李沐动手学深度学习V2-RNN循环神经网络原理
一. 李沐循环神经网络RNN原理
1.介绍
前面博文介绍了 n n n元语法模型,其中单词 x t x_t xt在时间步 t t t的条件概率仅取决于前面 n − 1 n-1 n−1个单词。对于时间步 t − ( n − 1 ) t-(n-1) t−(n−1)之前的单词,如果想将其可能产生的影响合并到 x t x_t xt上,需要增加 n n n,导致模型参数的数量也会随之呈指数增长,因为词表 V \mathcal{V} V需要存储 ∣ V ∣ n |\mathcal{V}|^n ∣V∣n个数字,因此与其将 P ( x t ∣ x t − 1 , … , x t − n + 1 ) P(x_t \mid x_{t-1}, \ldots, x_{t-n+1}) P(xt∣xt−1,…,xt−n+1)模型化,不如使用隐变量模型:
P ( x t ∣ x t − 1 , … , x 1 ) ≈ P ( x t ∣ h t − 1 ) , P(x_t \mid x_{t-1}, \ldots, x_1) \approx P(x_t \mid h_{t-1}), P(xt∣xt−1,…,x1)≈P(xt∣ht−1),
其中 h t − 1 h_{t-1} ht−1是隐状态(hidden state),也称为隐藏变量(hidden variable),它存储了到时间步 t − 1 t-1 t−1的序列信息。通常可以基于当前输入 x t x_{t} xt和先前隐状态 h t − 1 h_{t-1} ht−1来计算时间步 t t t处的任何时间的隐状态:
h t = f ( x t , h t − 1 ) . h_t = f(x_{t}, h_{t-1}). ht=f(xt,ht−1).
对于上面公式中函数 f f f,隐变量模型不是近似值,因为 h t h_t ht是可以存储到目前为止观察到的所有数据,然而这样的操作可能会使计算和存储的代价都变得昂贵。
注意隐藏层和隐状态指的是两个截然不同的概念,隐藏层是从输入到输出的路径上(以观测角度来理解)的隐藏的层,而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入,并且这些状态只能通过先前时间步的数据来计算,因此* 循环神经网络*(recurrent neural networks,RNNs)是具有隐状态的神经网络。下面看一下有隐状态的和无状态的神经网络。
1.1 无隐状态的神经网络(多层感知机)
单隐藏层的多层感知机,设隐藏层的激活函数为 ϕ \phi ϕ,给定一个小批量样本 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d,其中批量大小为 n n n,输入维度为 d d d,则隐藏层的输出 H ∈ R n × h \mathbf{H} \in \mathbb{R}^{n \times h} H∈Rn×h通过下式计算:
H = ϕ ( X W x h + b h ) . \mathbf{H} = \phi(\mathbf{X} \mathbf{W}_{xh} + \mathbf{b}_h). H=ϕ(XWxh+bh).
在上面公式中看出单隐藏层网络中拥有的隐藏层权重参数为 W x h ∈ R d × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h,
偏置参数为 b h ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及隐藏单元的数目为 h h h,因此求和时可以应用广播机制,接下来将隐藏变量 H \mathbf{H} H用作输出层的输入,输出层由下式给出:
O = H W h q + b q , \mathbf{O} = \mathbf{H} \mathbf{W}_{hq} + \mathbf{b}_q, O=HWhq+bq,
其中, O ∈ R n × q \mathbf{O} \in \mathbb{R}^{n \times q} O∈Rn×q是输出变量, W h q ∈ R h × q \mathbf{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q是权重参数, b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q是输出层的偏置参数。
如果是分类问题,可以用 softmax ( O ) \text{softmax}(\mathbf{O}) softmax(O)来计算输出类别的概率分布。只要可以随机选择“特征-标签”对,并且通过自动微分和随机梯度下降能够学习网络参数就可以。
1.2 有隐状态的循环神经网络
假设在时间步 t t t有小批量输入 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d。换言之,对于 n n n个序列样本的小批量, X t \mathbf{X}_t Xt的每一行对应于来自该序列的时间步 t t t处的一个样本。接下来用 H t ∈ R n × h \mathbf{H}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h表示时间步 t t t的隐藏变量,与多层感知机不同的是,在这里保存了前一个时间步的隐藏变量 H t − 1 \mathbf{H}_{t-1} Ht−1,并引入了一个新的权重参数 W h h ∈ R h × h \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h,来描述如何在当前时间步中使用前一个时间步的隐藏变量。具体地说,当前时间步隐藏变量由当前时间步的输入与前一个时间步的隐藏变量一起计算得出:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) . \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h). Ht=ϕ(XtWxh+Ht−1Whh+bh).
与 无状态的神经网络相比,有状态的循环神经网络多添加了一项 H t − 1 W h h \mathbf{H}_{t-1} \mathbf{W}_{hh} Ht−1Whh。从相邻时间步的隐藏变量 H t \mathbf{H}_t Ht和 H t − 1 \mathbf{H}_{t-1} Ht−1之间的关系可知,这些变量捕获并保留了序列直到其当前时间步的历史信息,就如当前时间步下神经网络的状态或记忆,因此这样的隐藏变量被称为隐状态(hidden state)。由于在当前时间步中,隐状态使用的定义与前一个时间步中使用的定义相同,因此 循环神经网络隐状态的计算是循环的(recurrent),因此基于循环计算的隐状态神经网络被命名为循环神经网络(recurrent neural network)。在循环神经网络中执行隐状态计算的层称为循环层(recurrent layer)。
对于时间步 t t t,输出层的输出类似于多层感知机中的计算:
O t = H t W h q + b q . \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q. Ot=HtWhq+bq.
循环神经网络的参数包括隐藏层的权重 W x h ∈ R d × h , W h h ∈ R h × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Wxh∈Rd×h,Whh∈Rh×h和偏置 b h ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h,以及输出层的权重 W h q ∈ R h × q \mathbf{W}_{hq} \in \mathbb{R}^{h \times q} Whq∈Rh×q和偏置 b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q,注意即使在不同的时间步,循环神经网络也总是使用这些模型参数,因此循环神经网络的参数开销不会随着时间步的增加而增加。
在任意时间步 t t t,隐状态和当前时间步网络的输出的计算可以被看作,下图展示了循环神经网络在三个相邻时间步的计算逻辑。:
- 拼接当前时间步 t t t的输入 X t \mathbf{X}_t Xt和前一时间步 t − 1 t-1 t−1的隐状态 H t − 1 \mathbf{H}_{t-1} Ht−1,模型参数是 W x h \mathbf{W}_{xh} Wxh和 W h h \mathbf{W}_{hh} Whh的拼接,以及 b h \mathbf{b}_h bh的偏置;
- 将拼接的结果送入带有激活函数 ϕ \phi ϕ的全连接层。
全连接层的输出是当前时间步 t t t的隐状态 H t \mathbf{H}_t Ht。 - 当前时间步 t t t的隐状态 H t \mathbf{H}_t Ht将参与计算下一时间步 t + 1 t+1 t+1的隐状态 H t + 1 \mathbf{H}_{t+1} Ht+1。而且 H t \mathbf{H}_t Ht还将送入全连接输出层,用于计算当前时间步 t t t的输出 O t \mathbf{O}_t Ot。
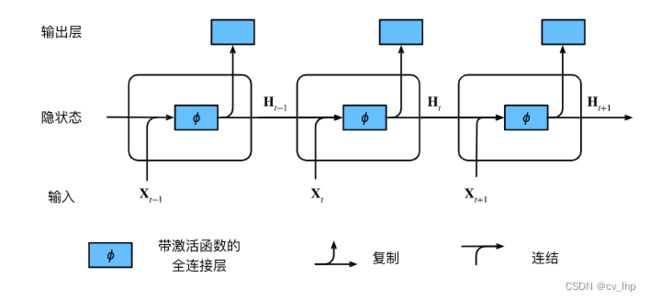
注意上面提到,隐状态中 X t W x h + H t − 1 W h h \mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} XtWxh+Ht−1Whh的计算,相当于 X t \mathbf{X}_t Xt和 H t − 1 \mathbf{H}_{t-1} Ht−1的拼接与 W x h \mathbf{W}_{xh} Wxh和 W h h \mathbf{W}_{hh} Whh的拼接的矩阵乘法。虽然这个性质可以通过数学证明,但在下面使用一个简单的代码来说明一下。首先,定义矩阵X、W_xh、H和W_hh,它们的形状分别为 ( 3 , 1 ) (3,1) (3,1)、 ( 1 , 4 ) (1,4) (1,4)、 ( 3 , 4 ) (3,4) (3,4)和 ( 4 , 4 ) (4,4) (4,4)。分别将X乘以W_xh,将H乘以W_hh,然后将这两个乘法相加,得到一个形状为 ( 3 , 4 ) (3,4) (3,4)的矩阵。
import torch
from d2l import torch as d2l
X, W_xh = torch.normal(0, 1, (3, 1)), torch.normal(0, 1, (1, 4))
H, W_hh = torch.normal(0, 1, (3, 4)), torch.normal(0, 1, (4, 4))
torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
'''
输出结果如下:
tensor([[-0.5702, -0.4673, -0.1508, -0.0185],
[-1.3559, 0.8042, -1.4394, -3.1735],
[ 0.6559, 1.3140, 0.2949, 0.0781]])
'''
现在沿列(轴1)拼接矩阵X和H, 沿行(轴0)拼接矩阵W_xh和W_hh,这两个拼接分别产生形状 (3,5) 和形状 (5,4) 的矩阵,再将这两个拼接的矩阵相乘, 得到与上面相同形状 (3,4) 的输出矩阵。
torch.matmul(torch.cat((X, H), 1), torch.cat((W_xh, W_hh), 0))
'''
输出结果如下:
tensor([[-0.5702, -0.4673, -0.1508, -0.0185],
[-1.3559, 0.8042, -1.4394, -3.1735],
[ 0.6559, 1.3140, 0.2949, 0.0781]])
'''
2.基于循环神经网络的字符级语言模型
我们的目标是根据过去的和当前的词元预测下一个词元,因此我们将原始序列移位一个词元作为标签。接下来使用循环神经网络来构建语言模型:设小批量大小为1,批量中的那个文本序列为“machine”,为了简化后续部分的训练,考虑使用字符级语言模型(character-level language model),将文本词元化为字符而不是单词。 下图展示了如何通过基于字符级语言建模的循环神经网络,使用当前的和先前的字符预测下一个字符。
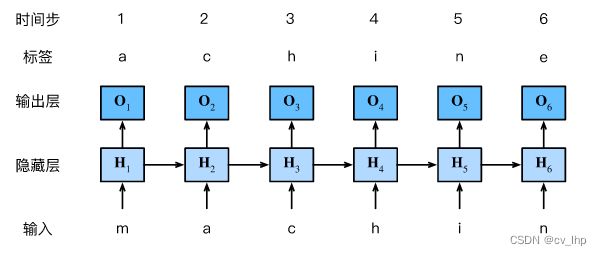
在训练过程中,对每个时间步的输出层的输出进行softmax操作,然后利用交叉熵损失计算模型输出和标签之间的误差。由于隐藏层中隐状态的循环计算, 上图中的第 3 3 3个时间步的输出 O 3 \mathbf{O}_3 O3由文本序列“m”、“a”和“c”确定。由于训练数据中这个文本序列的下一个字符是“h”,因此下一个字符生成是基于特征序列“m”、“a”、“c”和这个时间步的标签“h”生成的。
在实践中,使用的批量大小为 n > 1 n>1 n>1,每个词元都由一个 d d d维向量表示。
因此,在时间步 t t t输入 X t \mathbf X_t Xt将是一个 n × d n\times d n×d矩阵。模型输入形状为(时间步数num_steps,批量大小batch_size,词元表示维数vocab_size)。
3. 困惑度(Perplexity)
困惑度用于度量语言模型的质量,用于评估基于循环神经网络的模型。一个好的语言模型能够用高度准确的词元来预测我们接下来会看到什么。
考虑一下由不同的语言模型给出的对“It is raining …”(“下雨了…”)的续写:
- “It is raining outside”(外面下雨了)
- “It is raining banana tree”(香蕉树下雨了)
- “It is raining piouw;kcj pwepoiut”(piouw;kcj pwepoiut下雨了)
就质量而言,例 1 1 1显然是最合乎情理、在逻辑上最连贯的,虽然这个模型可能没有很准确地反映出后续词的语义,比如,“It is raining in San Francisco”(旧金山下雨了)和“It is raining in winter”(冬天下雨了)可能才是更完美的合理扩展,但该模型已经能够捕捉到跟在后面的是哪类单词。例 2 2 2则要糟糕得多,因为其产生了一个无意义的续写。尽管如此,至少该模型已经学会了如何拼写单词,以及单词之间的某种程度的相关性。最后,例 3 3 3表明了训练不足的模型是无法正确地拟合数据的。我们可以通过计算序列的似然概率来度量模型的质量。然而这是一个难以理解、难以比较的数字,毕竟较短的序列比较长的序列更有可能出现,因此评估模型产生托尔斯泰的巨著《战争与和平》的可能性不可避免地会比产生圣埃克苏佩里的中篇小说《小王子》可能性要小得多。
下面通过一个序列中所有的 n n n个词元的交叉熵损失的平均值来衡量:
1 n ∑ t = 1 n − log P ( x t ∣ x t − 1 , … , x 1 ) , \frac{1}{n} \sum_{t=1}^n -\log P(x_t \mid x_{t-1}, \ldots, x_1), n1t=1∑n−logP(xt∣xt−1,…,x1),
其中 P P P由语言模型给出, x t x_t xt是在时间步 t t t从该序列中观察到的实际词元,这使得不同长度的文档的性能具有了可比性。由于历史原因,自然语言处理的科学家更喜欢使用一个叫做困惑度(perplexity)的量。简而言之,它是 上面公式的指数:
exp ( − 1 n ∑ t = 1 n log P ( x t ∣ x t − 1 , … , x 1 ) ) . \exp\left(-\frac{1}{n} \sum_{t=1}^n \log P(x_t \mid x_{t-1}, \ldots, x_1)\right). exp(−n1t=1∑nlogP(xt∣xt−1,…,x1)).
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”,也即是根据困惑度大小来看预测的候选词元有几个,比如困惑度为1表示预测的候选词元只有一个,也表示网络的准确度也是最好的,如果困惑度为2表示预测的候选词元有两个,最坏的情况下困惑度为无穷大时,表示预测的候选词元有无穷个,因此网络准确度是最坏的,比如下面的一些情况:
- 在最好的情况下,模型总是完美地估计标签词元的概率为1,在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0,在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布,在这种情况下,困惑度等于词表中唯一词元的数量。事实上,如果在没有任何压缩的情况下存储序列,这将是我们能做的最好的编码方式,因此这种方式提供了一个重要的上限,而任何实际模型都必须超越这个上限。
4. 小结
- 对隐状态使用循环计算的神经网络称为循环神经网络(RNN)。
- 循环神经网络的隐状态可以捕获直到当前时间步序列的历史信息。
- 循环神经网络模型的参数数量不会随着时间步的增加而增加。
- 使用循环神经网络创建字符级语言模型。
- 使用困惑度来评价语言模型的质量。
二. 李宏毅机器学习对RNN讲解
RNN,或者说最常用的LSTM,一般用于记住之前的状态,以供后续神经网络的判断,它由input gate、forget gate、output gate和cell memory组成,每个LSTM本质上就是一个neuron,特殊之处在于有4个输入: z z z和三门控制信号 z i z_i zi、 z f z_f zf和 z o z_o zo,每个时间点的输入都是由当前输入值+上一个时间点的输出值+上一个时间点cell值来组成
1. Introduction
Slot Filling
在智能客服、智能订票系统中,往往会需要slot filling技术,它会分析用户说出的语句,将时间、地址等有效的关键词填到对应的槽上,并过滤掉无效的词语。
词汇要转化成vector,可以使用1-of-N编码,word hashing或者是word vector等方式,此外我们可以尝试使用Feedforward Neural Network来分析词汇,判断出它是属于时间或是目的地的概率
但这样做会有一个问题,该神经网络会先处理“arrive”和“leave”这两个词汇,然后再处理“Taipei”,这时对NN来说,输入是相同的,它没有办法区分出“Taipei”是出发地还是目的地
这个时候我们就希望神经网络是有记忆的,如果NN在看到“Taipei”的时候,还能记住之前已经看过的“arrive”或是“leave”,就可以根据上下文得到正确的答案,如下图所示。
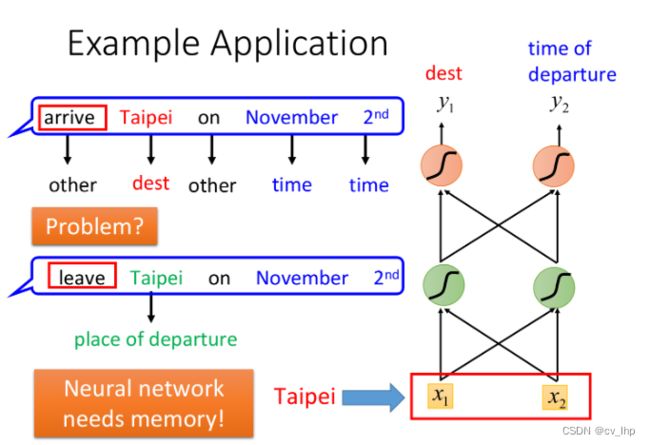
这种有记忆力的神经网络,就叫做Recurrent Neural Network(RNN)
在RNN中,hidden layer每次产生的output a 1 a_1 a1、 a 2 a_2 a2,都会被存到memory里,下一次有input的时候,这些neuron就不仅会考虑新输入的 x 1 x_1 x1、 x 2 x_2 x2,还会考虑存放在memory中的 a 1 a_1 a1、 a 2 a_2 a2
注:在input之前,要先给内存里的 a i a_i ai赋初始值,比如0
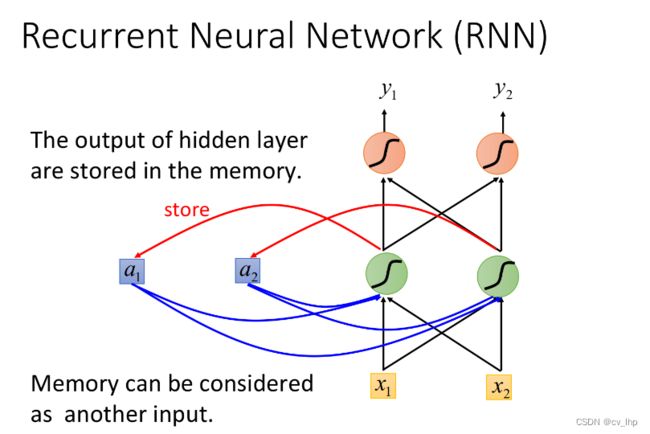
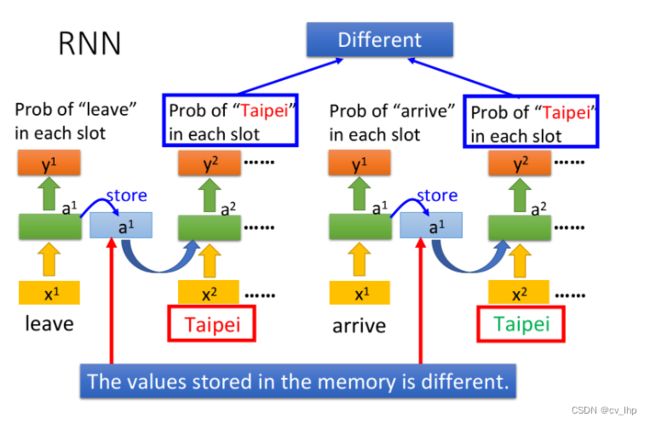
注意到,每次NN的输出都要考虑memory中存储的临时值,而不同的输入产生的临时值也尽不相同,因此改变输入序列的顺序会导致最终输出结果的改变(Changing the sequence order will change the output)
2. Slot Filling with RNN
用RNN处理Slot Filling的流程举例如下:
- “arrive”的vector作为 x 1 x^1 x1输入RNN,通过hidden layer生成 a 1 a^1 a1,再根据 a 1 a^1 a1生成 y 1 y^1 y1,表示“arrive”属于每个slot的概率,其中 a 1 a^1 a1会被存储到memory中
- “Taipei”的vector作为 x 2 x^2 x2输入RNN,此时hidden layer同时考虑 x 2 x^2 x2和存放在memory中的 a 1 a^1 a1,生成 a 2 a^2 a2,再根据 a 2 a^2 a2生成 y 2 y^2 y2,表示“Taipei”属于某个slot的概率,此时再把 a 2 a^2 a2存到memory中
- 依次类推
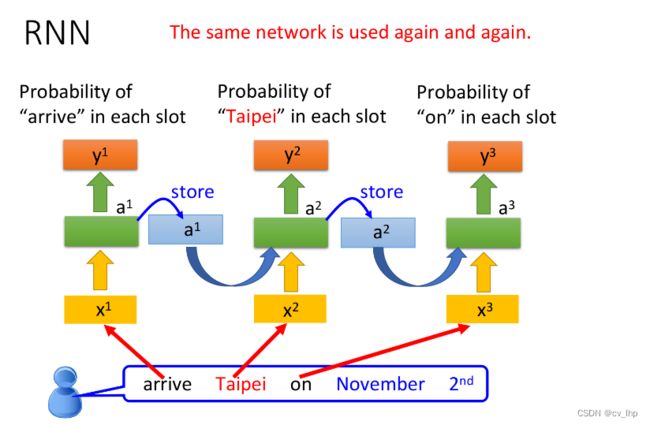
注意:上图为同一个RNN在三个不同时间点被分别使用了三次,并非是三个不同的NN
这个时候,即使输入同样是“Taipei”,我们依旧可以根据前文的“leave”或“arrive”来得到不一样的输出
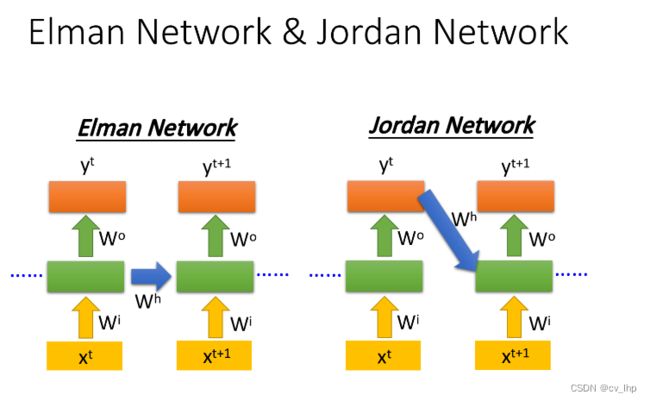
3. Elman Network & Jordan Network
RNN有不同的变形:
- Elman Network:将hidden layer的输出保存在memory里
- Jordan Network:将整个neural network的输出保存在memory里
由于hidden layer没有明确的训练目标,而整个NN具有明确的目标,因此Jordan Network的表现会更好一些
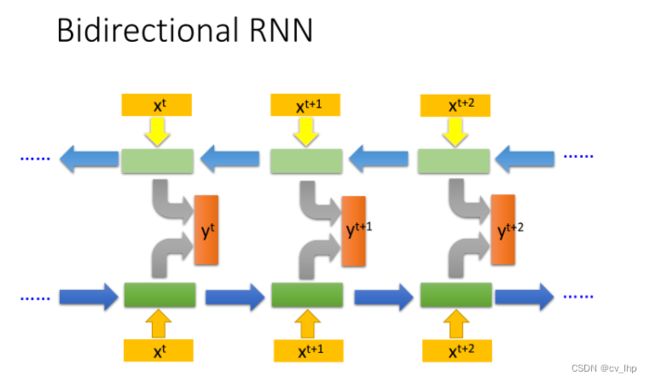
4. Bidirectional RNN
RNN 还可以是双向的,你可以同时训练一对正向和反向的RNN,把它们对应的hidden layer x t x^t xt拿出来,都接给一个output layer,得到最后的 y t y^t yt
使用Bi-RNN的好处是,NN在产生输出的时候,它能够看到的范围是比较广的,RNN在产生 y t + 1 y^{t+1} yt+1的时候,它不只看了从句首 x 1 x^1 x1开始到 x t + 1 x^{t+1} xt+1的输入,还看了从句尾 x n x^n xn一直到 x t + 1 x^{t+1} xt+1的输入,这就相当于RNN在看了整个句子之后,才决定每个词汇具体要被分配到哪一个槽中,这会比只看句子的前一半要更好
三. 链接
循环神经网络RNN第一篇:李沐动手学深度学习V2-NLP序列模型和代码实现
循环神经网络RNN第二篇:李沐动手学深度学习V2-NLP文本预处理和代码实现
循环神经网络RNN第三篇:李沐动手学深度学习V2-NLP语言模型、数据集加载和数据迭代器实现以及代码实现
循环神经网络RNN第四篇:李沐动手学深度学习V2-RNN原理
循环神经网络RNN第五篇:李沐动手学深度学习V2-RNN循环神经网络从零实现
循环神经网络RNN第六篇:李沐动手学深度学习V2-使用Pytorch框架实现RNN循环神经网络
循环神经网络GRU第七篇:李沐动手学深度学习V2-GRU门控循环单元以及代码实现
循环神经网络LSTM第八篇:李沐动手学深度学习V2-LSTM长短期记忆网络以及代码实现
深度循环神经网络第九篇:李沐动手学深度学习V2-深度循环神经网络和代码实现
双向循环神经网络第十篇:李沐动手学深度学习V2-双向循环神经网络Bidirectional RNN和代码实现