MapReduce入门案例--单词计数
1.提前准备好单词

2.WordCount需求分析

3.新建工程并导入pom依赖 (pom.xml)
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>
3.创建日志文件(log4j.properties)
# 控制台输出配置
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %p [%c] - %m%n
# 指定日志的输出级别与输出端
log4j.rootLogger=debug,Console
4.创建Map类(WeMapper.java)
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WeMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text out_key=new Text();
IntWritable vul=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lines=value.toString();
String[] words=lines.split(" ");
for(String word:words){
out_key.set(word);
context.write(out_key,vul);
}
}
}
5.创建WeReduce类(WeReduce.java)
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WeReduce extends Reducer <Text, IntWritable,Text,IntWritable>{
IntWritable vul=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable value:values){
count+=value.get();
}
vul.set(count);
context.write(key,vul);
}
}
4.创建WeReduce类(WeReduce.java)
(这里是将数据传送至hdfs上)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WeDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://node-1:8020");
Job job=Job.getInstance(conf);
job.setJarByClass(WeDriver.class);
job.setMapperClass(WeMapper.class);
job.setReducerClass(WeReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path input=new Path(args[0]);
Path output=new Path(args[1]);
FileSystem fileSystem=output.getFileSystem(new Configuration());
if(fileSystem.exists(output)){
fileSystem.delete(output,true);
}
FileInputFormat.setInputPaths(job,input);
FileOutputFormat.setOutputPath(job,output);
boolean flag=job.waitForCompletion(true);
System.exit(flag?0:-1);
}
}
6.代码运行(并打包jar包)

将jar包重新命名为word.jar并防止虚拟机temp目录下

在hadoop上运行jar包
复制driver的reference

在Linux上temp上运行该jar 包(并指明输入输出路径)
hadoop jar word.jar com.xdd.mapreduce.WeDriver /wc/input/test.txt /wc/output/wordhadoop
看到successful即为成功

查看Hadoop上运行情况(word.jar包已经成功运行)

在hdfs上查看结果的输出情况(已生成对应文件)
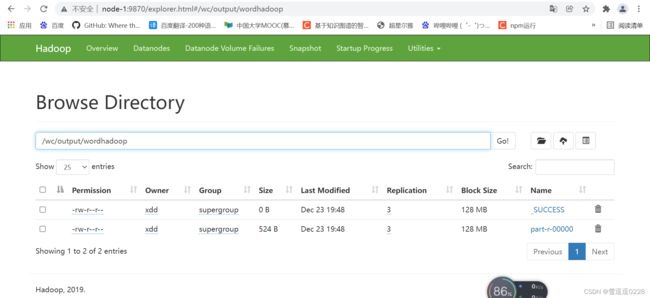
查看文件结果(统计成功)
