YoloV2学习小总结
前言
首先,yolov2比yolov1改进的地方有许多,使得yolov2在性能指标上有很大的改进。
- 速度方面更快
- 召回率更高
下图是yolov2采用各种改进方法的mAP指标。
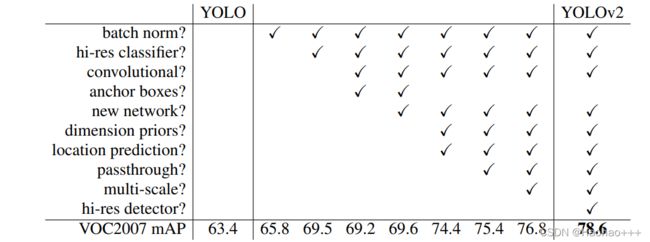
相比于yolov1的改进
yolov1
1. Better
1. Batch Normalization
Batch Normalization可以使模型在收敛方面速度更快,因为Batch Normalization有利于正则化的作用,所以可以不需要再添加任何正则化的操作。在yolov2中Batch Normalization在所有卷积层所添加,同时在mAP指标上提升了2%。
2. High Resolution Classifier
yolov1使用的分辨器是224 x 244的,这对于之后检测448 x 488图片的效果并不是很好,所以yolov2使用了更高的分辨率的预训练模型,在mAp上提升了4%。
3. Convolutional With Anchor Boxes
yolov1是在特征层中直接使用全连接层来预测边界框的位置。在RPN中,由于预测层是卷积的,RPN预测特征图中每个位置的这些偏移量,并使网络更容易学习。yolov2就借鉴了这一点。
在yolov2中,我们把全连接移除了,并使用了anchor box来预测边界框。首先yolov2移除了一个池化层,使得网络的输出有更高的分辨率,同时将448 x 488 的输入图片变成了 416 x 416的输入图片,因为这样做网络的输出是由14 x 14 变成了 13 x 13,在预测大物体时,大物体中心更容易落在中心的网络,而不是中心四个网络的附近。
在使用了anchor boxes后虽然mAp由69.5下降到了69.2,但是Recall由81%到88%。
4. Dimension Clusters
使用更好的anchor boxes可以使网络更加容易学习,但是现在的anchor boxes一般都是手工给出的。于是,yolov2使用k-means算法将训练集中的真实框进行聚类,最后选择了5种anchor box。yolov2使用的k-means算法不是使用传统的欧式距离,是因为欧式距离对于大的框来说误差更大,于是利用IOU作为指标进行聚类,公式如下:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 − IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
同时yolov2沿用了yolov1的做法,每个网格负责预测物体的中心,而且每个网络用了5种通过聚类得到的anchor box,训练阶段时yolov2就会使用与anchor box与真实框IOU最大的框来进行调整。
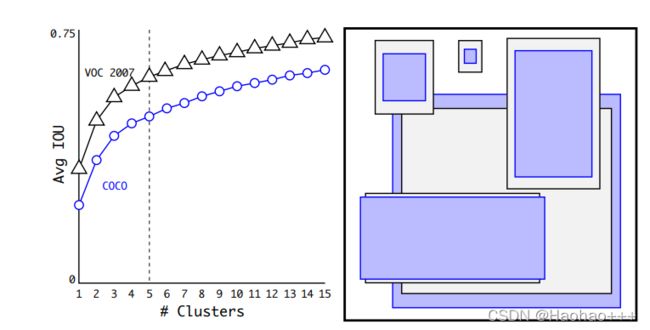
下图左边是k-means中平均IOU随K的值变化,右图是k-means算法在COCO数据集和VOC2007数据集得到的五个anchor boxes。
5. Direct location prediction
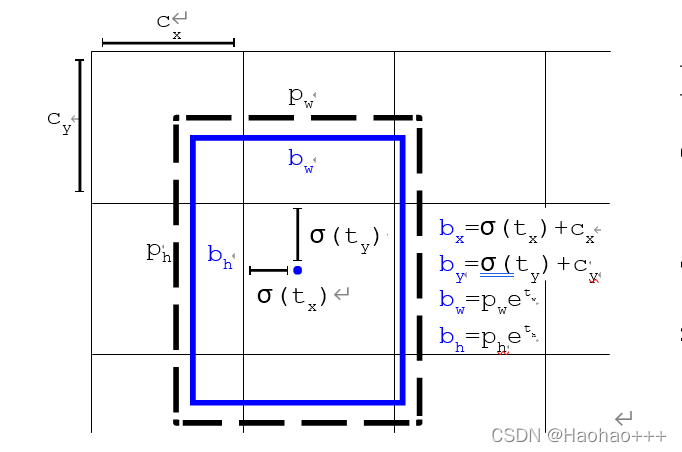
yolov2预测坐标时,使用如下公式:
b x = σ ( t x ) + c x b_x = σ(t_x) + c_x bx=σ(tx)+cx …(1)
b y = σ ( t y ) + c y b_y = σ(t_y) + c_y by=σ(ty)+cy …(2)
b w = p w e t w b_w = p_we^{t_w} bw=pwetw …(3)
b h = p h e t h b_h = p_he^{t_h} bh=pheth …(4)
其中:
t x , t y , t w , t y t_x, t_y, t_w, t_y tx,ty,tw,ty 为预测的中心点和宽高。
c x , c y c_x, c_y cx,cy 为网格的左上角坐标。
p w , p h p_w, p_h pw,ph 为其中一个anchor box的宽高。
σ ( ) σ() σ()代表经过sigmoid函数变换
第一、第二个公式经过sigmoid函数变换,将预测值缩放到[0, 1],将偏移量相对于网格,使得网络只能在网格内学习,就不用再网络外学习,使得yolov2对于yolov1学习更快。而加上 c x , c y c_x, c_y cx,cy 就可以得到真正的边界框的坐标。
第三、第四个公式,anchor box经过指数变换的微调就可以得到边界框的宽高。
经过anchor boxes的kmeans算法后,yolov2的Recall提升了5%。
6. Fine-Grained Features
yolov2是在13 x 13 的特征图上进行检测,这对于大物体是足够的,但是对于小物体可能还需要更细小的划分,所以yolov2提出了一种passthrough层来利用更精细的特征图,yolov2会在26 x 26的特征图上来对之后的特征层进行融合。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。对于26 × 26 × 512 的特征图,经passthrough层处理之后就变成了13 × 13 × 2048的新特征图。对于26 × 26 × 512的特征图,经passthrough层处理之后就变成了13 × 13 × 2048。这样做之后yolov2的性能有了2%的提升。
7. Multi-Scale Training
yolov2采用了多尺度训练以适应不同尺度大小的图片。过程就是每隔一定的轮次将图片大小改变,因为yolov2的下采样因子是32,所以需要32倍数大小的图片来进行训练。各个尺度大小模型的性能如下:

2. Faster
1. Darknet-19
Darknet-19的网络结构如下:

画红色框的部分是在目标检测中使用网络结构。
代码演示
来自下面这位大神
网址:https://www.maskaravivek.com/post/yolov2/
VOC2007数据集
链接:https://pan.baidu.com/s/1mhk3OItyGt5CuRcX8Nj3cw
提取码:a697