循环神经网络(Recurrent Neural Network)详解
循环神经网络(RNNs)是神经网络中一个大家族,它们主要用于文本、信号等序列相关的数据。常见的循环神经网络有长短期记忆网络(LSTM)、门控循环单元网络(GRU)等,而这些循环神经网络都是在最早的一种神经网络基础之上改进而来的,所以兔兔在本文讲解的是循环神经网络家族中最早的一种神经网络——循环神经网络(RNN),并在RNN的基础上介绍双向循环网络(Bidirectional RNN,BRNN)与深层循环网络(Deep RNN,DRNN)。
(注:循环神经网络通常指的是最早的一种神经网络结构,称为RNN,随着后面的发展出现的新的种类的循环神经网络,可以说他们与最早的RNN都归属于循环神经网络家族RNNs。当然,递归神经网络(Recursive neural network)也属于循环神经网络的一种,简写为RNN,但是递归神经网络是具有树状阶层结构的循环神经网络,所以虽然简写都是RNN,但是它们却是结构完全不同的两种网络。)
一:基本原理
1.研究对象
对于循环神经网络,它的研究对象是序列数据,如文本、每天的平均温度、股市行情等,利用过去的数据对模型进行训练,来实现对未来某一时刻或某些时刻数据的预测;或是用文本数据训练模型,实现文本翻译、聊天机器人等功能。
若研究文本数据,我们需要将单词用向量表示,如one hot 编码或是词嵌入后得到的单词编码等,并且这个编码是长度为p的一维张量;如果是时序数据,例如对于每一天的天气,我们统计最高温度、最低温度、空气湿度、气压、污染物含量这5个指标,那么这一天的数据就可以用长度为5的一维张量表示。所以循环神经网络中,每一时刻的输入和输出、或是文本中某一位置的输入和输出,通常都是具有固定长度的一维张量。
2.循环神经网络的大致结构
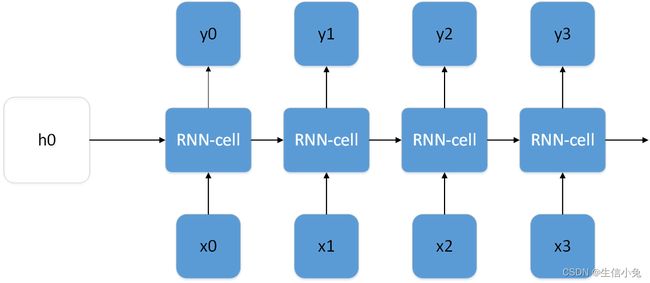
对于时序数据,上图中x0表示t0时刻的输入,x1表示t1时刻的输入,以此类推;y0表示t0时刻输入,以此类推。所以RNN-cell的个数是不固定的,根据实际需要来设定,并且输入的个数和输出的个数也并非固定。例如,我们想根据前4天的平均来预测第5天的温度,那么我们RNN可以设计如下:

上图表示的模型可以理解为:每次输入1~4天的平均温度x0~x4,输出为2~5的平均温度y1~y4。这样用过去的数据来对模型进行训练,训练好后就可以将某4天温度输入模型,从而得到y4预测值,当然,对于这个问题,我们也可以设计成多对一的形式的,如下图所示,此时就是用前3天的数据来预测第4天的数据。
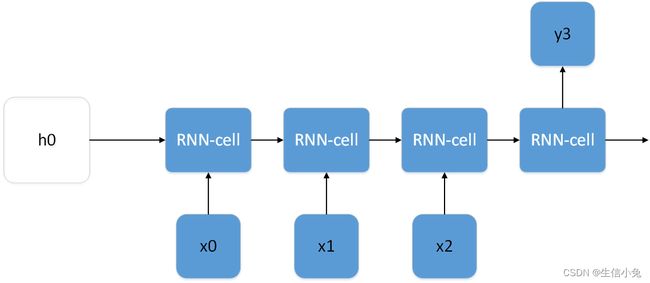
对于语言翻译,输入和输出句子含有的单词都是多个,所以对于这类问题可以设计成多对多形式。

对于图片描述、音乐生成等问题,它通常根据一个输入,来产生多个输出,对于这类问题可以设计成一对多的形式,如下图所示。
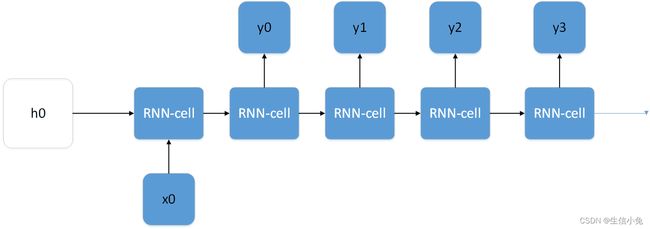
3.循环神经网络具体结构
1.RNN-cell结构
我们这里先讲解第1个RNN cell。
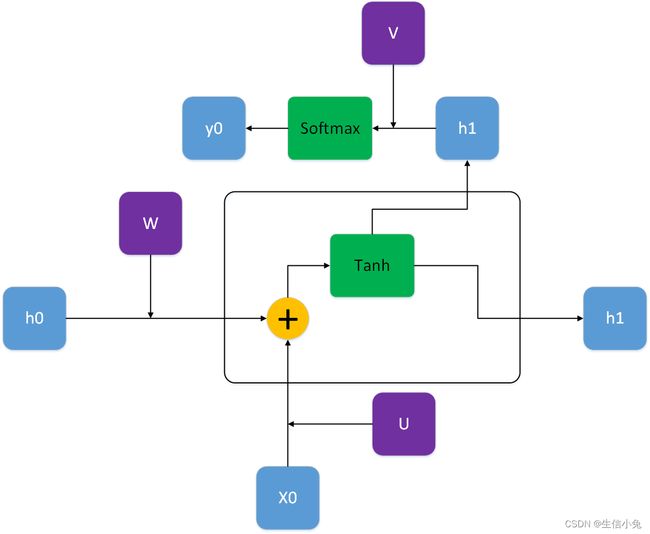
上图中绿色的为激活函数,在RNN中这两个位置通常用tanh和softmax激活函数,当然用其它是激活函数理论上也是可以的;x0为t0时刻输入,dim=(p×1);ht表示隐藏层状态,维度dim=(p×1),初始时刻的h0有一般设为全0向量,dim=(q×1);紫色的U、V、W是模型需要学习的参数,U的维度dim=(q×p),W的维度为dim=(q×q),V的维度为(q×q);输出yt的维度为dim=(q×1)。在大多数情况,由于输入输出数据类型相同,p和q相等。
所以,对于上图,在黄色的加号部分,运算为:
![]()
bu和bv为两部分偏置,有的时候也可以不需要。对于下面x0或左边h0部分,矩阵与输入向量相乘再加上偏置b,实际上就相当于一个全连接层。
通过第一个激活函数,得到的h1为:
![]()
h1为得到的隐藏状态,它可以继续像h0输入到第一个RNN cell那样输入到第二个RNN cell。如果第一个RNN需要输出,那么h1还要与V相乘并经过Softmax激活函数得到output。
![]()
为了降低模型的复杂度,对于整个RNN,所有的RNN都共用相同的参数U、V、W。
对于之后的RNN cell,与之完全相同,h0、x0、y0换成对应的ht、xt、yt即可。
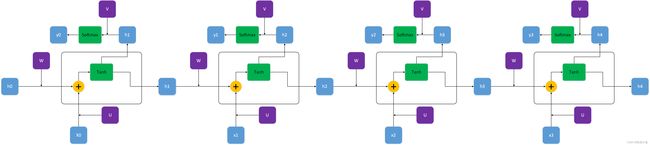
4.双向RNN与深度RNN。
前面的RNN,隐藏层是从左向右单向传递。而对于双向RNN,其隐藏层既有从左向右的传递,也有从右向左的传递,并且这两个方向的传递完全独立,所以模型参数为正向的W、U、V、b_u、b_w与反向的W'、U'、V'、b_u'、b_w',参数数量为单向RNN的二倍。双向RNN每个RNN cell会有两个输出,所以最终输出结果为这两个输出的拼接。如一个输出dim=(q×1),最终得到输出为(2q×1)。

对于深层RNN,则是在RNN的基础上增加多层RNN,每一层的RNN的输出作为下一层RNN的输入,下图即为一个层数为3的深层循环神经网络。
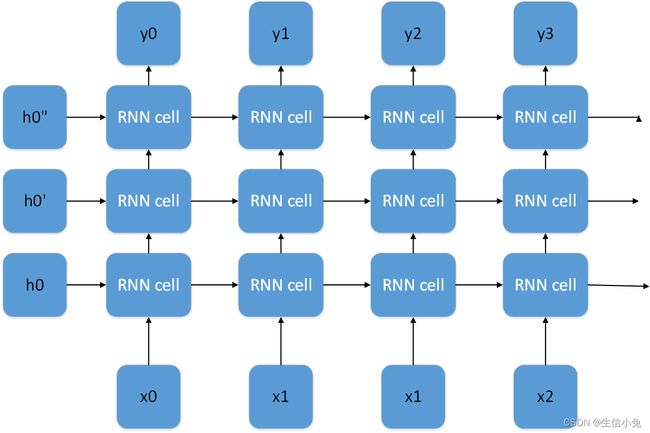
当然,深层神将网络中每一层也可以是一个BRNN,此时是深层双向RNN。
二:方法实现
1.利用Pytorch设计RNN cell 与RNN
在Pytorch中有专门的RNN cell 与RNN方法,后面兔兔会讲到。但是为了掌握该方法原理,我们先手动设计该网络。
import torch
from torch import nn
class RNNCell(nn.Module):
def __init__(self,input_dim,output_dim):
'''
:param input_dim: 输入数据维度
:param output_dim: 输出数据维度
'''
super().__init__()
self.U=nn.Parameter(torch.randn(size=(input_dim,output_dim),dtype=torch.float32))
self.W=nn.Parameter(torch.randn(size=(output_dim,output_dim),dtype=torch.float32))
self.V=nn.Parameter(torch.randn(size=(output_dim,output_dim),dtype=torch.float32))
self.b1=nn.Parameter(torch.randn(size=(1,output_dim),dtype=torch.float32))
self.b2=nn.Parameter(torch.randn(size=(1,output_dim),dtype=torch.float32))
self.act1=nn.Tanh()
self.act2=nn.Sigmoid()
def forward(self,input,h0):
h=self.act1(torch.matmul(input,self.U)+torch.matmul(h0,self.W)+self.b1+self.b2)
output=self.act2(torch.matmul(h,self.V))
return output,h
class RNN(RNNCell):
def __init__(self,input_dim,output_dim):
'''
:param input_dim :输入数据维度
:param output_dim:输出数据维度
output: sequence batch,seq_len,dim
'''
RNNCell.__init__(self,input_dim,output_dim)
self.input_dim=input_dim
self.output_dim=output_dim
self.rnncell=RNNCell(self.input_dim,self.output_dim)
def forward(self,input):
b,l,h=input.shape
h0=torch.zeros(size=(b,self.output_dim),dtype=torch.float32)
input1=input[:,0,:]
out1,h1=self.rnncell(input1,h0)
output=[]
output.append(out1)
for i in range(l-1):
out,h2=self.rnncell(input[:,i+1,:],h1)
h1=h2
output.append(out)
output=torch.stack([i for i in output]).permute(1,0,2)
return output,h1
if __name__=='__main__':
input=torch.randint(0,1,size=(5,3,2),dtype=torch.float32) #batch size=5,seq=3,dim=2
output=torch.randint(0,1,size=(5,3,4),dtype=torch.float32) #batch size=5,seq=3,dim=4
rnn=RNN(input_dim=2,output_dim=4)
optim=torch.optim.Adam(params=rnn.parameters())
Loss=nn.MSELoss()
out=rnn(input)
for i in range(100):
yp=rnn(input)[0]
loss=Loss(yp,output)
optim.zero_grad()
loss.backward()
optim.step()
print(loss)以上代码实现的是单层单向的RNN,并且输出长度与输入长度相同。
2.使用Pytorch中的RNN方法。
Pytorch中的RNN与我们前面理论讲解是有所出入的。在Pytorch中,需要学习的参数只有U、W、b_u、b_w四个,并没有V,所以它应该是把某一状态的隐藏状态h_t直接作为输出,没有与参数V相乘的这个过程,并且RNN输入序列长度和输出序列长度是完全相同的。
nn.RNN()方法中,有以下几个参数:
1.input_size:输入数据的特征数量。
2.hidden_size:隐藏层h的特征数量,实际上也是输出数据的维度。
3.bidirectional:是否为双向RNN,默认False。
4.num_layers:RNN层数,默认为1。多层即为深层RNN。
5.batch_firse:是否认为输入数据第一个维度为batch_size,默认为True。如为False,则认为第一个维度是序列长度。
6.nonlinearity:非线性函数,可以为'tanh'、'relu'、'sigmoid'等激活函数。
7.bias:参数中是否有偏置b,默认为True。
nn.RNN()最终的输出并只有output,还有最后一个隐藏状态h_t。所以它的输出是(output,h_t)元组。对于RNNCell也是如此。
对于nn.RNNCell,参数与RNN大致相同。不过RNNCell是RNN一个结构单元,接受序列长度只能为1,需要用一定方法把它们组合才能正常使用。
兔兔在这里以比特币从今年6月28至9月28日的收盘、开盘、交易量数据为例,该数据可在英为财情官网下载(https://cn.investing.com/),也可以在兔兔的资源中下载。由于数据比较少,所以下面只用训练集训练,没有验证与检测。
import pandas as pd
import numpy as np
import re
import torch
from torch import nn
from torch.utils.data import DataLoader
df=pd.DataFrame(pd.read_csv('Bitcoin.csv'))
n=len(df)
opening=[]
closing=[]
transaction=[]
for i in range(n):
a = re.split(',',df['开盘'].loc[i])
a=float(a[0])*1000+float(a[1])
b = re.split(',', df['收盘'].loc[i])
b = float(b[0]) * 1000 + float(b[1])
c=re.split('K',df['交易量'].loc[i])[0]
c=float(c)
opening.append(a)
closing.append(b)
transaction.append(c)
data=np.array([opening,closing,transaction]).transpose()
seq_size=10 #RNN长度
train_num=1000#训练数据个数
epoch=100
train_data=[]
train_label=[]
for i in range(1000):
j=np.random.randint(0,n-seq_size-2)
train_data.append(data[j:j+seq_size])
train_label.append(data[j+2:j+seq_size+2])
train_data=np.float32(np.array(train_data,dtype=object))
train_label=np.float32(np.array(train_label,dtype=object))
class dataset:
def __init__(self):
self.data=torch.tensor(train_data,dtype=torch.float32)
self.label=torch.tensor(train_label,dtype=torch.float32)
def __len__(self):
return train_num
def __getitem__(self, item):
return self.data[item],self.label[item]
rnn=nn.RNN(input_size=3,hidden_size=3,bidirectional=False,batch_first=True,num_layers=2)
optim=torch.optim.Adam(params=rnn.parameters(),lr=1e-12)
Loss=nn.MSELoss()
data=DataLoader(dataset(),batch_size=10)
for i in range(epoch):
print('the {} epoch'.format(i))
for d in data:
yp=rnn(d[0])[0]
loss=Loss(yp,d[1])
optim.zero_grad()
loss.backward()
optim.step()
print(loss.data)三:总结
RNN作为循环神经网络中最基础的模型,在很多问题上有时表现得并不是很好,尤其是序列过长时,RNN无法有效地学习,所以需要新的模型来解决该问题。LSTM、GRU等循环神经网络便由此产生,它们主要是在RNN cell内部结构上进行改进,在整体上结构上与RNN是几乎一致的。