目标检测算法——YOLOv3
文章目录
- 1.YOLOv3简介
- 2.YOLOv3改进
-
- 1)backbone
- 2)多尺度预测
- 3)目标边界框的预测
- 4)多标签分类
- 3.YOLOv3损失函数
-
- 1)目标置信度损失
- 2)目标类别损失
- 3)目标定位损失
回顾前两个版本的yolo笔记:
YOLOv1:目标检测算法——YOLOv1
YOLOv2:目标检测算法——YOLOv2
本文结合了几个博主的笔记,加上自己的一些理解归纳而成。其中比较多的参考了博主「太阳花的小绿豆」对yolov3的结构分析,详情见参考资料的2,3。
yolov3原文链接:YOLOv3: An Incremental Improvement
1.YOLOv3简介
2018年,作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
从YOLOv1到YOLOv3,每一代性能的提升都与backbone(骨干网络)的改进密切相关。在YOLOv3中,作者不仅提供了darknet-53,还提供了轻量级的tiny-darknet。如果你想检测精度与速度兼具,可以选择darknet-53作为backbone;如果你希望达到更快的检测速度,精度方面可以妥协,那么tiny-darknet是你很好的选择.
2.YOLOv3改进
1)backbone
yolov3的backbone从darknet-19改进为darknet-53。
这里采用了视频中的一幅图作笔记,见参考链接,YOLOv3 进行了较大的改进。借助残差网络的思想,darknet-53的结构如图所示:
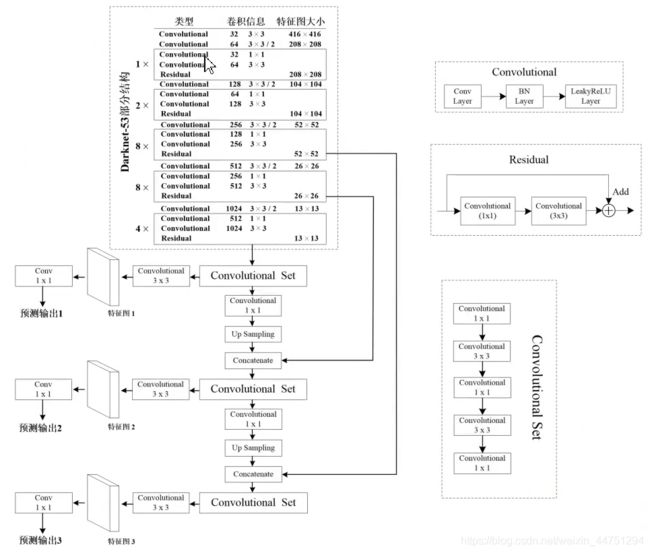
- Convolutional层包含Conv卷积层,BN批量归一化层,和Leaky ReLU激活层,生成预测结果的最后三层都只是Conv2d
- Residual残差结构由1x1的Convolutional层与3x3的Convolutional层组合而成
- Convolution Set最后的特征提取由一系列的1x1与3x3的Convolutional层组合而成
- Concatenate层将darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。
Darknet-53主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。因为在Darknet-53中共包含53个这样的Convolutional层,所以称其为Darknet-53。
与darknet-19对比可知,darknet-53主要做了如下改进:
- 没有采用最大池化层,转而采用步长为2的卷积层进行下采样。
- 为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
- 引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
- 将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
2)多尺度预测
为了能够预测多尺度的目标,YOLOv3 选择了三种不同shape的Anchors,同时每种Anchors具有三种不同的尺度,一共9种不同大小的Anchors。在COCO数据集上选择的9种Anchors的尺寸如下图红色框所示,对于这几种anchors的尺寸同样是通过聚类算法得到的。

同时结合上图进行解释,其中(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid):

通过如图所示的一些列卷积操作,最后会得到3个预测特征矩阵输出。
- 对于特征图1,由于其没有融合一些比较低维的信息,所以适合预测一些尺寸比较大的目标,也就是其anhcors会使用(116 × 90),(156 × 198),(373 × 326)三种;
- 对于特征图2,由于其融合了相对比较低维的信息,所以适合预测一些中等尺寸的目标,也就是该层的anchors会使用(30×61),(62×45),(59×119)三种
- 对于特征图3,由于其融合了比较低维的信息,所以保留了图像上比较多的细节信息,这适合预测一些小尺寸的目标,也就是该层的anchors会使用(10×13),(16×30),(33×23)三种
由于这每一层的特征图都会预测3中尺寸不同的边界框,而每一个边界框有x,y,w,h,confidence一共5个参数,而且边界个网格还需要预测80中类别信息(coco数据集有80类),对于nxn的特征矩阵,也就是nxn个网格,所以网络输出的张量应该是:N ×N ×[3∗(4 + 1 + 80)]。
所以这三个特征图输出的shape分别是:[13, 13, 255]、[26, 26, 255]、[52, 52, 255]
3)目标边界框的预测
YOLOv3网络在三个特征图中分别通过(4+1+c) k个大小为11的卷积核进行卷积预测,k为预设边界框(bounding box prior)的个数(k默认取3),c为预测目标的类别数,其中4k个参数负责预测目标边界框的偏移量,k个参数负责预测目标边界框内包含目标的概率,ck个参数负责预测这k个预设边界框对应c个目标类别的概率。
下图展示了目标边界框的预测过程,图中虚线矩形框为预设边界框,实线矩形框为通过网络预测的偏移量计算得到的预测边界框。

其中(Cx,Cy)为预设边界框在特征图上的中心坐标,(Pw,Py)为预设边界框在特征图上的宽和高,(tx,ty,tw,th)分别为网络预测的边界框中心偏移量(tx,ty)以及宽高缩放比(tw,th),(bx,by,bw,bh)为最终预测的目标边界框,从预设边界框到最终预测边界框的转换过程如图右侧公式所示,其中σ(x)函数是sigmoid函数其目的是将预测偏移量缩放到0到1之间(这样能够将预设边界框的中心坐标固定在一个cell当中,作者说这样能够加快网络收敛)。
下图给出了三个预测层的特征图大小以及每个特征图上预设边界框的尺寸(这些预设边界框尺寸都是作者根据COCO数据集聚类得到的):

4)多标签分类
YOLOv3在类别预测方面将YOLOv2的单标签分类改进为多标签分类,在网络结构中将YOLOv2中用于分类的softmax层修改为逻辑分类器。在YOLOv2中,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。
比如在一个交通场景中,某目标的种类既属于汽车也属于卡车,如果用softmax进行分类,softmax会假设这个目标只属于一个类别,这个目标只会被认定为汽车或卡车,这种分类方法就称为单标签分类。如果网络输出认定这个目标既是汽车也是卡车,这就被称为多标签分类。
为实现多标签分类就需要用逻辑分类器来对每个类别都进行二分类。逻辑分类器主要用到了sigmoid函数,它可以把输出约束在0到1,如果某一特征图的输出经过该函数处理后的值大于设定阈值,那么就认定该目标框所对应的目标属于该类。
3.YOLOv3损失函数
yolov3的损失函数与之前相比稍微改动了一下,坐标损失采用的是误差的平方和,类别损失采用的是二值交叉熵。(一般来说说逻辑回归使用的是二值的交叉熵损失)
YOLOv3的损失函数 = 目标定位偏移量损失 + 目标置信度损失 + 目标分类损失

其中λ1,λ2,λ3是平衡系数
1)目标置信度损失
目标置信度可以理解为预测目标矩形框内存在目标的概率,目标置信度损失采用的是二值交叉熵损失(Binary Cross Entropy),其中,Oi∈(0,1)表示预测目标边界框i中是否真实存在目标,0表示不存在,1表示存在。c^i表示预测目标矩形框i内存在目标的Sigmoid概率(将预测值ci通过sigmoid函数得到)。

2)目标类别损失
目标类别损失同样采用的是二值交叉熵损失(采用二值交叉熵损失的原因是,作者认为同一目标可同时归为多类,比如猫可归为猫类以及动物类,这样能够应对更加复杂的场景。但在博主「太阳花的小绿豆」实践过程中发现使用原始的多类别交叉熵损失函数效果会更好一点,原因是博主「太阳花的小绿豆」针对识别的目标都是固定归于哪一类的,并没有可同时归于多类的情况)
其中Oi∈(0,1)表示预测目标边界框i中是否真实存在第j类目标,0表示不存在,1表示存在。 C ^ i j \hat{C}^ij C^ij表示网络预测目标边界框i内存在第j类目标的Sigmoid概率(将预测值Cij通过sigmoid函数得到)
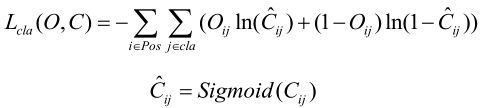
注意,在这里的损失就是yolov3的其中一个改进:多标签分类。因为这里使用的是二值的交叉熵损失,其累加起来的和不是等于1的,因为只是经过了sigmoid处理,而没有经过softmax处理。也就是在这里的每个预测值之间是互不干扰的,是相互独立的。也就是之前提到的,其既可能属于某一类,也可能同时属于某一类的情况。
3)目标定位损失
目标定位损失采用的是真实偏差值与预测偏差值差的平方和,其中 l ^ \hat{l} l^表示预测矩形框坐标偏移量(注意网络预测的是偏移量,不是直接预测坐标), g ^ \hat{g} g^表示与之匹配的GTbox与默认框之间的坐标偏移量,( b x , b y , b w , b h b^x,b^y,b^w,b^h bx,by,bw,bh)为预测的目标矩形框参数,( c x , c y , p w , p h c^x,c^y,p^w,p^h cx,cy,pw,ph)为默认矩形框参数,( g x , g y , g w , g h g^x,g^y,g^w,g^h gx,gy,gw,gh)为与之匹配的真实目标矩形框参数,这些参数都是映射在预测特征图上的。

总的损失表达式:
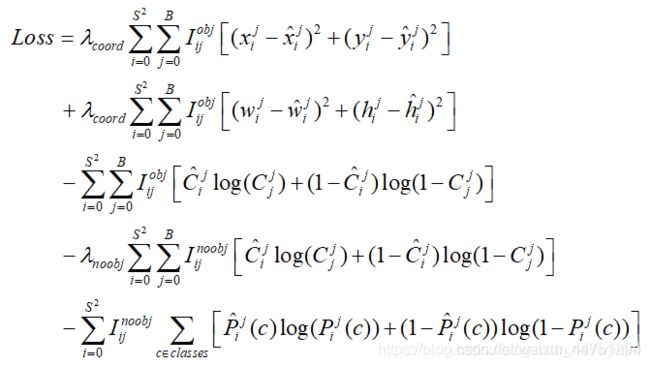
参考资料:
- https://blog.csdn.net/wjinjie/article/details/107509243
- https://blog.csdn.net/qq_37541097/article/details/81214953
- https://www.bilibili.com/video/BV1yi4y1g7ro?t=381&p=3
- https://blog.csdn.net/weixin_44751294/article/details/117851548
- https://blog.csdn.net/weixin_44751294/article/details/117844557