通俗易懂的 k-means 聚类算法原理及优化(附代码)
目录
- 1、算法步骤
- 2、详细过程
- 3、流程图
- 4、聚类过程示意图
- 5、测试效果
- 6、算法优化
K-means算法的基本思想是:以空间中个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
1、算法步骤
输入:聚类个数,以及包含个数据对象的数据集
输出:满足方差最小标准的个聚类
Step1 从个数据对象任意选择个对象作为初始聚类中心;
Step2 根据簇中对象的平均值,将每个对象重新赋给最类似的簇;
Step3 更新簇的平均值,即计算每个簇中对象的平均值;
Step4 循环Step2到Step3直到每个聚类不再发生变化为止。
2、详细过程
1) 给定大小为 n n n 的数据集,令 i t e r = 1 iter=1 iter=1,表示迭代次数,选择 k k k 个初始聚类中心 z j ( i t e r ) , j = 1 , 2 , … , k z_{j}(iter),j=1,2,\dots,k zj(iter),j=1,2,…,k ;
2) 计算每个样本数据 x i , i = 1 , 2 , … , n x_{i},i=1,2,\dots,n xi,i=1,2,…,n 与聚类中心的距离,将 x i x_{i} xi 分配给最近的聚类中心 z j ( i t e r ) z_{j}(iter) zj(iter) 所属的聚类,即 ∣ x i − z j ( i t e r ) ∣ ≤ ∣ x i − z j ′ ( i t e r ) ∣ , j ′ ≠ j , j ′ , j ∈ ( 1 , 2 , … . k ) \vert x_{i}-z_{j}(iter)\vert \leq \vert x_{i}-z_{j^{'}}(iter)\vert,j^{'}\neq j,j^{'},j \in(1,2,\dots.k) ∣xi−zj(iter)∣≤∣xi−zj′(iter)∣,j′=j,j′,j∈(1,2,….k);
3) 令 i t e r = i t e r + 1 iter=iter+1 iter=iter+1,计算新的聚类中心(取已聚类的平均值)和误差平方和准则 F F F (目标函数)值
F ( i t e r ) = ∑ j = 1 k ∑ i = 1 n ∥ x i j − z j ( i t e r ) ∥ 2 F(iter)=\sum_{j=1}^{k}\sum_{i=1}^{n}\Vert x_{i}^{j}-z_{j}(iter)\Vert^{2} F(iter)=j=1∑ki=1∑n∥xij−zj(iter)∥2
4) 判断:若 ∣ F ( i t e r + 1 ) − F ( i t e r ) ∣ < θ \vert F(iter+1) - F(iter) \vert<\theta ∣F(iter+1)−F(iter)∣<θ ( F F F 收敛) 或者对象无类别变化,则算法结束,否则,返回第 2)步。
3、流程图
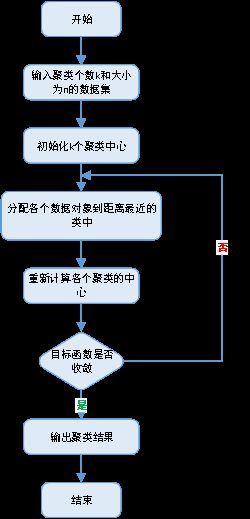
4、聚类过程示意图
(和测试效果图无关,只是为了展示)
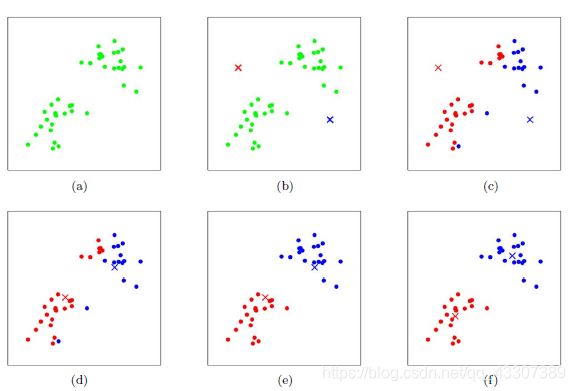
5、测试效果

6、算法优化
由于随机聚类中心的不同,在最小化代价函数时,有可能会停留在一个局部最小值处,导致最终的聚类效果不佳。需要对初始化质心点的选择进行优化。
优化:选择批次距离尽可能远的 k k k 个点(事先确定的类簇个数),首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出 k k k 个初始类簇中心点。
下面是优化后初始质心点选择的代码部分(所用语言C#):
DataPoint firstCenterPoint = new DataPoint(dataSet[0].X, dataSet[0].Y, 1); //选择第一个点作为第一个随机点
int n = 2;
centerPoints.Add(firstCenterPoint);
for (int i = 0; i < k - 1; ++i, ++n)
{
List<double> tempList = new List<double>();
for (int j = 0; j < len; ++j)
{
bool brFlag = false;
for (int m = 0; m < centerPoints.Count(); ++m)
{
if (dataSet[j].X == centerPoints[m].X && dataSet[j].Y == centerPoints[m].Y)
{
brFlag = true;
break;
}
}
if (brFlag)
{
tempList.Add(0);
continue;
}
List<double> ceterPointSd = new List<double>();
for (int m = 0; m < centerPoints.Count(); ++m)
{
double tempSd = Math.Sqrt(SquareDistance(dataSet[j], centerPoints[m]));
ceterPointSd.Add(tempSd);
}
double minSd = ceterPointSd.Min();
tempList.Add(minSd);
}
int maxIndexValue = tempList.Select((m, index) => new { m, index }).Where(x => x.m == tempList.Max()).FirstOrDefault().index;
DataPoint centerPoint = new DataPoint(dataSet[maxIndexValue].X, dataSet[maxIndexValue].Y, n);
centerPoints.Add(centerPoint);
}