【零基础玩转yolov5】yolov5训练自己的数据集(最新最全版)
文章目录
-
- 一、写在前面
- 二、使用labelimg标记图片
-
- 1.准备工作
- 2.标记图片
- 三、 划分数据集以及配置文件修改
-
- 1. 划分训练集、验证集、测试集
- 2.XML格式转yolo_txt格式
- 3.配置文件
- 4.聚类获得先验框
- 四、使用CPU训练
- 五、使用GPU训练
-
- 1.开始训练
- 2.重新下载pytorch
- 六、训练结果可视化
一、写在前面
博主也是最近开始玩yolov5的,甚至也是最近开始使用python的,很多东西都没有接触过,因此训练自己的数据集花了不少时间,所以想写篇博客记录一下,希望同样是零基础的小伙伴们可以更加轻松的上手。同时大家如果发现了错误和理解偏差,欢迎指正。
参考资料:
- Yolov5训练自己的数据集(详细完整版)
- 训练集、验证集、测试集的划分
- yolov5 训练结果解析
- 关于yolov5的一些说明(txt文件、训练结果分析等)
本教程所安装版本:
- pycahrm:2021.3.3
- Anconda:2022.05
- python:3.9
- yolov5:v6.2
- pytorch:CUDA 11.6
踩坑经历:
- 路径中就不要有
短横杠-以及空格等等特殊字符,中文更不能要有❗。否则在之后训练时会出现各种路径找不到的问题 - 使用pip等下载指令时最好不要挂VPN,否则可能会下载失败
在上一篇博客里 博客链接,我们完成了yolov5的安装和相关环境的配置,在这篇博客里,我们继续yolov5的学习,尝试训练自己的数据集
二、使用labelimg标记图片
1.准备工作
- 在yolov5目录下新建一个名为
VOCData的文件夹
- 在VOCData文件夹下创建
Annotations和images文件夹(【易错】:images的文件名不建议修改,否则之后训练时容易出现labels no found的错误)

[说明]:
Annotations文件夹用于存放使用labelimg标记后的图片(XML格式)images文件夹用于存放用于标记的图片
[为什么]:
在 yolov5 的 utils 文件夹打开 dataloaders.py文件后,搜索define,便可以找到这样的一段代码:

该段代码的作用是由images文件夹的地址直接推出labels文件夹的位置,所以我们存储图片的文件必须叫做images,同时labels文件必须和images文件必须在同一目录下(先不管labels具体是什么,有个基本的概念即可,接下来会细说)
2.标记图片
-
在cmd窗口下输入
labelimg或者运行labelimg.py文件进入labelimg的可执行程序(注:如果是在虚拟环境下安装的labelimg,记得先激活虚拟环境) -
分别设置需要标注图片的文件夹和存放标记结果的文件夹的地址

-
推荐设置自动保存

-
标记图片快捷键:
w:标记a:上一张图片d:下一张图片

标注的时候尽可能贴近物体轮廓
不知道有没有和我一样开始只能标记方形框的,按住ctrl+shift+R就可以恢复创建矩形框
在Annotations文件夹下可以看到我们标记好的XML文件
三、 划分数据集以及配置文件修改
1. 划分训练集、验证集、测试集
在VOCData目录下创建程序 split_train_val.py 并运行以下代码。代码可以不做任何修改
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行结束后会在生成一个名为 ImageSets 的文件夹:

测试集里的内容为空,因为在划分数据的时候,将90%的数据划分到训练集,将10%的数据划分到训练集。如果要分配,则调整上面14,15行代码中trainval和train的所占的比例
[说明]:
- 训练集是用来训练模型的,通过尝试不同的方法和思路使用训练集来训练不同的模型
- 验证集使用交叉验证来挑选最优的模型,通过不断的迭代来改善模型在验证集上的性能
- 测试集用来评估模型的性能
2.XML格式转yolo_txt格式
在VOCData目录下创建程序 xml_to_yolo.py 并运行以下代码,注意:
- 将classes改为自己标注时设置的类名(我这里叫"DM")
- 将各个绝对路径修改为自己的
\是 python中的转义字符,所以表示地址时要使用\\取消转义,或者/
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["DM"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/yolov5/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/yolov5/VOCData/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/yolov5/VOCData/labels/'):
os.makedirs('D:/yolov5/VOCData/labels/')
image_ids = open('D:/yolov5/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('D:/yolov5/VOCData/dataSet_path/'):
os.makedirs('D:/yolov5/VOCData/dataSet_path/')
list_file = open('dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('D:/yolov5/VOCData/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
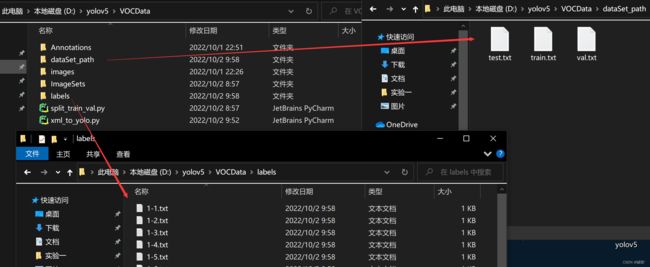
运行后会生成如下图所示的 dataSet_path 和 labels 文件夹。dataSet_path下会有三个数据集的txt文件,labels下存放各个图像的标注文件
3.配置文件
在 yolov5 的 data 文件夹下创建一个名为 myvoc.yaml,模板如下,根据自己实际情况填写:
train: D:/yolov5/VOCData/dataSet_path/train.txt
val: D:/yolov5/VOCData/dataSet_path/val.txt
# number of classes
nc: 1
# class names
names: ["DM"]

4.聚类获得先验框
- 获取anchors
较高版本的yolov5都可以在utils文件夹下找到autoanchor.py文件,它的作用是自动获取anchors,因此我们不需要额外的操作。
- 在
models文件夹下找到yolov5s.yaml(如果使用这个权重模型训练的话),将其中的nc改为实际上标注类的数量,和 myvoc.yaml 一样(记得保存)。

四、使用CPU训练
在cmd窗口下激活相应虚拟环境后 cd 到 yolov5 文件夹后,输入下列指令即可开始训练
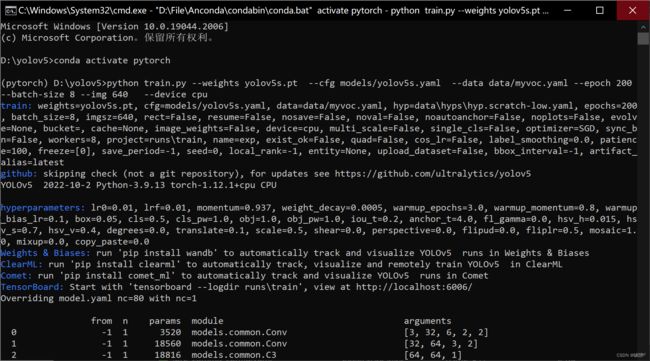
python train.py --weights yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 200 --batch-size 8 --img 640 --device cpu
[参数说明]:
--weights:权重文件所在的相对路径--cfg:存储模型结构配置文件的相对路径--data:存储训练、测试数据的文件的相对路径--epoch:训练过程中整个数据集将被迭代(训练)了多少次--batch-size:训练完多少张图片才进行权重更新--img:img-size--device:选择用CPU或者GPU训练
(开始训练)
五、使用GPU训练
1.开始训练
CPU适合处理少量复杂运算,GPU适合处理大量简单运算。相较于 CPU,GPU 在具备大量重复数据集运算和频繁内存访问等特点的应用场景中具有无可比拟的优势,在运行分析、深度学习和机器学习算法尤其有用。
GPU 能够让某些计算比传统 CPU 上运行相同的计算速度快 10 倍至 100 倍。所以更加推荐使用GPU进行训练。
使用GPU训练,只需将代码中的--device cpu改为--device 0/1…… 即可,具体显卡编号可以在任务管理器的性能中看到。
易错①:如果运行时出现 CUDA out of memory的错误,将 batch_size 改到4基本能解决问题

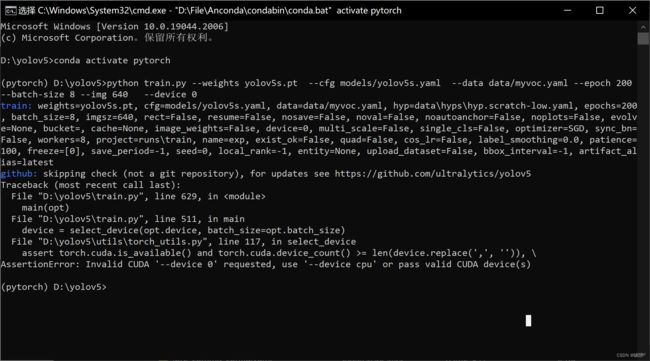
易错:yolov5 是基于 pytorch 实现的,而使用 pip 默认安装的 pytorch 是以CPU作为计算平台,因此当然CUDA是不可用的,需要重新下载基于 CUDA 计算的pytorch
2.重新下载pytorch
pytorch文件比较大,建议下载的时候首先给 pip 换源
- Pytorch官方下载链接 :https://pytorch.org/get-started/locally/

-
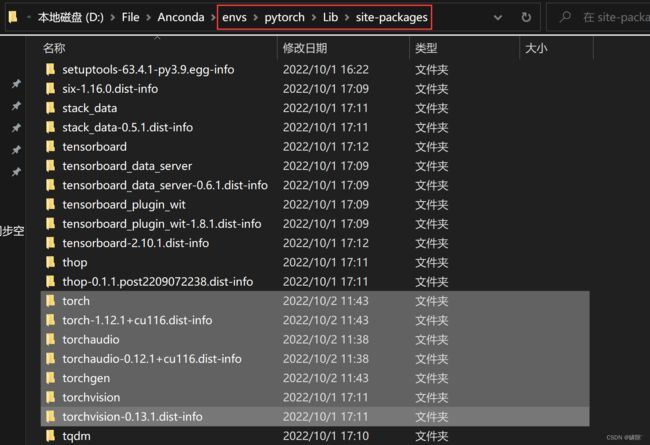
首先在相应虚拟环境下删除原先版本的pytorch,仅仅使用
pip uninstall torch是不够的,因此重新下载 torch 后可能存在版本不兼容问题。找到自己Anconda中相应虚拟环境的位置,将这些文件全部删除
-
使用
nvidia -smi查看最高能下载的 pytorch CUDA版本,我这里是11.6

-
强烈推荐使用
pip安装而不要使用conda安装,conda安装太慢了,换源还是很慢,而且还很容易失败 pip install 与 conda install 的使用区别 -
切换到相应虚拟环境中,运行 “Run this Command:” 提示的 pip 代码安装

-
检测cuda是否可用:
torch.cuda.is_available(),返回true说明可以使用。接下来我们就可以使用GPU进行训练

六、训练结果可视化
训练结果将保存在 \runs\train 文件夹下,部分文件意义如下:
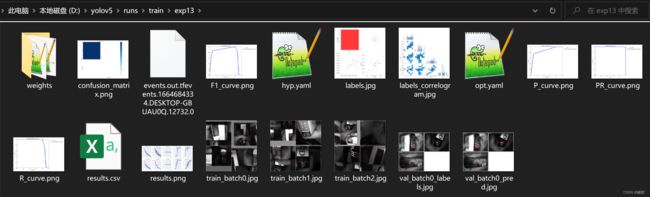
- weights:训练生成权重。包含
best.pt(最好的权重,detect时用到它),和last.pt(最近生成的权重模型) - confusion:混淆矩阵。混淆矩阵让我们了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。
- F1_curve:置信度和F1分数的关系图
- P_curve:准确率和置信度的关系图
- R_curve:召回率和置信度之间的关系
- PR_curve:PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系
- labels:左上图表示个类别的数据量;右上图表示标签;左下图表示 center 的 xy 坐标;右下图表示各个标签的长和宽
训练时或者训练后,输入tensorboard --logdir=runs,即可利用 tensorboard 实现训练结果可视化

访问网页 http://localhost:6006/即可看到各种训练结果(注:localhost指的是你所在的计算机本身)

使用刚刚训练好的 best.pt模型来检测:
python detect.py --weights runs/train/exp/weights/best.pt --source ../source/test.png
[说明]:
--weights:表示我们选择的权重模型--source:表示待检测的图片的路径 (…/表示上级路径)
成功实现了恶劣环境下的DM码的定位
