NLP小白入门项目——文本分类
赛题背景:
新闻文本分类
赛题数据:
训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。
分类的目标:
14个候选类别-财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐
(这14个标签,按照从0到13进行标注。以标签:数字的字典格式存储,如下)

衡量分类效果的工具:
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
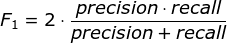
如何实现分类:
S1-特征提取:选择word2vec
word2vec下面有两个模型:Skip-gram模型和CBOW模型
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型』
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
S2-分类模型
Full-Connection and Softmax
具体操作:
S1-对给定数据集进行数据分析。
S1.1-分析赛题每篇新闻平均由多少个句子构成?
赛题中给出的前提条件是字符3750,字符900和字符648是句子的标点符号。我们知道标点包括"。",“;”等等。
理解-这三个字符都是句子结尾的符号,如“。”,“?”“!”
具体实现:因为split这个函数职能用单个分隔符对句子进行分隔,所以需要调用re模块,如下。
import re
data_train_sample['sent_len'] = data_train_sample['text'].apply(lambda x: len(re.split('3750|900|648',x)))
data_train_sample['sent_len'] .describe()按照这样分类的句子长度结果统计
| sent_len | |
|---|---|
| count | 10000 |
| mean | 80.46 |
| std | 87.87 |
| min | 1 |
| max | 2193 |
S1.2-统计每类新闻中出现次数对多的字符
from collections import Counter
#删除标点
data_train_sample['text'] = data_train_sample['text'].apply(lambda x:x.replace(' 900','').replace(' 648','').replace(' 3750',''))
for i in range(14):
data_class = data_train_sample[data_train_sample['label']==i]
all_lines = ' '.join(list(data_class['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print("类别",i,":",word_count[:5])类别 0 : [('3370', 25481), ('4464', 15569), ('2465', 15349), ('3659', 13282), ('6122', 12899)]
类别 1 : [('3370', 34024), ('4464', 26097), ('3659', 20980), ('5036', 18191), ('1633', 15428)]
类别 2 : [('7399', 17178), ('6122', 16874), ('4939', 16657), ('4704', 14966), ('1667', 14885)]
类别 3 : [('6122', 9514), ('4939', 8796), ('4893', 7509), ('669', 7501), ('7399', 7413)]
类别 4 : [('4411', 5931), ('7399', 4439), ('6122', 4042), ('4893', 3797), ('2400', 3406)]
类别 5 : [('6122', 8009), ('5598', 6901), ('4893', 6700), ('7399', 6081), ('3370', 5102)]
类别 6 : [('6248', 9687), ('2555', 9363), ('5620', 8210), ('2465', 7457), ('6122', 6063)]
类别 7 : [('3370', 8520), ('5296', 7448), ('6835', 6243), ('4464', 5993), ('3659', 4560)]
类别 8 : [('4939', 3071), ('6122', 2893), ('5560', 2633), ('913', 2349), ('7399', 2256)]
类别 9 : [('7328', 2168), ('6122', 2042), ('2465', 1915), ('3370', 1828), ('5547', 1726)]
类别 10 : [('3370', 3479), ('2465', 2112), ('4464', 2107), ('5560', 2068), ('3523', 1850)]
类别 11 : [('5560', 1050), ('4939', 1035), ('669', 946), ('6122', 931), ('4811', 773)]
类别 12 : [('4464', 2787), ('3370', 2636), ('3659', 1905), ('2465', 1847), ('6065', 1679)]
类别 13 : [('4939', 293), ('6122', 277), ('669', 261), ('4893', 256), ('3800', 204)]参考文献:
[NLP] 秒懂词向量Word2vec的本质 - 穆文的文章 - 知乎 https://zhuanlan.zhihu.com/p/26306795
https://blog.csdn.net/sinat_20829389/article/details/107524767
https://www.cnblogs.com/waws1314/p/13366273.html