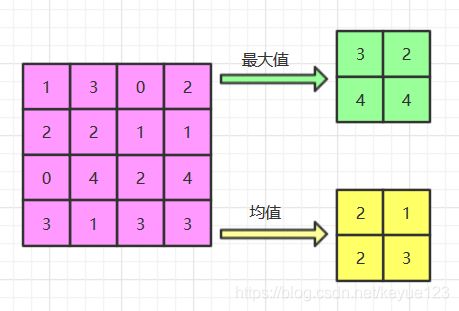
池化层常用的方式有两种:取一个区域内所有神经元的最大值;取区域内所有神经元的平均值。最常用的池化层形式是尺寸为 2 x 2 的窗口,滑动步长为 2 ,对图像进行下采样,将其中 75% 的信息都丢掉,选择其中最大的保留下来,这其实是因为我们希望能够更加激活里面的数值大的特征,去除一些噪声信息。下图为保留最大值和均值两种形式图形所示:
P y t o r c h Pytorch Pytorch 中二维池化层 (常用二维) 表示为 n n . M a x P o o l 2 d ( k e r n e l _ s i z e , s t r i d e = N o n e , p a d d i n g = 0 , d i l a t i o n = 1 , r e t u r n _ i n d i c e s = F a l s e , c e i l _ m o d e = F a l s e ) nn.MaxPool2d(kernel\_size, stride=None, padding=0, dilation=1, return\_indices=False, ceil\_mode=False) nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indices=False,ceil_mode=False)
参数解释:
k e r n e l _ s i z e ( i n t o r t u p l e ) kernel\_size(int or tuple) kernel_size(intortuple) - m a x _ p o o l i n g max\_pooling max_pooling 的窗口大小
s t r i d e ( i n t o r t u p l e , o p t i o n a l ) stride(int or tuple, optional) stride(intortuple,optional) - m a x _ p o o l i n g max\_pooling max_pooling 的窗口移动的步长。默认值是 k e r n e l s i z e kernel_size kernelsize
p a d d i n g ( i n t o r t u p l e , o p t i o n a l ) padding(int or tuple, optional) padding(intortuple,optional) - 输入的每一条边补充 0的层数
d i l a t i o n ( i n t o r t u p l e , o p t i o n a l ) dilation(int or tuple, optional) dilation(intortuple,optional) – 一个控制窗口中元素步幅的参数
r e t u r n _ i n d i c e s return\_indices return_indices - 如果等于 T r u e True True,会返回输出最大值的序号,对于上采样操作会有帮助
c e i l _ m o d e ceil\_mode ceil_mode - 如果等于 T r u e True True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
输入: ( N , C i n , H , W ) (N, C_{in}, H, W) (N,Cin,H,W)
N N N: b a t c h _ s i z e batch\_size batch_size
C i n C_{in} Cin:表示 c h a n n e l channel channel 个数,
H H H:输入特征图高
W W W:输入特征图宽
输出: ( N , C o u t , H , W ) (N, C_{out}, H, W) (N,Cout,H,W)
N N N: b a t c h _ s i z e batch\_size batch_size
C i n C_{in} Cin:表示 c h a n n e l channel channel 个数,
H H H:输出特征图高
W W W:输出特征图宽
2.3 全连接层
全连接层和之前介绍的全连接神经网络的结构是一样的, 每个神经元与前一层所有的神经元全部连接,而卷积神经网络只和输入数据中的一个局部区域连接, 并且输出的神经元共享参数。通常在进入全连接层之前,使用全局平均池化可以有效地降低过拟合。
2.4 卷积神经网络
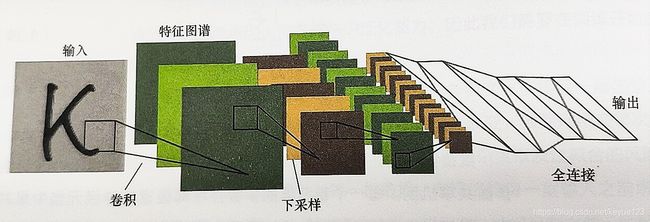
典型的卷积网络是将一些卷积层和 R e L U ReLU ReLU 层放在一起,有可能在 R e L U ReLU ReLU 层前面加上批标准化层 ,随后紧跟着池化层,再不断重复, 直到图像在空间上被缩小到一个足够小的尺寸 , 然后将特征图展开,连接几层全连接层,最后输出结果,如下图所示:
2.5 总结
输入层:一般而言,输入层的大小应该能够被 2 整除很多次,常用的数字包括32 , 64 , 96 和 224。
卷积层:卷积层应该尽可能使用小尺寸的滤波器,比如 3 x 3 或者 5 x 5,滑动步长取 1。还有一点就是需要对输入数据体进行零填充,这样可以有效地保证卷积层不会改变输入数据体的空间尺寸。如果必须要使用更大的滤波器尺寸,比如 7 x 7 ,通常用在第一个面对原始图像的卷积层上。
池化层:池他层负责对输入的数据空间维度进行下采样,常用的设置使用 2 x 2 的感受野做最大值池化,滑动步长取 2。另外一个不常用的设置是使用 3x3 的感受野,步长设置为2,一般而言,池化层的感受野大小很少超过 3,因为这样会使得地化过程过于激烈 ,造成信息的丢失,这通常会造成算法的性能变差。
零填充:零填充的使用可以让卷积层的输入和输出在空间上的维度保持一致,除此之外,如果不使用零填充电那么数据体的尺寸就会略微减少,在不断进行卷积的过程中,图像的边缘信息会过快的损失掉。
3 经典卷积神经网络结构
3.1 LeNet
L e N e t LeNet LeNet 是整个卷积神经网络的开山之作,一共有 7 层,其中 2 层卷积和 2 层池化层交替出现,最后输出 3 层全连接层得到整体的结果 。
3.2 AlexNet
A l e x N e t AlexNet AlexNet 是第一个现代深度卷积网络模型,不用预训练和逐层训练,首次使用了很多现代深度卷积网络的一些技术方法,赢得了 2012 年 I m a g e N e t ImageNet ImageNet图像分类竞赛的冠军。相对于 L e N e t LeNet LeNet, A l e x N e t AlexNet AlexNet 层数更深,使用了 8 层,同时使用了 11 X 11 的滤波器,而且第一次引入了激活层 R e L U ReLU ReLU ,在全连接层引入了 D r o p o u t Dropout Dropout 层防止过拟合 。
3.3 VGGNet
V G G N e t VGGNet VGGNet 使用了更小的滤波器,它只使用 3x3 的卷积滤波器和 2 x 2 的大地化层。同时使用了更深的结构,有 16~19 层网络。
3.4 GoogLeNet
G o o g L e N e t GoogLeNet GoogLeNet 也叫 I n c e p t i o n Inception Inception 网络。它一共有 22 层,但是它的参数却比 A l e x N e t AlexNet AlexNet 少了 12 倍,它同时使用 1 × 1、 3 × 3、 5 × 5等不同大小的卷积核,并将得到的特征映射在深度上拼接起来作为输出特征映射,而且没有全连接层。
3.5 残差网络
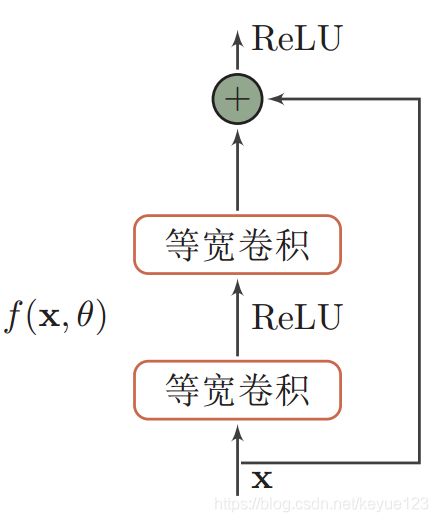
残差网络( R e s N e t ResNet ResNet) 是通过给非线性的卷积层增加直连边的方式来提高信息的传播效率,可以训练上百层乃至上千层的卷积网络。它将目标函数拆分成两部分: 恒等函数 x x x 和残差函数 h ( x ) − x h(x) − x h(x)−x,据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习。因此,原来的优化问题可以转换为:让非线性单元 f ( x , θ ) f(x, θ) f(x,θ) 去近似残差函数 h ( x ) − x h(x)−x h(x)−x,并用 f ( x , θ ) + x f(x, θ) + x f(x,θ)+x 去逼近 h ( x ) h(x) h(x)。下图就为一个简单的残差网络结构:
参考
- 直白介绍卷积神经网络
- 邱锡鹏:《神经网络与深度学习》 https://nndl.github.io/
- 廖星宇:《深度学习之pytorch》