02_JVM_调优
目录
1.cpu100%
2.内存100%问题
3.连接100%
前言:搞jvm调优【主要解决内存问题】,需要先搞定调优的区域
首先理解java的jvm运行时区域图 以及所用的jvm垃圾回收器 在【什么时间】 【哪里】 【做了什么】
问题:cpu100% 内存100% 数据库连接不够用(Connection问题) 都和jvm直接或间接关系
关于运行时图这些可以参考其他博主文章(主要都是大同小异),此处描述如何实战:JVM内存模型_小搬砖仔的博客-CSDN博客_jvm内存模型
1.cpu100%
出问题:一般是线程方面。cpu的工作是靠时间分片切换调度来实现线程的具体使用,大量的线程必然增加cpu的工作压力,具体体现就是cpu的使用率
时间:线上容易出问题的时间点观察,以及打印的日志内容反过来找可以看出一些问题
排查区域:jvm栈 命令jstack (如果linux 没有配置JAVA_HOME 需要配置才能使用)
相关工具:C:\Program Files\Java\jdk1.8.0_231\bin\jvisualvm.exe
linux系统演示(相关命令 top -H |grep java 或者top -H)
步骤1:jps 查询一下java应用 java -jar启动的一般是 jar 如果是tomcat启动 则是 BootStrap对应的
步骤2:用jstack 打印一下,生产建议打印到具体文件中下载看()或者直接命令查询关键字
1【查看java应用】
[root@localhost ~]# jps
1936 jar
1984 Jps2【直接看全部】
[root@localhost ~]# jstack -l 1936
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.231-b11 mixed mode):"Attach Listener" #28 daemon prio=9 os_prio=0 tid=0x00007fb228002000 nid=0x7dc waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLELocked ownable synchronizers:
- None"DestroyJavaVM" #27 prio=5 os_prio=0 tid=0x00007fb24c00a800 nid=0x791 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLELocked ownable synchronizers:
- None可以查到具体的线程名称:Attach Listener 如果没查到,可以根据后面打印的内容定位到具体线程
3.【下载到具体文件中】
[root@localhost ~]# jstack -l 1936 >/tmp/jstack20220928_01.txt
4.【根据关键字查询 如查 WAITING】
[root@localhost ~]# jstack -l 1936 | grep WAITING -A 20
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000f4017d68> (a
jstack 还有其他参数命令可选,可参考其他文章:jstack命令详解 - 知乎
jstack打印的栈信息,那么去看看具体是什么线程或者线程池在工作,反过来看配置是否合理
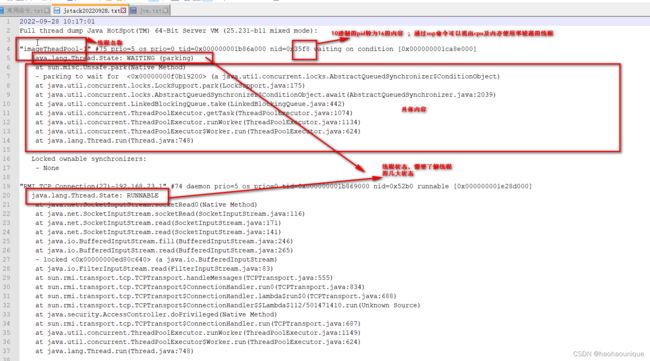
比如当前使用线程名称叫:imageTheadPool
然后全局搜代码,发现线程池这样的,参数合理么? 合理不,比如说某个人搞了很大的线程,或者说整体项目中其他任务也比较多,使用了线程池 等等...【当然了不管怎样调整,要保证生产和消费速度的合理性】,具体可以通过数字计算,当前业务需要 每秒/处理多少 实际线程池使用处理速度、连接池是不是够用、是不是有大事务的线程任务....诸如此类的
@Component
public class ThreadEKPool {
@Bean(name = "imageTheadPool")
public ThreadPoolTaskExecutor getThreadL(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setKeepAliveSeconds(60);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.setMaxPoolSize(8);
executor.setQueueCapacity(10);
executor.initialize();
return executor;
}
}另外【windows环境】:如果线上不好观察,本地观察有时也能看出一些问题吧;windows下可能更方便,不过大部分问题需要线上查
双击启动的应用进入
windows 则:win+r进入【此处是idea 控制台进入的,如遇到命令无法使用的情况,则需保留一个jdk 或者到jdk目录bin中去 ./jstack处理】
PS D:\pdfdemo> jps
PS D:\pdfdemo> jstack -l 10932
综合linux环境和windows环境的表现,大致就可以判断到底是什么线程或者某些线程导致的cpu飙升问题,这种飙升也要看是否合理,如果不合理则需要调,如拆分一些核心任务处理避免一个有问题全部跟着倒霉,如果合理那当前系统能否容忍....
2.内存100%问题
已下在分代GC中,常用的:-XX:+UseConcMarkSweepGC 开启这个默认的年轻代使用-XX:+UseParNew
出问题:jvm内存 系统内存
时间点:出问题的时间点,如果有监控的话可以看看到底是什么时间点出现的问题,具体时间点容易定位问题
jmap 配置 top -H (或top -H | grep java)命令使用
命令1:jmap -heap pid 堆内存的情况
命令2:jmap -histo:live pid 对象情况
命令2:jmap -dump:format=b,file=/tmp/jmap20220928.hrof pid
【1.找出java应用】
[root@localhost ~]# jps
1936 jar
2394 Jps【2.打印堆内存中使用情况】看是否要调整堆大小 -Xmx2048M -Xms:1024 ...注意初始堆不一定要和最大一样,如果有些比较坑底的系统中有多个服务导致堆内存不够用,或许你会碰到没有dump文件,然后系统进程莫名奇妙没了或者是某个线程莫名奇妙不运行了(和linux系统有关)
【参数内容仔细看,不一定要先搜是什么,提高理解 Max 最大 min最小 实在不行网络翻译,最后看看别人的讲解】
[root@localhost ~]# jmap -heap 1936这里关注:capacity 容量 used 已使用的 free 空闲的
Attaching to process ID 1936, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.231-b11using thread-local object allocation.
Mark Sweep Compact GCHeap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 209715200 (200.0MB)
NewSize = 4849664 (4.625MB)
MaxNewSize = 69861376 (66.625MB)
OldSize = 9830400 (9.375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 8454144 (8.0625MB)
used = 1725064 (1.6451492309570312MB)
free = 6729080 (6.417350769042969MB)
20.404951701792637% used
Eden Space:
capacity = 7536640 (7.1875MB)
used = 1065960 (1.0165786743164062MB)
free = 6470680 (6.170921325683594MB)
14.143703294836957% used
From Space:
capacity = 917504 (0.875MB)
used = 659104 (0.628570556640625MB)
free = 258400 (0.246429443359375MB)
71.83663504464286% used
To Space:
capacity = 917504 (0.875MB)
used = 0 (0.0MB)
free = 917504 (0.875MB)
0.0% used
tenured generation:
capacity = 18624512 (17.76171875MB)
used = 15136752 (14.435531616210938MB)
free = 3487760 (3.3261871337890625MB)
81.27328114691005% used14269 interned Strings occupying 1241016 bytes.
另外一个命令:jstat 命令 jstat -gc pid 多少毫秒打印 打印多少次
看起来很多,实际就那么几个英语单词 和区域看下面讲解
[root@localhost ~]# jstat -gc 1936 5000 20
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
896.0 896.0 643.7 0.0 7360.0 1144.7 18188.0 14782.0 42112.0 39720.1 5760.0 5317.8 138 0.206 2 0.067 0.274
896.0 896.0 643.7 0.0 7360.0 1144.7 18188.0 14782.0 42112.0 39720.1 5760.0 5317.8 138 0.206 2 0.067 0.274
896.0 896.0 643.7 0.0 7360.0 1144.7 18188.0 14782.0 42112.0 39720.1 5760.0 5317.8 138 0.206 2 0.067 0.274
带C的 则表示容量,理解本身就是单词:capacity
带U:则是已使用: used
开头则代表区域:S0区域 S1区域 E eden区 O old区 M 元空间大小(和方法区调优有关,后面讲解) CCSMX:最大压缩类空间大小 CCSC:当前压缩类空间大小 ; YGC 及 young GC(新生代)
YGCT young GC time T代表时间; FGC full GC ;FGCT full GC time GCT总的GC
综合S0C容量 S0U已使用
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
GC调整和当前系统有关,频繁的GC是否合理和当前系统有关,比如说某些系统内存不够,系统频繁触发GC来回收内存;有些系统则不希望频繁GC,那么势必调整堆大小和比例以达到各个区域的GC合理性
从jmap jstat 以及有条件使用jvisualvm 实时看看jvm内存 这样根据线上运行情况调整到一个合理值
调优建议给系统留下1-2G的空间够系统使用
-Xmx512M 最大堆大小
-Xms200M 初始堆大小(如果系统内存不够用建议,可以适当调小一些,让jvm自动去做堆内存扩容问题,比较多的是建议和最大堆一样,避免堆扩充问题,看具体情况,博主经历的项目是调小该值,不使用和最大值一样够项目平稳运行)
-Xmn400M 初始堆内存大小 默认是堆大小的3/8 可以适当调整到jmap jstat 等观察到的一个合理值-Xss256K 此值太大则创建的线程数减少,调小则会应发stackOverflow异常,默认jdk1.8 1024K,生产常用256K或者512K
【-XX:+UseConcMarkSweepGC】 垃圾回收算法的使用 新生代 UseParNew 老年代CMS,当然了开启了这个,建议开启老年代压缩功能,解决内存碎片化问题UseCompactAtFullCollection【-XX:+UseCompactAtFullCollection】 老年底压缩
【-XX:CMSInitiatingOccupancyFraction=60】老年代触发比例 如不希望老年代过多的触发,则可以调整到更大的比例;具体看项目希望多大触发FullGC
【-XX:+UseParallelGC=8】 GC回收线程数设置,默认是核心线程数,调多大看具体项目
【-XX:+MaxTenuringThreshold=15】 默认15标记升代 如果老年代空间够,可以适当调小 0-15之间的数值
jdk1.8 元空间的限制,主要是方法区调优:-XX:MetaspaceSize=20M 【 -XX:MaxMetaspaceSize=256M 】 建议设置最大值,初始默认值20M不去修改,元空间的扩容会产生GC回收垃圾,不设置最大值,有可能会导致方法区的内存泄漏问题
低版本的jdk则设置:【-XX:MaxPermSize=256大小】
【-XX:MaxDirectMemorySize=256M】 直接堆外内存大小,可以搜索其他博文查看具体含义,如果是文件比较多的操作,建议设置该值,默认是和最大堆内存(Xmx)一样(此处也会引发linux kill进程的问题,此处实际项目遇到过)
【-XX:+PrintGCDetails】 打印GC细节
【-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dumps/】 dump日志记录
【-XX:+DisableExplicitGC】禁用代码GC调用 System.gc
总结:
方法区-XX:MaxMetaspaceSize -Xss
堆区:-Xmx -Xms -Xmn MaxTenuringThreshold
堆外内存:MaxDirectMemorySize
其他:UseConcMarkSweepGC UseCompactAtFullCollection CMSInitiatingOccupancyFraction
PrintGCDetails HeapDumpOnOutOfMemoryError HeapDumpPath
如果找不到dump日志,系统死掉了或者某个进程没了,则需要查一下系统的kill记录(系统可能会根据当前 cpu 内存等情况将系统中某个pid给干掉)如下命令可以查到,或者搜其他博主的文章看看具体讲解
egrep -i -r 'killed process' /var/log
grep "Out of memory" /var/log/messages
3.连接100%
1.一般慢sql问题引发(解决慢sql问题),常见和任务有关,具体到的话从日志和jstack打出来的任务中去找;
首先确定当前系统每秒需要的连接数,可以通过线程的任务初步判断再增加个100%?
逐步调整,初始线程数和最大线程数
查看数据连接池配置:
#当前全部的连接数 show full processlist; #查询最大连接数 show variables like 'max_connections'; -- 设置最大连接数,根据需要进行设置
set global max_connections=200;
show variables like '%max_connections%';
具体看使用什么线程池以及配置
2.和线程配置有关,如果遇到cpu 100%也能导致线程池的任务不能很好的管理线程导致这个问题?
4 常用查询命令
jps
jstack -l pid >/tmp/jstack.txt
jmap -heap pid >/tmp/jmap.txt
jstat -gc pid 5000 20
以上,如有小伙伴可以补充的,可以私信后补充完善,争取不加班!!!!!!!!!
水平有限,持续改进中,喜欢点个收藏