简简单单了解一下softmax与交叉熵
文章目录
- 1. softmax
- 2. 交叉熵
-
- 2.1 线性回归中的损失函数MSN
- 2.2 交叉熵
也看了不少softmax和交叉熵的文章了,不少文章对它们的来龙去脉做了比较清晰地梳理,有些文章讲得过于复杂,从信息量、相对熵(KL散度)讲到交叉熵,对于想要实际应用的同学来说,其实没有必要掌握它的来龙去脉,于是在此,对softmax和交叉熵的概念和公式进行简要说明,辅助以实际例子对它们具体说明。
1. softmax
softmax用于多分类过程中,它将多个神经元的输出,映射到 ( 0 , 1 ) (0,1) (0,1) 区间内,可以看成概率来理解,从而来进行多分类!假设我们有一个数组, V i V_i Vi 表示 V V V 中的第 i i i 个元素,那么这个元素的 softmax 值就是
S i = e V i ∑ j e V j S_i = \frac{e^{V_i}}{\sum_j e^{V_j}} Si=∑jeVjeVi
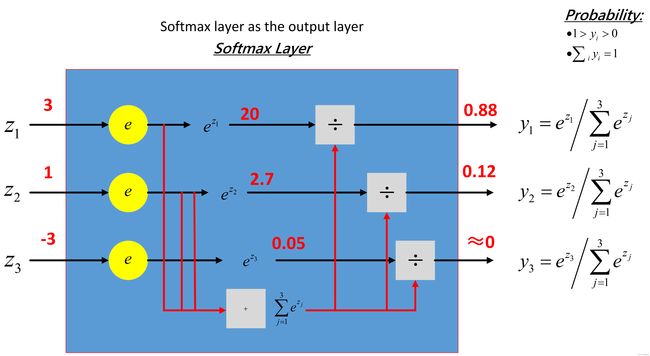
举个例子,假设有现在有3个数据,它们为[3,1,-3],经过softmax层之后,处理结果如下:
S 0 = e 3 e 3 + e 1 + e 3 = 0.87887824 S_0 = \frac{e^{3}}{e^{3}+e^{1}+e^{3}}=0.87887824 S0=e3+e1+e3e3=0.87887824
S 1 = e 1 e 3 + e 1 + e − 3 = 0.11894324 S_1= \frac{e^{1}}{e^{3}+e^{1}+e^{-3}}=0.11894324 S1=e3+e1+e−3e1=0.11894324
S 2 = e − 3 e 3 + e 1 + e − 3 = 0.00217852 S_2= \frac{e^{-3}}{e^{3}+e^{1}+e^{-3}}=0.00217852 S2=e3+e1+e−3e−3=0.00217852
实际应用中,使用softmax需要注意数值溢出的问题。因为有指数运算,如果V数值很大,经过指数运算后的数值往往可能有溢出的可能。所以,需要对 V 进行一些数值处理:即V中的每个元素减去V中的最大值。公式如下所示:
D = m a x ( V ) D = max(V) D=max(V)
S i = e V i − D ∑ j e V j − D S_i = \frac{e^{V_i - D}}{\sum_j e^{V_j - D}} Si=∑jeVj−DeVi−D
softmax实现代码如下所示:
import numpy as np
scores = np.array([3, 1, -3])
#原始函数操作
p = np.exp(scores) / np.sum(np.exp(scores))
print(p)
# 防止溢出操作
scores -= np.max(scores)
print(scores)
p = np.exp(scores) / np.sum(np.exp(scores))
print(p)
输出:
[0.87887824 0.11894324 0.00217852]
[ 0 -2 -6]
[0.87887824 0.11894324 0.00217852]
为了便于理解,再放一张softmax的计算流程:
2. 交叉熵
交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。
2.1 线性回归中的损失函数MSN
在线性回归问题中,常常使用MSE(Mean Squared Error)作为loss函数,比如:
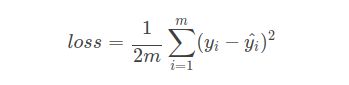
这里的m表示m个样本的,loss为m个样本的loss均值。MSE在线性回归问题中比较好用,那么在逻辑分类问题中还是如此么?
- 为什么线性回归任务中不用MSN方法呢?
- 答:主要原因是在分类问题中,使用sigmoid/softmx得到概率,配合MSE损失函数时,采用梯度下降法进行学习时,会出现模型一开始训练时(这时候的概率往往很低),
学习速率非常慢的情况。- 因为回归问题要求拟合实际的值,通过MSE衡量预测值和实际值之间的误差,可以通过梯度下降的方法来优化。而不像分类问题,需要一系列的激活函数(sigmoid、softmax)来将预测值映射到0-1之间。
- 如果分类任务使用sigmoid,当输出是0或1的值时,梯度接近于0,也出现了
梯度消失现象。
2.2 交叉熵
交叉熵在单分类问题上基本是标配的方法,如下式所示,其中n表示n种类别。
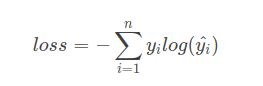
- 二分类
在二分类的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 p p p和 1 − p 1-p 1−p,此时表达式为:

其中:
- y i y_i yi:表示样本 i i i的label,正类为1,负类为0。
- p i p_i pi:表示样本 i i i预测为正类的概率。
- 多分类
多分类的情况实际上就是对二分类的扩展:

其中:
- M M M: 类别的数量
- y i c y_{ic} yic:符号函数0或1,如果样本 i i i的真实类别等于 c c c取1,否则取0。
- p i c p_{ic} pic:观测样本 i i i属于类别 c c c的预测概率
现在我们利用这个表达式计算下面例子中的损失函数值:
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.3 0.3 0.4 | 0 0 1 (猪) | 正确 |
| 0.3 0.4 0.3 | 0 1 0 (狗) | 正确 |
| 0.1 0.2 0.7 | 1 0 0 (猫) | 错误 |

对所有样本的loss求平均:
![]()
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.1 0.2 0.7 | 0 0 1 (猪) | 正确 |
| 0.1 0.7 0.2 | 0 1 0 (狗) | 正确 |
| 0.3 0.4 0.3 | 1 0 0 (猫) | 错误 |

对所有样本的loss求平均:
![]()
可以发现,虽然上面两个模型的预测值一样,但是交叉熵差别还挺大,所以我们通常使用交叉熵来计算多分类任务。
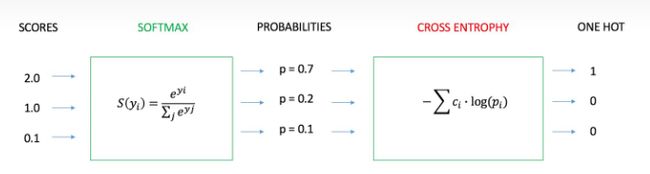
- softmax与交叉熵联合使用如下
参考:https://zhuanlan.zhihu.com/p/35709485